SQL简介
SQL ( Structured Query Language,结构化查询语言)是使用关系模型的数据库应用语言,与数据直接打交道,由IBM上世纪70年代开发出来。后由美国国家标准局(ANSI)开始着手制定SQL标准,先后有SQL-86,SQL-89 , SQL-92 , SQL-99 等标准。 SQL 有两个重要的标准,分别是SQL92和SQL99,它们分别代表了92年和99年颁布的SQL标准,我们今天使用的SQL语言依然遵循这些标准。不同的数据库生产厂商都支持SQL语句,但都有特有内容。
SQL分类(四类)
DDL (数据定义语言) (Data Definition Language) 对库和表进行操作
Create 创建、库和表
Drop 删除库和表的数据和结构
Alter 修改结构
DML (数据操纵语言) (Data Manipulation Language) 对表中的数据进行添加、修改、删除
Insert 添加、插入数据
Update 修改、更新数据
Delete 删除数据
DQL (数据查询语言) (Data Query Language) 对表中数据进行查询操作
Select 查询、选择
DCL (数据控制语言) (Data Control Language) 对数据库进行权限管理、用户管理、事务管理
Use 切换数据库
Grant 权限设置
Revoke 移除权限
DTL (事务控制语言) (Data Transaction Language)
Commit 事务提交
Rollback 回滚
DDL基础语句
数据定义语言
# 0.搭建MySQL环境
# 1.启动MySQL
## 开机启动MySQL
systemctl enable mysqld
## 当前启动MySQL
systemctl start mysqld
# 2.登录
mysql -uroot -p
### 输入密码(回车)
? -- 客户端的帮助
\c -- 结束未完成的命令
\s -- 获取服务端的状态Status
\! -- 在MySQL客户端中执行系统的命令
\q -- 退出MySQL客户端
# SQL的规范
## 1. 必须以“;”结尾
## 2. 不区分大小写。show databases; SHOW DATABASES; Show DataBases;
## 3. 规范关键字用大写字母。 库名、表名、字段名都用小写字母。 合理使用反引号
### 一个单词或缩写 单词多时使用下划线 time_zone_transition_type
# DDL 数据定义语言
create database 库名; -- 创建一个使用默认字符集的库
show databases; -- 查看所有的数据库
show create database 库名; -- 查看该库的创库语句
alter database school charset utf8; -- 修改数据库的字符集
create database 库名 charset utf8; -- 创建时指定字符集
drop database 库名; -- 删除库和库中所有的数据
# select 执行函数或运算
select now();
