一、前言
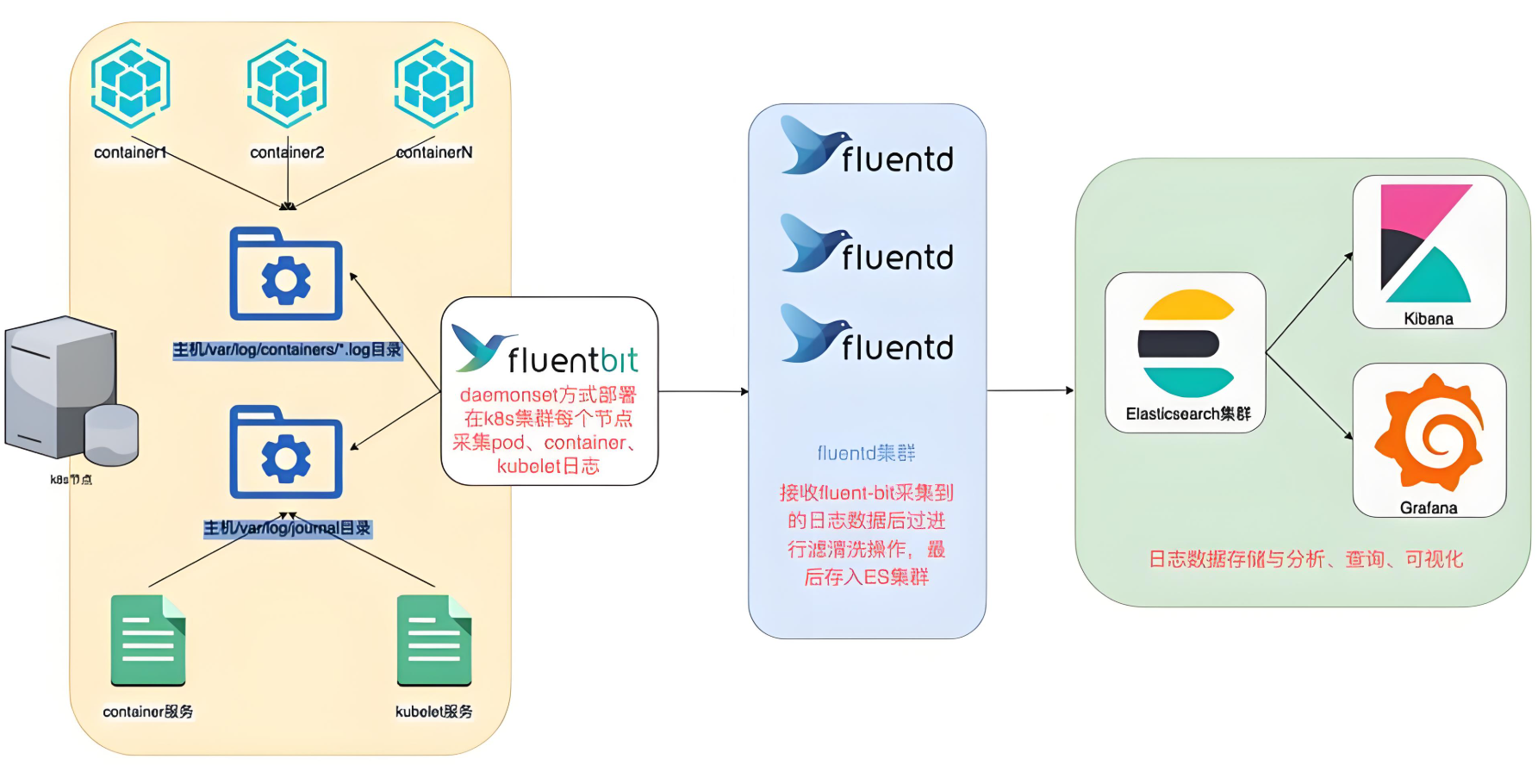
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。
1.1、主要组件功能
- Elasticsearch(ES):
- 强大的搜索和查询能力:ES是一个分布式搜索和分析引擎,具有高效的搜索和查询功能。它可以处理大规模的数据,并且支持复杂的查询操作。
- 可伸缩性和高可用性:可通过增加节点来扩展存储和吞吐量,并且自动进行数据分片和副本分配,以确保高可用性和容错性。
- 实时数据分析:实时地索引和分析日志数据,可以快速地提供实时的分析结果和可视化。
- Fluentd:
- 灵活的数据收集和传输:Fluentd 是一个开源的日志收集器,可以从各种数据源(如文件、应用程序日志、系统日志等)采集数据,并将其传输到指定的目标。
- 多样的插件生态系统:提供了丰富的插件生态系统,支持与各种数据源和目标的集成,如文件、数据库、消息队列等。数据的收集和导出更加灵活和可扩展。
- 可靠性和容错性:Fluentd 具备高可靠性和容错性,通过缓冲区和重试机制,即使在网络中断或目标不可用的情况下,也能保证数据的可靠传输和持久化。
- Kibana:
- 灵活的数据可视化:Kibana 是一个强大的数据可视化工具,可将日志数据转化为丰富的图表、仪表盘和报表。提供了各种直观易懂的可视化组件,以便快速理解数据趋势和分析结果。
- 实时监控和警报功能:实时监控日志数据,并设置警报规则以及响应动作。让用户可以及时发现并处理异常情况,提高系统的可靠性和稳定性。
- 用户友好的界面:提供了一个直观友好的用户界面,非技术人员也能轻松地使用和定制自己的仪表盘和报表,而无需编写复杂的查询语句和代码。
1.2、EFK组合优点
- 灵活性:EFK 技术栈中的每个组件都具有可定制和可扩展的特点,可以根据实际需求进行配置和扩展,满足不同环境和场景的需求。
- 实时性:Elasticsearch 和 Fluentd 能够实时处理和传输日志数据,日志的搜索和分析能够尽可能地接近实时。
- 可扩展性:Elasticsearch 是一个分布式存储和搜索引擎,能够水平扩展以应对大规模的日志数据。Fluentd 和 Kibana 也支持水平扩展,可以根据需要增加节点和实例,以适应日志数据量的增长。
- 可视化和分析能力:Kibana 提供了强大的可视化和分析工具,用户能够以直观的方式探索数据、构建仪表盘和生成图表,轻松进行数据分析和故障排查。
- 开源社区支持:EFK 技术栈是开源项目,有庞大的社区支持和活跃的开发者社群,提供了丰富的插件和文档资源,便于用户学习、使用和解决问题。
二、ES集群部署配置
2.1、环境准备
在创建 Elasticsearch 集群之前,我们先创建一个命名空间
kubectl create ns logging
需要配置 30Gi ReadWriteOnce 类型的 PV
vim my-pv.yaml
# ------------------------------------------------
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv-0
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.8.128 # 替换为你的 NFS 服务器地址
path: /data/nfs-1 # 替换为你的 NFS 共享路径
storageClassName: nfs-storage
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv-1
