一、服务部署与迁移的步骤
1.1 将应用封装进容器
应用容器化是部署与迁移的第一步,需要设计并规划好镜像的构建方案,由于Docker镜像分层的特性,通常建议使用分层方式进行Docker镜像构建。
操作系统层:制作公司常用的系统版本如CentOS、Ubuntu,可以在官方镜像的基础上添加自己需要的软件包。
运行环境层:在已经构建的操作系统层的基础上,把业务常用的运行环境都打包好,如JDK7、JDK8、JDK8+Tomcat8、Python2、Python3等通用模板。
应用层:在已经构建好了通用运行环境的基础上,根据应用再进行调整,然后将代码放进去即可。
1.2 将容器放入Pod中
应用容器化后,就需要考虑如何在Pod中运行,因为Pod是Kubernetes管理的最小单元,Kubernetes不直接管理容器,而是管理Pod,Pod里面包含容器。需要考虑是一个Pod中放置多个容器,还是一个Pod中放置一个容器,同时需要考虑Pod的资源限制,健康检查,数据持久化等。
1.3 使用Controllers管理Pod
单一Pod如果出现故障,就会影响业务连续性,所以需要多副本,就像我们给一个Web应用做集群是一样的。Kubernetes提供了不同的Controller,需要根据应用的实际情况选择使用Deployment、DaemonSet、StatefulSet、Job、CronJob等,只需要在Pod的YAML模板上封装上对应的配置即可。
Deployment:封装了Pod的副本管理、部署更新、回滚、扩容、缩容等。
DaemonSet:保证所有的Node上有且只有一个Pod在运行。
StatefulSet:有状态的应用,为Pod提供唯一的标识,它可以保证部署和scale的顺序。
Job:使用Kubernetes运行单一任务。
CronJob:使用Kubernetes运行定时任务。
1.4 使用Service管理Pod访问
使用Deployment通过多副本的方式保证了Pod的高可用和横向扩展,那么就需要考虑负载均衡,Kubernetes Service就是实现此功能,为应用创建对应的Service。目前Service的负载均衡支持两种实现方式:iptable 和 ipvs。
1.5 使用Ingress提供外部访问
集群内部可以直接使用Service Name进行通信,因为在集群中定义的每个 Service,都会被指派一个 DNS 名称,外部要访问到Kubernetes集群,由于网络路由不通(也可以使用其它手段打通),可以通过Node Port、LoadBlancer、外部IP等对外暴露访问。不过这些都可以理解为4层的负载均衡,如果要实现7层的负载均衡,Kubernetes提供了Ingress。
在Kubernetes中由Ingress Controller来实现Ingress的功能,这个控制器比较特殊,因为其它的控制器基本上都是kube-controller-manager这个服务的一部分,而Ingress Controller确是独立的。
1.6 使用PV/PVC管理持久化数据
容器中的存储都是临时的,因此Pod重启的时候,内部的数据会发生丢失。实际应用中,我们有些应用是无状态,有些应用则需要保持状态数据,确保Pod重启之后能够读取到之前的状态数据,有些应用则作为集群提供服务。这三种服务归纳为无状态服务、有状态服务以及有状态的集群服务,其中后面两个存在数据保存与共享的需求,因此就要采用容器外的存储方案。
1.7 使用ConfigMap管理应用配置文件
在DevOps的部署流水线中,我们强调代码和配置的分离,这样更容易实现流水线的编排。在Kubernetes中提供了ConfigMap资源对象,其实ConfigMap和Secret都是一种卷类型,可以从文件、文件夹等途径创建ConfigMap。然后再Pod中挂载使用。
二、k8s业务迁移与服务部署实践
2.1 K8s运行业务的优势
2.1.1 部署上线业务流程

业务部署上线是每个运维都需要面对的问题,接下来分别从传统运维和k8s运维角度,梳理操作流程:
传统运维:
- 安装操作系统
- 初始化系统配置(安全策略、时间同步、yum源……)
- 安装配置java环境
- 打jar包并部署服务
- Systemctl添加自定义服务或supervisor进程守护
k8s运维:
- 安装操作系统
- 初始化系统配置(安全策略、时间同步、yum源……)
- 部署k8s集群(多台机器)
- 封装docker镜像
- 创建资源清单,完成项目部署
分析:
两者都需要安装操作系统,初始化系统。 不同之处在于传统运维只需要单机配置环境部署服务即可。而k8s运维则需要部署搭建一个k8s集群,然后封装docker镜像,创建k8s的资源清单,才能完成项目的部署。相比较而言,k8s方式部署业务,前期从时间成本,资源使用考虑都是高于传统方式部署业务的。
2.1.2 故障处理转移流程

业务上线初期,通常访问量很小,大多数情况都是单节点运行业务,那么如果出现硬件故障,例如磁盘坏盘,导致系统死机,用户无法访问业务服务。那么我们应该如何处理呢?