select version();
select 23 * 33;
# gbk utf8 utf8mb4 latin1
E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述[现实世界]

表的操作
# []表示可选
create table 表名(
列名1 类型 [约束条件],
列名2 类型 [约束条件],
...
列名n 类型 [约束条件]
)[表约束];
# 简单 student id(编号) name(名字) sex(性别) birthday(生日)
create database school charset utf8mb4;
use school;
create table student(
id int,
name varchar(20),
sex enum('男','女'), -- 枚举类型(单选)set 集合
birthday date -- YYYY-MM-DD
);
show tables;
+------------------+
| Tables_in_school |
+------------------+
| student |
+------------------+
desc student; -- 显示表的结构
+----------+-------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| sex | enum('男','女') | YES | | NULL | |
| birthday | date | YES | | NULL | |
+----------+-------------------+------+-----+---------+-------+
drop table student;
## 修改表结构
### 修改表名
alter table 原始表名 rename to 新的表名;
### 修改字段名和字段类型
> 修改列的属性:change,modify
alter table student change birthday b_day date;
alter table student change b_day b_day datetime;
### 添加新的字段
alter table student add phone char(11);
> 如果你需要指定新增字段的位置,关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)
alter table student add address varchar(64) after name;
### 删除已有的字段
alter table student drop phone;
DML(数据操纵语言)
## 添加数据
insert into 表名(列1,列2,....) values(值1,值2...);
insert into student(id,name,sex,b_day) value(1,'武大郎','男','2000-1-1');