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.8.128 # 替换为你的 NFS 服务器地址
path: /data/nfs-2 # 替换为你的 NFS 共享路径
storageClassName: nfs-storage
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv-2
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.8.128 # 替换为你的 NFS 服务器地址
path: /data/nfs-3 # 替换为你的 NFS 共享路径
storageClassName: nfs-storage
# ------------------------------------------------
kubectl apply -f my-pv.yaml
2.2、安装 ES 集群
添加 ELastic 的 Helm 仓库:
helm repo add elastic https://helm.elastic.co
helm repo update
首先使用 helm pull 拉取 Chart 并解压:
helm pull elastic/elasticsearch --untar --version 7.7.1
cd elasticsearch
在该目录下面有用于 Master 节点安装配置的 values.yaml 文件:
vim values.yaml
# ------------------------------------------------
## 设置集群名称
clusterName: "elasticsearch"
## 设置节点名称
nodeGroup: "master"
## 设置角色
roles:
master: "true"
ingest: "true"
data: "true"
remote_cluster_client: "true"
ml: "true"
# ============镜像配置============
## 指定镜像与镜像版本
image: "192.168.57.200:8099/library/elasticsearch" # 默认镜像拉取容易失败,可以修改为局域网镜像
imageTag: "7.7.1"
imagePullPolicy: "IfNotPresent"
## 副本数
replicas: 3
minimumMasterNodes: 2
# ============资源配置============
## JVM 配置参数
esJavaOpts: "-Xmx1g -Xms1g"
## 部署资源配置(生产环境要设置大些)
resources:
requests:
cpu: "2000m"
memory: "2Gi"
limits:
cpu: "2000m"
memory: "2Gi"
## 数据持久卷配置
persistence:
enabled: true
## 存储数据大小配置
volumeClaimTemplate:
storageClassName: nfs-storage # 需要与pv保持一致
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
安装:
# 安装 master 节点
helm upgrade --install es7 -f values.yaml --namespace logging .