传统运维:
- 安装操作系统
- 初始化系统配置
- 安装配置java环境
- 打jar包并部署服务
- Systemctl添加自定义服务或supervisor进程守护
- 修改DNS解析,指向新的服务器地址
k8s运维:
- K8s检测到节点故障后,自动进行故障转移,将故障机器上的服务自动迁移至其他正常机器上运行
分析:
如果是传统运维的话,服务器硬件故障可能一时半会不能修复,为了尽可能缩短业务中断时间,降低经济损失,只能快速再起一台服务器,再重复执行一遍业务上线的流程,最后修改DNS解析,或者修改公网ip,把流量引入新的机器中,恢复故障。 而如果是k8s运维的话,因为前期在部署上线时,已经搭建了k8s集群,当集群内有一个节点故障后,k8s发现节点宕机后,会将异常节点上的pod都变为unknow状态,并自动在其他机器上开启指定数量的副本pod。整个故障迁移过程中,运维人员不需要参与,用户也不会感知到服务异常,更不会对业务造成中断。
2.1.2 业务扩容流程

随着业务的不断发展,为了提高服务性能、避免单点故障,需要进行由单体服务向集群转变的操作。
传统运维:
- 安装操作系统
- 初始化系统配置
- 安装配置java环境
- 打jar包并部署服务
- Systemctl添加自定义服务或supervisor进程守护
- 部署nginx、lvs或者haproxy等服务,实现负载均衡
k8s运维:
- 修改资源清单文件,将副本数从1改为N,由service自动进行负载均衡。
分析:
如果是传统运维,那就再执行几遍业务上线流程,如果机器过多,可以使用ansible等批量工具编写playbook执行,最后部署一个lvs 或者nginx 或者haproxy等反向代理软件,实现负载均衡,但过程中集群机器尽可能使用一样的操作系统和环境。 而如果是一个k8s运维,那么他需要做的操作,只是将副本数从1改为N即可,不需要关注如何实现负载均衡,因为k8s通过service已经实现了负载均衡。而且,面对一些瞬时暴增的流量,k8s可以通过HPA自动扩缩容,非常适合于一些流量波动大,机器资源吃紧,服务数量多的业务场景。
2.1.3 版本更新发布流程

传统运维:
- 拉取最新代码并打jar包
- 修改负载均衡配置,剔除将要更新的机器
- 停止服务,替换jar包文件
- 启动服务,访问测试
- 修改负载均衡配置,恢复更新完成的机器
- 重复上述步骤,直至全部机器完成
k8s运维:
- 拉取最新代码,封装docker镜像,推送至镜像仓库