insert into student(id,name,sex,b_day) value(2,'王小二','男','2002-2-2');
insert into student(id,name,sex,b_day) value(3,'张三','男','2003-3-3');
insert into student(id,name,sex,b_day) value(4,'李四','男','2004-4-4');
insert into student(id,name,sex,b_day) value(5,'武则天','女','2005-5-5');
insert into student(id,name,sex,b_day) value(6,'慈禧','女','2006-6-6');
## 查看数据 DQL(数据查询语言)
select * from student; -- 查看所有数据
select name,sex from student;
## 修改语句必须要加where条件,否则会更新所有行的数据。
update student set b_day='1999-9-9' where id=1;
## 删除数据必须要加where条件,否则会删除所有行的数据。
delete from student where id=6;
# mysql安全模式sql_safe_updates是为了防止我们在操作表时的误操作,把全表删除了或者更新了。
# 检查是否开启
mysql> show variables like 'sql_safe_updates';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| sql_safe_updates | OFF |
+------------------+-------+
# 开启安全模式
set sql_safe_updates = 1;
# 关闭安全模式
set sql_safe_updates = 0;
# 自动启动安全模式
vim /etc/my.cnf
# 在[mysqld]下配置一个
init-file=/usr/local/mysql/init-file.sql
vim /usr/local/mysql/init-file.sql
# 在sql脚本文件中添加下列语句
set global sql_safe_updates=1;
# 重启MySQL服务
systemctl restart mysqld
# 开启安全模式后的限制有哪些
1. update语句必须满足如下条件之一才能执行成功
1)使用where子句,并且where子句中列必须为索引列
2)使用limit
3)同时使用where子句和limit(此时where子句中列可以不是索引列)
2. delete语句必须满足如下条件之一才能执行成功
1)使用where子句,并且where子句中列必须为索引列
2)同时使用where子句和limit(此时where子句中列可以不是索引列)
数据类型
整数、浮点数、字符串、时间日期
1. 整数型
| 类型 | 字节 | 范围(有符号) | 范围(无符号) |
|---|---|---|---|
| TINYINT(m) | 1 | (-128,127) | (0,255) |
| SMALLINT(m) | 2 | (-32768,32767) | (0,65535) |
| MEDIUMINT(m) | 3 | (-8388608,8388607) | (0,16777215) |
| INT(m) | 4 | (-2147483 648,2147483647) | (0,4294967295) |
| BIGINT(m) | 8 | (-9223372036854775808,9223372036854775807) | (0,18446744073709551615) |
类型后面括号里的m指的是显示宽度,显示宽度与所能存储的数据范围无关,目前已知的是当设置了ZEROFILL(填充0)约束条件时,填充 0的 个数由m决定
2. 浮点数和定点数
| 类型 | 大小 | 用途 |
|---|---|---|
| FLOAT | 4字节 :小数位过多会自动四舍五入 | 单精度浮点数值 |
| DOUBLE | 8字节 | 双精度浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 小数值 |
3. 日期时间
| 类型 | 字节 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
4. 字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR(100) | 0-255字节 | 定长字符串,有可能浪费存储空间 |
| VARCHAR(100) | 0-65535 字节 | 变长字符串,节约空间,性能不如CHAR |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
第三方工具使用
Navicat (简单、收费)
phpMyAdmin (开源php写数据库管理系统web版)
workbench (官方、免费)
mycli (命令行工具)
yum -y install python3 python3-pip
pip3 install --upgrade pip
pip3 install mycli
mycli
# 000000
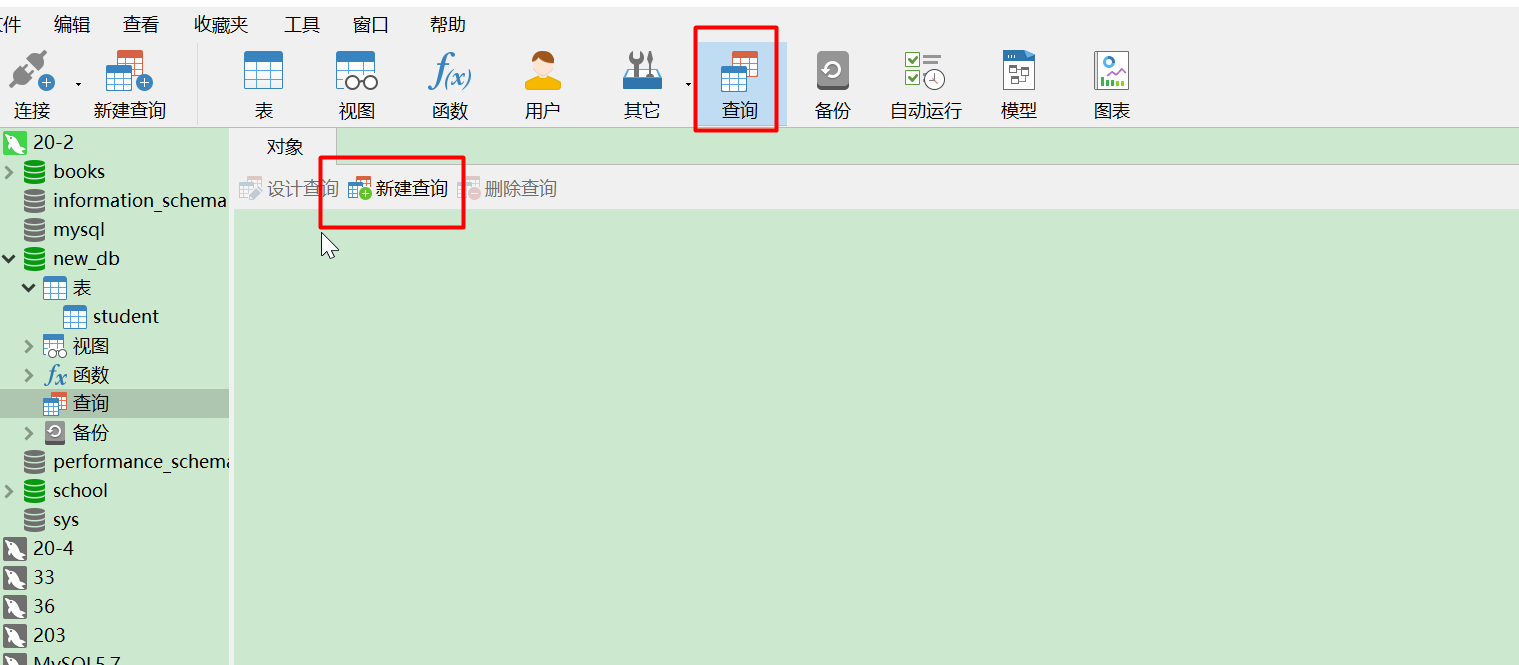
# 远程连接服务器上的MySQL服务步骤
# 0. 真机能ping通虚拟机。
ping 192.168.0.33
正在 Ping 192.168.0.33 具有 32 字节的数据:
来自 192.168.0.33 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.0.33 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.0.33 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.0.33 的回复: 字节=32 时间<1ms TTL=64
192.168.0.33 的 Ping 统计信息:
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
往返行程的估计时间(以毫秒为单位):
最短 = 0ms,最长 = 0ms,平均 = 0ms
# 1. MySQL是否启动
systemctl start mysqld
systemctl enable mysqld
# 2. firewalld 是否关闭
systemctl stop firewalld
systemctl disable firewalld
# 3. 连接测试
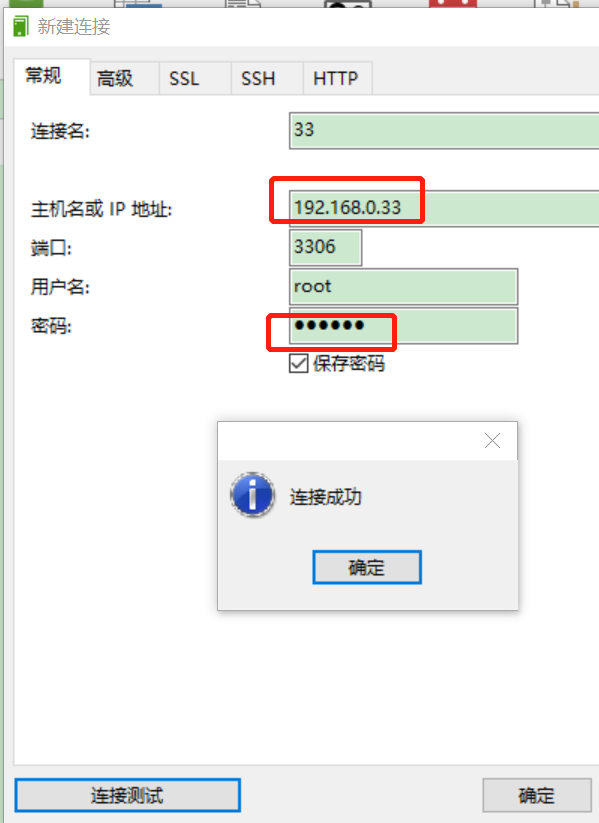
4.新建库
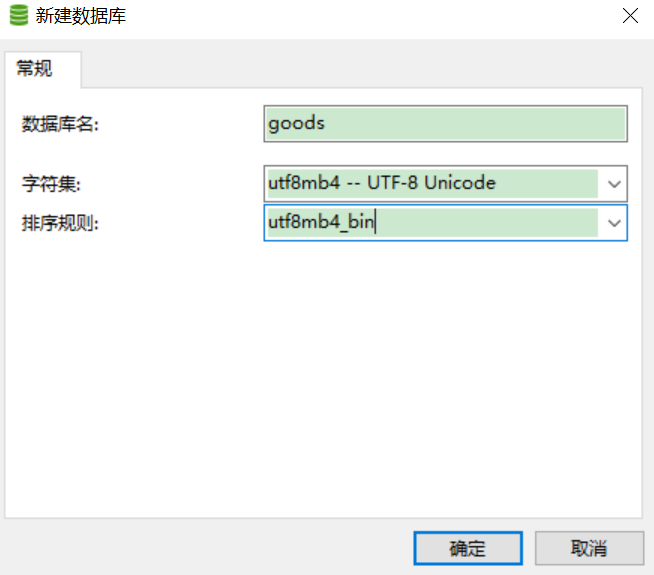
5.新建表
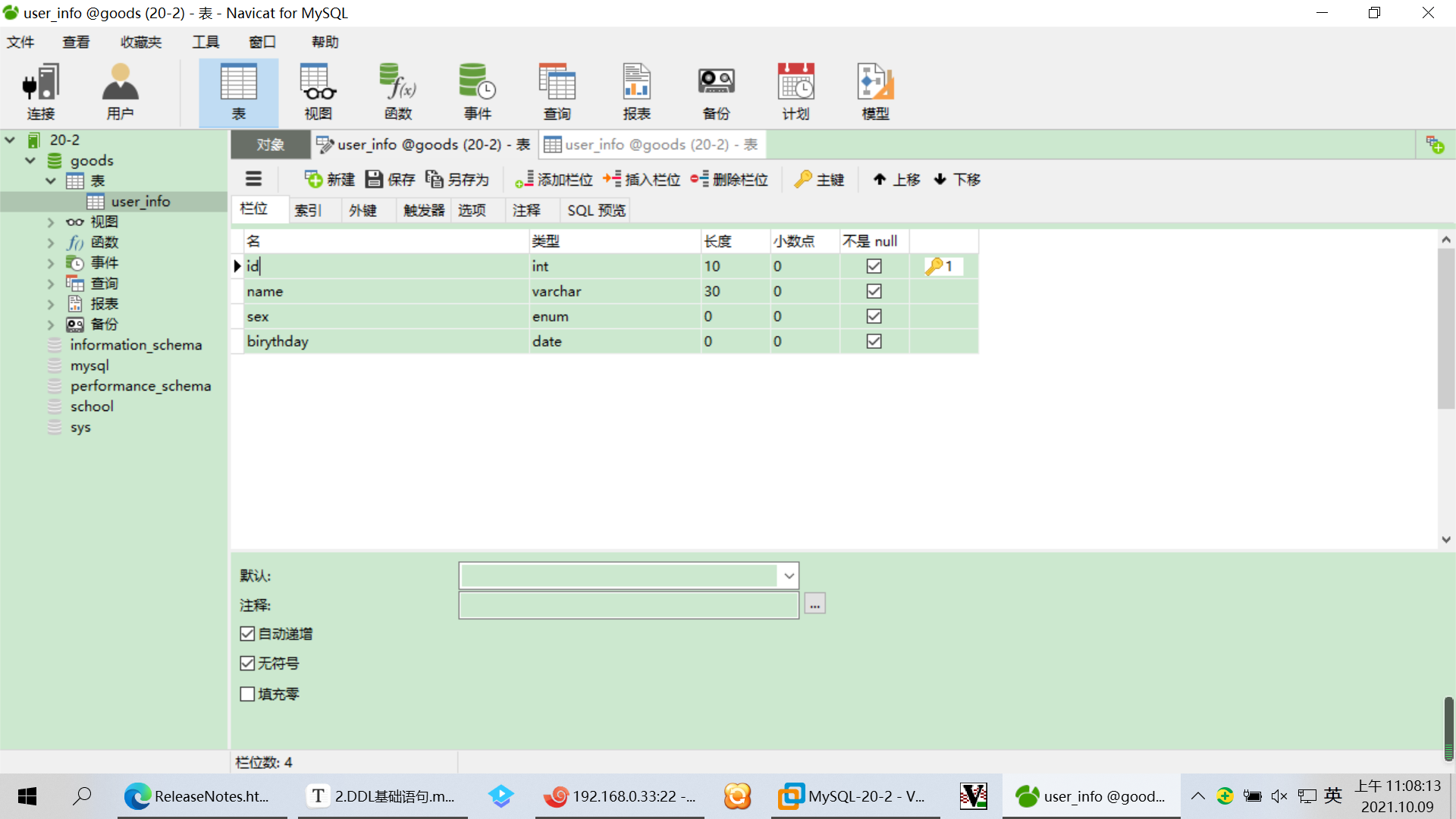
CREATE TABLE `user_info` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(30) COLLATE utf8mb4_bin NOT NULL,
`sex` enum('女','男') COLLATE utf8mb4_bin NOT NULL,
`birythday` date NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
# 约束条件
## 行级约束
1. unsigned 无符号,数字没有负数
2. not null 数据不能为空
3. primary key 主键(主关键字),不能为空,唯一
4. unique Key 唯一约束、唯一索引
5. foreign key 外键约束,用于多表关联
## 表级约束
1. engine 数据库查询MySQL8引擎默认为InnoDB(支持事务,安全性高)
2. charset 设置字符集
3. collate 设置字符排序规则
## 其他条件
1. auto_increment 自动增长
2. collate utf8mb4_bin 排序规则 字符集 数字 -> 文字
3. default 设置默认值
4. comment 设置行或表的备注
DQL数据查询语句
基础查询
# 查询语法
select 列名1,... from 库名.表名 where 条件;
# * 通配符 : 所有的列名
# 比较运算
select * from student where id != 1;
select * from student where birthday > '2003-04-03';
# 范围 数字、日期
select * from student where birthday between '2003-01-01' and '2003-12-31';
# in
select * from student where id in (1,3,5);
# and &&
select * from student where id in (1,3,5) and sex='女';
# or ||
select * from student where id in (2,4) or sex='女';