- 修改资源清单文件的镜像配置,执行apply操作,完成滚动更新。
分析:
以java项目为例,当打完jar包后,传统运维的话,因为整个业务是集群方式运行,所以首先就从负载均衡服务中,剔除那个将要更新的机器,防止流量进入。然后逐个更新,期间不停修改负载均衡服务后端地址列表。 而如果是k8s运维的话,只需要将最新jar包打包成一个新版本的业务docker镜像,然后修改资源清单文件的镜像版本即可,使用deployment控制器会自动完成滚动更新,实现零停机发布。
2.2 运维成本分析对比
| 传统运维 | K8s运维 | |
|---|---|---|
| 部署上线 | 配置环境,打包部署服务配置服务管理脚本 | 搭建集群、封装镜像、创建资源 |
| 健康检查 | 编写shell脚本或使用守护进程工具 | k8s提供就绪、存活探针,支持exec执行命令、HTTP状态码、TCP端口探测 |
| 故障转移 | 新机器部署服务,修改DNS解析指向新机器 | K8s内部自动实现故障转移 |
| 集群扩容 | 新机器部署服务,部署负载均衡服务,配置后端地址 | 修改k8spod资源副本数,service自动实现负载均衡 |
| 版本更新 | 修改负载均衡配置,逐个滚动停止服务,替换jar包,启动服务 | 更新docker镜像并上传,修改k8spod资源镜像信息,k8s自动实现滚动更新 |
以上五个运维场景相信也是大家在日常工作中会经常用到的,两种运维方式相比较而言,k8s只是在项目初期需要投入更多的时间和精力,但是当业务稳定运行后,k8s可以大大的简化运维的工作内容,是一种一劳永逸,更加优雅的运维方式。
三、应用迁移基本流程
3.1 将应用封装进容器
将应用迁移到k8s,首先第一步就是要编写dockerfile,将原本在Linux服务器上运行的服务打包到容器中运行。我们回想传统方式部署业务的整体流程,我们一般是从最底层开始选择合适版本的操作系统,配置一系列的初始化操作,配置安全策略等。然后再部署运行环境,配置环境变量,最后上传项目代码到服务器中,配置启动脚本或者守护进程。在整个过程中,我们所有的操作分为了三个层面,最底层的操作系统,中间层的运行环境,上层的应用服务。
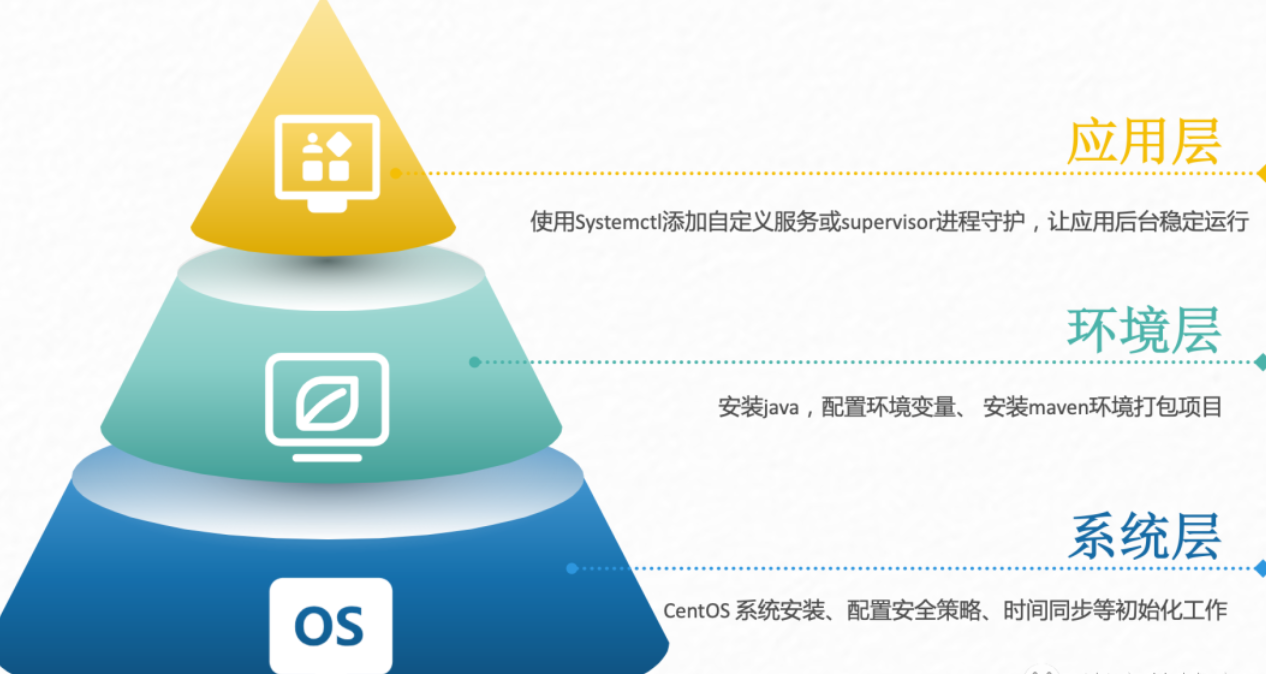
而编写dockerfile时,base镜像的选择也是从这几个层面考虑,如果环境层的镜像无法满足需求,就从系统层开始编写dockerfile。
案例1:

我们也已经明确知道了这个项目运行的系统和环境,也就是前面提到的三层中的系统层和环境层是已经确定的,使用docker镜像仓库中提供的基础镜像就可以满足我们的要求,我们只需要在应用层上将自己的代码加入镜像即可 。
FROM openjdk:19-jdk-alpine3.16 # 使用alpine3.16操作系统,java19运行环境为基础镜像
ADD demo.jar /opt/app.jar # 复制项目jar包文件到容器/opt/目录下
EXPOSE 8888 # 声明容器暴露的端口
WORKDIR /opt # 指定容器工作目录
CMD ["java","-jar","app.jar"] # 指定启动命令为java –jar /app.jar
案例2:

在这个场景中,我们需要两个环境,一个是编译打包环境需要nodejs,一个是运行环境需要nginx。此时我们就需要用到多阶段构建,将打包阶段中的文件拷贝到后边的运行阶段中,实现编译环境和运行环境分离。
FROM node:16.15.0 AS build # 使用node 16.15运行环境 用于打包项目,并将第一阶段命名为build
COPY . /vue # 复制项目代码到/vue目录下
WORKDIR /vue # 设置工作目录为/vue
RUN npm install && npm run build # 安装项目依赖并打包项目
FROM nginx:1.20.1 # 使用nginx 1.20运行环境为基础镜像
COPY --from=build /vue/dist /opt/vue/dist # 拷贝build阶段生成的打包文件dist到容器目录下
EXPOSE 80 # 声明容器暴露的端口
COPY vue.conf /etc/nginx/nginx.d/vue.conf # 拷贝nginx配置文件到容器nginx配置文件目录下
CMD ["nginx", "-g","daemon off;"] # 指定启动命令
案例3:

前两个案例中,我们都是使用默认的系统和环境,就可以实现我们的需求,我们只需要自定义应用层的东西即可。但如果碰到这样的需求,也就是说直接使用Python这个环境层的镜像无法满足要求了,因为他不支持yum命令安装sshd服务,直接拷贝ssh的二进制文件编译安装也非常麻烦,那我们就只能使用最基础的系统层镜像,然后自定义Python环境,完成镜像封装。
FROM centos:centos8 # 选取centos8为基础镜像