# not !
select * from student where id not in (2,4);
select * from student where not sex='女';
# is null
select * from student where birthday is null;
# is not null
select * from student where birthday is not null;
# 使用 ORDER BY 子句排序
ASC (ascend) : 升序
DESC (descend) :降序
ORDER BY 子句在SELECT语句的结尾。
# 升序(小 -> 大)
select * from student order by birthday;
# 降序(大 -> 小)
select * from student order by birthday desc;
# 分页 limit,MySQL中使用 LIMIT 实现分页
# LIMIT [位置偏移量, ] 行数
# 第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是 1,以此类推);第二个参数“行数”指示返回的记录条数。
select * from student limit 0,2;
select * from student limit 2,2;
# 模糊查询 like
select * from student where name like '武%';
select * from student where name like '%郎';
select * from student where name like '%三%';
| 条件语句 | 简介 |
|---|---|
| = != > < >= <= 比较运算 | 列名 运算符 值 |
| between 开始 and 结束 | 范围 id between 2 and 4 |
| in /not in | 成员 id in (2,4) |
| and | && | 逻辑与 查询结果必须满足==所有==条件 |
| or | || | 逻辑或 查询结果满足任意==一个==条件 |
| not | ! | 逻辑非 查询所有不满足条件的结果 |
| is null | 查询结果为空的值 |
| is not null | 查询结果不为空的值 |
| order by | 排序 order by id 逆序从大到小使用desc |
| like | 模糊查询 name like "%三%" % 表示任意个任意值 |
常用聚合函数
| 函数名 | 简介 |
|---|---|
| count() | 查询数量或次数 |
| max() | 最大值 |
| min() | 最小值 |
| avg() | 平均值 |
| sum() | 求和 |
# count()
select count(*) as '学生人数' from student where sex='女';
# max()
select max(grade) from score;
# min()
select min(grade) from score;
# avg()
select avg(grade) from score;
# sum()
select sum(grade) from score;
多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。 前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个 关联字段可能建立了外键,也可能没有建立外键。
# 主键: 主关键字,同一张表中必须是唯一的(不能重复),不能为空
primary key(id) 主键约束 唯一性和完整性
添加数据时不满足条件会报错
# 外键: 用于外表关联时,保证数据的完整性和有效性、一致性。
# 一对一关联
# 一对多关联
# 多对多关联
# 注意:
1. 外键关联的必须是其他表的主键;
2. 外键数据存储的类型必须和关联的数据的类型一致。
# student
CREATE TABLE `student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(30) COLLATE utf8mb4_bin NOT NULL,
`sex` enum('男','女') COLLATE utf8mb4_bin NOT NULL,
`birthday` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `student` (`id`, `name`, `sex`, `birthday`) VALUES (1, '武大郎', '男', '2000-1-1');
INSERT INTO `student` (`id`, `name`, `sex`, `birthday`) VALUES (2, '李二牛', '男', '2001-2-2');
INSERT INTO `student` (`id`, `name`, `sex`, `birthday`) VALUES (3, '张三丰', '男', '2002-3-3');
INSERT INTO `student` (`id`, `name`, `sex`, `birthday`) VALUES (4, '黄四郎', '男', '2003-4-4');
INSERT INTO `student` (`id`, `name`, `sex`, `birthday`) VALUES (5, '武则天', '女', '2004-5-5');
INSERT INTO `student` (`id`, `name`, `sex`, `birthday`) VALUES (6, '燕小六', '男', NULL);
# 课程表 course id name
create table course(
id tinyint unsigned primary key auto_increment,
name varchar(30) not null
) engine=InnoDB default charset=utf8mb4;
INSERT INTO `course` (`id`, `name`) VALUES (1, 'Python');
INSERT INTO `course` (`id`, `name`) VALUES (2, 'Java');
INSERT INTO `course` (`id`, `name`) VALUES (3, 'C');
INSERT INTO `course` (`id`, `name`) VALUES (4, 'MySQL');
INSERT INTO `course` (`id`, `name`) VALUES (5, 'Docker');
INSERT INTO `course` (`id`, `name`) VALUES (6, 'Hadoop');
INSERT INTO `course` (`id`, `name`) VALUES (7, 'Linux');
INSERT INTO `course` (`id`, `name`) VALUES (8, 'PHP');
INSERT INTO `course` (`id`, `name`) VALUES (9, 'OpenStack');