RUN dnf install openssh-server passwd python38 python38-devel -y # 安装相关软件包
RUN /bin/echo "123.com" | passwd --stdin root # 设置ssh密码
RUN /bin/sed -i 's/.session.required.pam_loginuid.so./session optional pam_loginuid.so/g' /etc/pam.d/sshd && /bin/sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config && /bin/sed -i "s/#UsePrivilegeSeparation.*/UsePrivilegeSeparation no/g" /etc/ssh/sshd_config # 修改sshd配置文件
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key && ssh-keygen -t rsa -f /etc/ssh/ssh_host_ecdsa_key && ssh-keygen -t rsa -f /etc/ssh/ssh_host_ed25519_key # 创建密钥
RUN echo -e "#! /bin/bash\n/usr/sbin/sshd -D" > /run.sh # 创建sshd服务启动脚本
ADD . /app # 拷贝代码到容器目录
RUN pip3.8 install -r /app/requirements.txt # 安装依赖
EXPOSE 22 # 声明容器暴露的端口
CMD ["/usr/sbin/sshd","-D"] # 指定启动命令
dockerfile构建镜像经验
- 减少镜像的层数,尽量把一些功能上面统一的命令合到一起来做;
- 注意清理镜像构建的中间产物,比如一些安装包在装完之后就把它删掉;
- 注意优化网络请求,使用yum源的时候,用一些网络比较好的源站点,可节约时间,减少失败率;
- 尽量去使用缓存构建,尽量把一些不变的东西或者变动比较少的东西放在前面。例如业务更新,打包新版本镜像时,只有代码发生变化,其他内容不变。此时可以把拷贝代码放最后,前面的构建阶段直接使用缓存即可。
3.2 将容器放入Pod中
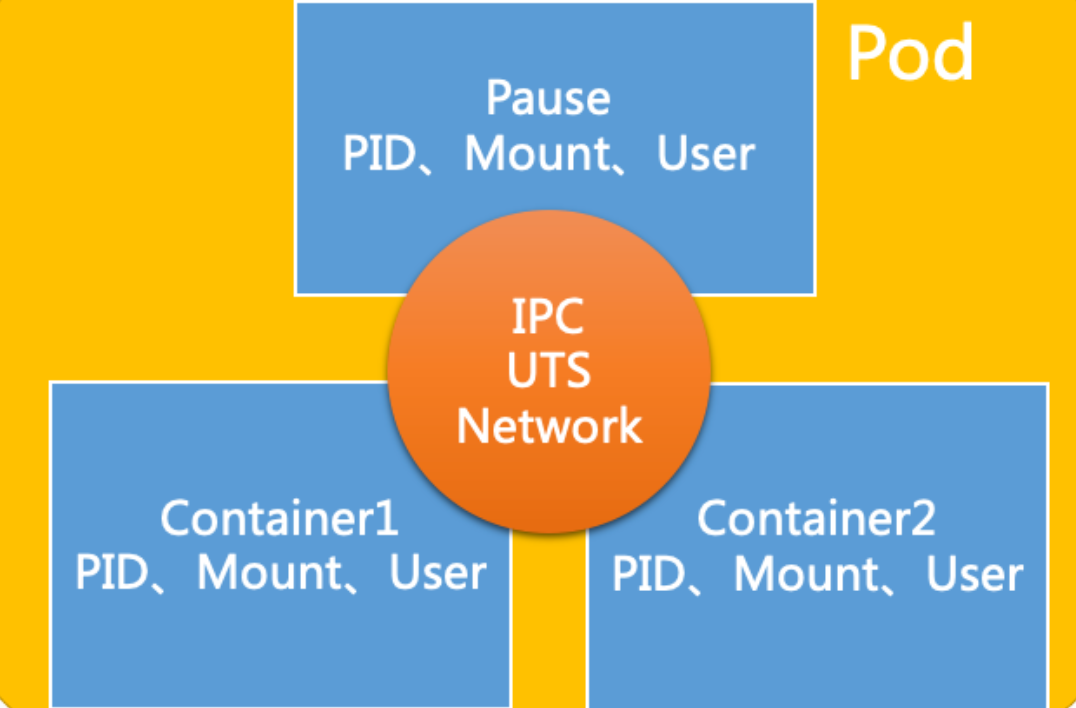
当我们把应用封装成docker镜像后,接下来就是在kubernetes中启动镜像运行容器。因为Pod是Kubernetes管理的最小单元,Kubernetes不直接管理容器,而是管理Pod,Pod里面包含一个或多个容器。需要考虑是一个Pod中放置多个容器,还是一个Pod中放置一个容器。在一个pod中所有container共享,PID、Network、IPC
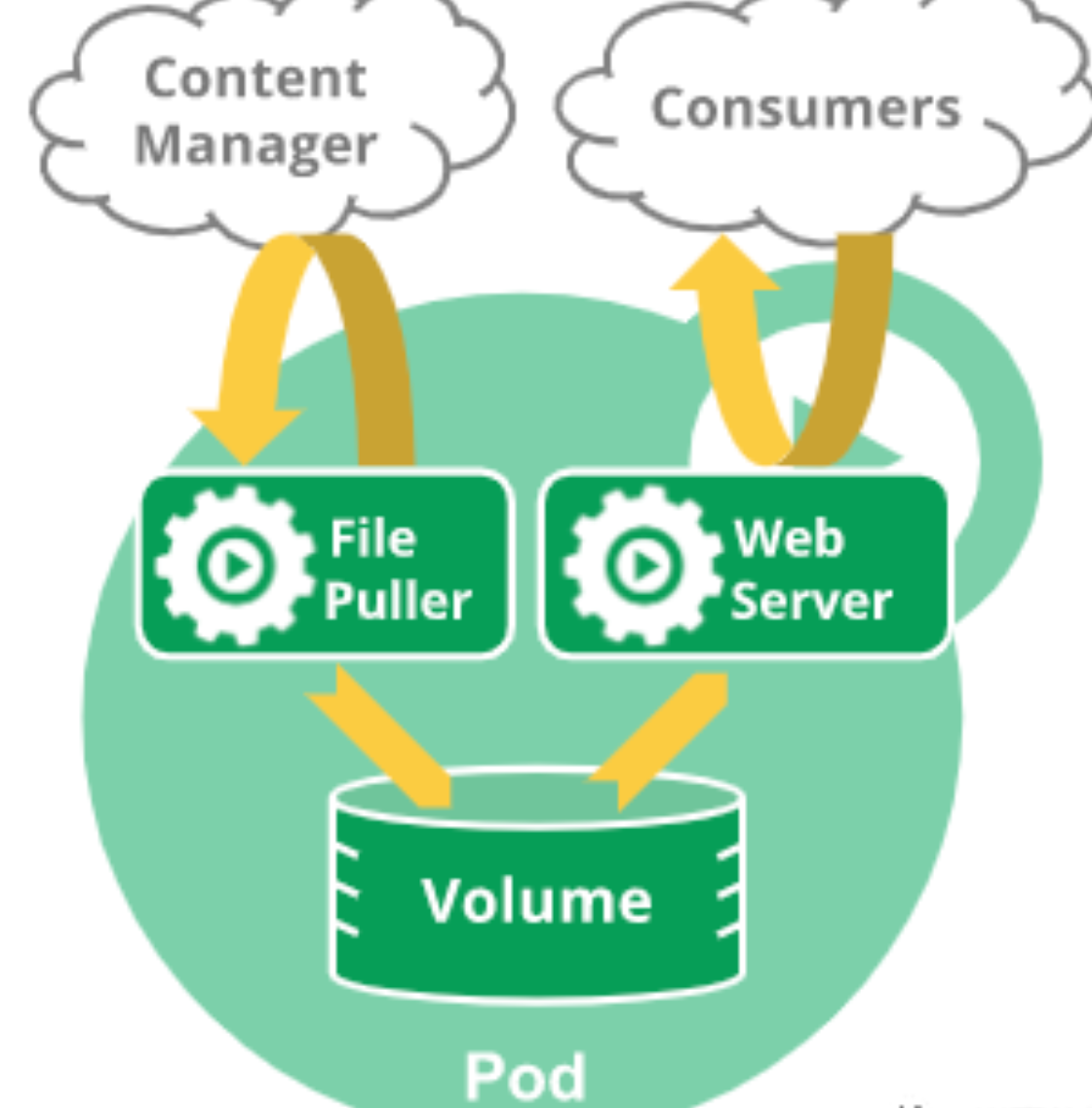
在有些业务场景中,例如一个web服务,对应的资源文件需要从远端实时监听更新,就需要使用边车 (sidercar)模式,一个pod中包含一个web容器一个file容器,通过共享存储方式实现。又比如一个用户的微服务包含:User API、User Control、User Data等三个模块,彼此之间紧耦合,对外只需要通过User API,这样类型的应用就可以放置在一个Pod中。
Pod资源清单建议
- 建议开发项目时,提供healthy健康检查接口,便于检测服务是否正常。
- 建议运维配置LivenessProbe存活检测探针,防止服务假死。
- 建议配置resources,避免程序出现异常,并占用大量的系统资源,从而会影响节点上其他的Pod。
3.3 使用Controller管理Pod
单一Pod如果出现故障,就会影响业务连续性,所以需要多副本,就像我们给一个Web应用做集群是一样的。Kubernetes提供了不同的Controller,需要根据应用的实际情况选择使用Deployment、DaemonSet、StatefulSet、Job、CronJob等,只需要在Pod的YAML模板上封装上对应的配置即可。

kubernetes提供的控制器如下:
- Deployment:封装了Pod的副本管理、部署更新、回滚、扩容、缩容等。
- DaemonSet:保证所有的Node上有且只有一个Pod在运行。
- StatefulSet:有状态的应用,为Pod提供唯一的标识,它可以保证部署和scale的顺序。
- Job:使用Kubernetes运行单一任务。
- CronJob:使用Kubernetes运行定时任务。
3.4 使用Service访问Pod
由于每次pod重启都会随机生成新的ip,且使用控制器运行多副本pod时,该访问哪个具体的IP呢?
在传统的方式运行服务时,通常会提供一个VIP和service后端地址池。其中VIP负责对外暴露服务,监听请求。后端地址池复制监听后端服务的变化,随时更新地址池,并通过控制器实现轮循哈希等负载均衡方式。