# 成绩表 score id sid cid grade
create table score(
id int unsigned primary key auto_increment,
sid int(10) unsigned,
cid tinyint unsigned,
grade decimal(5,1),
foreign key(sid) references student(id),
foreign key(cid) references course(id)
) engine=InnoDB default charset=utf8mb4;
INSERT INTO `score` (`id`, `sid`, `cid`, `grade`) VALUES (1, 1, 1, 77.0);
INSERT INTO `score` (`id`, `sid`, `cid`, `grade`) VALUES (2, 1, 2, 66.0);
INSERT INTO `score` (`id`, `sid`, `cid`, `grade`) VALUES (3, 1, 3, 88.0);
INSERT INTO `score` (`id`, `sid`, `cid`, `grade`) VALUES (4, 2, 1, 90.0);
INSERT INTO `score` (`id`, `sid`, `cid`, `grade`) VALUES (5, 2, 2, 80.0);
INSERT INTO `score` (`id`, `sid`, `cid`, `grade`) VALUES (6, 2, 3, 60.0);
SELECT
sc.id AS '编号',
stu. NAME AS '姓名',
co. NAME AS '课程名',
sc.grade AS '成绩'
FROM
score AS sc,
course AS co,
student AS stu
WHERE
sc.sid = stu.id
AND sc.cid = co.id;
分组查询 GROUP BY
# 每个学生的平均分、最高分、最低分、总分
select sid,avg(grade) from score group by sid;
select sid,max(grade) from score group by sid;
select sid,min(grade) from score group by sid;
select sid,sum(grade) from score group by sid;
# 每门课程的平均分、最高分、最低分、总分
select cid,avg(grade) from score group by cid;
select cid,max(grade) from score group by cid;
select cid,min(grade) from score group by cid;
select cid,sum(grade) from score group by cid;
# 对分组结果进行查询
select cid,avg(grade) from score group by cid having avg(grade)<80;
子查询
# 子查询:嵌套插叙,将一个select查询的结果作为另一个查询的条件进行查询。
SELECT
stu.id AS '学号',
stu. NAME AS '姓名',
cou. NAME AS '课程',
sc.grade AS '分数'
FROM
score AS sc,
student AS stu,
course AS cou
WHERE
stu.id = sc.sid
AND cou.id = sc.cid
AND grade IN (SELECT max(grade) FROM score);
可以使用INSERT INTO 加子查询语句将一张表的数据复制到另一张表。
示例SQL查询如下所示:
INSERT INTO 目标表名 (列1, 列2, 列3) SELECT 列1, 列2, 列3 FROM 源表名;
# 其中,"目标表名"为要复制数据的新表名称;"(列1, 列2, 列3)"指定了需要复制的列;"SELECT 列1, 列2, 列3 FROM 源表名;"选取了源表中需要复制的数据行。
注意事项:
确保目标表已经存在并且与源表结构相同或者包含相应的字段。
根据实际情况修改上述查询中的表名、列名等信息。
连接查询 JOIN
SELECT
stu.id AS '学号',
stu. NAME AS '姓名',
cou. NAME AS '课程',
sc.grade AS '分数'
FROM
score AS sc
JOIN
student AS stu ON sc.sid = stu.id
JOIN
course AS cou ON sc.cid = cou.id
where grade IN (SELECT max(grade) FROM score);
# left join:将左侧表中所有数据和右侧表中相关联数据查询出来,右侧表无关联则显示NULL
SELECT
stu.id AS '学号',
stu.name AS '姓名',
sc.grade AS '分数'
FROM student AS stu LEFT JOIN score AS sc ON sc.sid = stu.id;
# right join: 将右侧侧表中所有数据和左侧表中相关联数据查询出来,左侧表无关联则显示NULL
SELECT
stu.id AS '学号',
stu.name AS '姓名',
sc.grade AS '分数'
FROM student AS stu RIGHT JOIN score AS sc ON sc.sid = stu.id;
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的 行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
笛卡尔积也称为交叉连接 ,英文是 CROSS JOIN 。
它的作用就是可以把任意表进行连接,即使这两张表不相关。在MySQL中如下情况会出现笛卡 尔积:
- 使用JOIN...ON子句创建连接的语法结构:
SELECT table1 .column , table2 .column ,table3 .column
FROM table1
JOIN table2 ON table1 和 table2 的连接条件
JOIN table3 ON table2 和 table3 的连接条件
可以使用 ON 子句指定额外的连接条件。
这个连接条件是与其它条件分开的。
ON 子句使语句具有更高的易读性。
关键字 JOIN、 INNER JOIN、CROSS JOIN 的含义是一样的,都表示内连接
合并连接
合并查询结果利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。
合并时,两个表对应的列数和数据类型必须相同,并且相互对应。
各个SELECT语句之间使用UNION或UNION ALL关键字分隔。
- UNION 去除重复数据
- UNION ALL 显示所有数据 语法格式:
SELECT column , . . . FROM table1
UNION [ALL]
SELECT column , . . . FROM table2