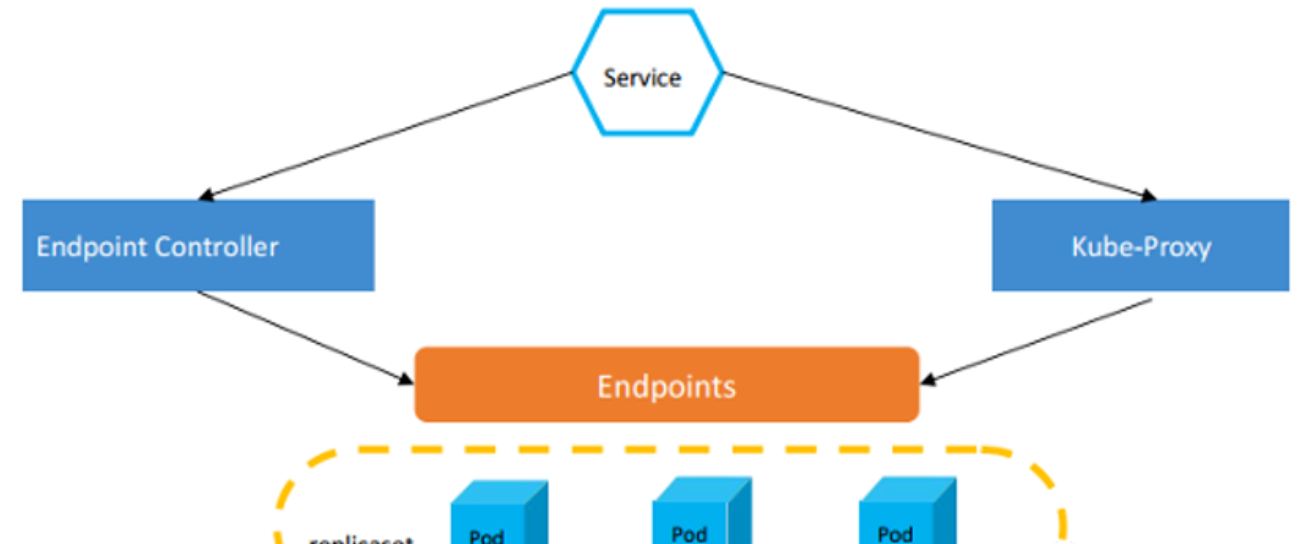
在kubernetes中,service便是这样的存在,service只是一个抽象的概念,他的工作主要由endpoint controller和kube-proxy搭配完成。 endpoints controller 是负责生成和维护所有 endpoints 对象的控制器,监听 service 和对应 pod 的变化,更新对应 service 的 endpoints 对象。
当用户创建 service 后 endpoints controller 会监听 pod 的状态,当 pod 处于 running 且准备就绪时,endpoints controller 会将 pod ip记录到 endpoints 对象中,因此,service 的容器发现是通过 endpoints 来实现的。
而 kube-proxy 会监听 service 和 endpoints 的更新并调用其代理模块在主机上刷新路由转发规则。实际的路由转发都是由 kube-proxy 组件来实现的。
目前Service的负载均衡支持多种实现方式:User Space、iptable和ipvs。如果使用ipvs,当你创建Service的时候,kube-proxy会获取Service对应的Endpoint,调用LVS帮我们实现负载均衡的功能。
k8s同样也为我们提供了多种service使用:
-
ClusterIP(集群IP):集群内的服务间通信。 例如,应用程序的前端(front-end)和后端(back-end)组件之间的通信。
-
NodePort(节点端口):k8s集群内部服务暴露给外部时访问,可以通过k8s节点ip+端口方式访问服务。
- LoadBalancer(负载均衡器):使用云厂商来托管您的 Kubernetes 集群时。由它接入外部客户端的请求并调度至集群节点相应的NodePort之上
- ExternalName(外部名称):在 Kubernetes 内创建服务来表示映射外部服务名称,例如在 Kubernetes 中使用公有云数据库时,可以创建一个ExternalName资源,后续更换云数据库地址时,更新ExternalName配置即可。
3.5 使用Ingress提供外部访问
虽然用户可以通过service提供的nodeport方式或者loadbalancer方式访问k8s集群内部的服务,但是随着服务的增多,让普通用户通过ip+端口方式访问服务是不现实的。此时就需要通过不同的域名对应访问不同的服务,而这种全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的 Ingress 服务。
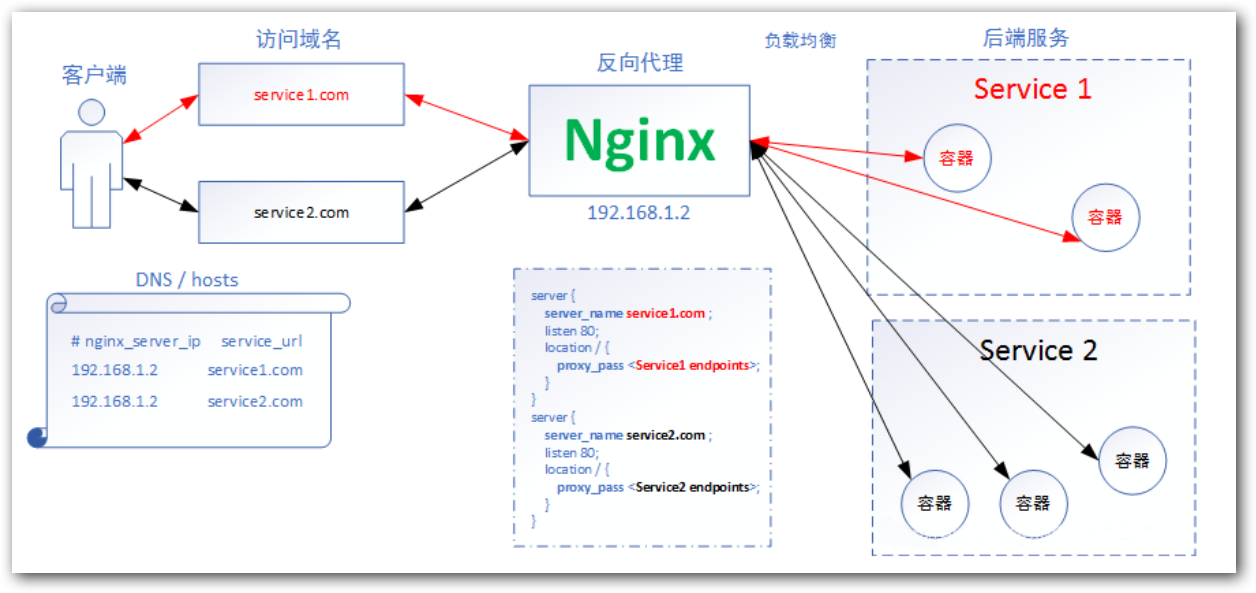
Ingress同样也只是一个概念,它的具体的实现依赖控制器,Ingress控制器并不直接运行为kube-controller-manager的一部分,它是Kubernetes集群的一个重要附件,类似于CoreDNS,需要在集群上单独部署。Ingress控制器可以由任何具有反向代理(HTTP/HTTPS)功能的服务程序实现,如Nginx、Envoy、HAProxy、Vulcand和Traefik等。
3.6 使用ConfigMap管理配置文件
在DevOps的部署流水线中,其中有一个核心的理念就是代码和配置的分离,这样更容易实现流水线的编排。我们只需要使用一套代码,配合不同的配置文件,就可以实现灵活发布到测试环境、预发布环境、生产环境等。

kubernetes同样也为我们提供了配置与文件管理方案:
- ConfigMap配置文件:可以从文件、文件夹等途径创建ConfigMap。然后再Pod中挂载使用配置文件,例如nginx配置。
- secret私密文件:使用base64加密的文件,例如存储第三方镜像仓库凭证 配置TLS 类型secret 用于记录证书秘钥等信息。
3.7 使用共享存储持久化存储数据
容器中的存储都是临时的,因此Pod重启的时候,内部的数据会发生丢失。实际应用中,我们有些应用是无状态,有些应用则需要保持状态数据,确保Pod重启之后能够读取到之前的状态数据,有些应用则作为集群提供服务。这三种服务归纳为无状态服务、有状态服务以及有状态的集群服务,其中后面两个存在数据保存与共享的需求,因此就要采用容器外的存储方案。
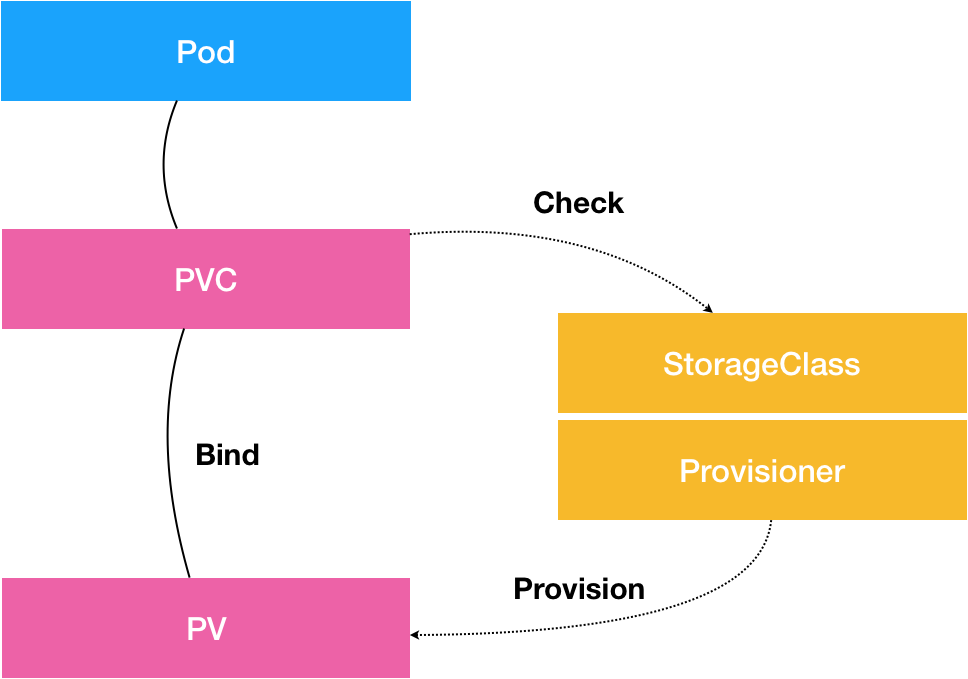
kubernetes拥有众多类型的用于适配专用存储系统的网络存储卷。这类存储卷包括传统的NAS或SAN设备(如NFS、iSCSI、fc)、分布式存储(如GlusterFS、RBD)、云端存储(如gcePersistentDisk、azureDisk、cinder和awsElasticBlockStore)以及建构在各类存储系统之上的抽象管理层(如flocker、portworxVolume和vsphereVolume)等。