查看状态:
kubectl get pod -n logging -o wide
# ------------------------------------------------
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
elasticsearch-master-0 1/1 Running 0 2m49s 10.240.5.56 node3 <none> <none>
elasticsearch-master-1 1/1 Running 0 2m49s 10.240.6.94 node4 <none> <none>
elasticsearch-master-2 1/1 Running 0 2m49s 10.240.4.148 node2 <none> <none>
kubectl get pv,pvc |grep master-elasticsearch
# ------------------------------------------------
persistentvolume/pvc-10f00537-ef20-4d74-a72c-e74555b61031 30Gi RWO Delete Bound logging/elasticsearch-master-elasticsearch-master-1 nfs-storage 3m36s
persistentvolume/pvc-b5ebb29b-ee2d-4722-bd6f-b8d71dcde2f3 30Gi RWO Delete Bound logging/elasticsearch-master-elasticsearch-master-0 nfs-storage 3m36s
persistentvolume/pvc-ddbb36a8-4e80-4eeb-94a9-345943922b96 30Gi RWO Delete Bound logging/elasticsearch-master-elasticsearch-master-2 nfs-storage 3m36s
kubectl get svc -n logging
# ------------------------------------------------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-master ClusterIP 10.109.94.159 <none> 9200/TCP,9300/TCP 4m33s
elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 4m33s
curl 10.105.9.115:9200
# ------------------------------------------------
{
"name" : "elasticsearch-master-2",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "rlJ_9QKZQbOnTHVWNjMQ6w",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "5ad023604c8d7416c9eb6c0eadb62b14e766caff",
"build_date" : "2022-04-19T08:11:19.070913226Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
更多ES层面验证:
curl 10.105.9.115:9200/_cat/nodes
curl 10.105.9.115:9200/_cat/health
curl 10.105.9.115:9200/_cat/master
curl 10.105.9.115:9200/_cat/indices
三、Kibana部署配置
使用 helm pull 命令拉取 Kibana Chart 包并解压:
helm pull elastic/kibana --untar --version 7.7.1
cd kibana
创建用于安装 Kibana 的 values 文件:
## 配置 ElasticSearch 地址
elasticsearchHosts: "http://elasticsearch-master:9200"
## 相关镜像配置
image: "192.168.57.200:8099/library/kibana"
imageTag: "7.7.1"
imagePullPolicy: "IfNotPresent"
# ============资源配置============
resources:
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
# ============配置 Kibana 参数============
## kibana 配置中添加语言配置,设置 kibana 为中文
kibanaConfig:
kibana.yml: |
i18n.locale: "zh-CN"
# ============Service 配置============
service:
type: ClusterIP
port: 5601
## 开启并配置Kibana域名
ingress:
enabled: true
className: "nginx"
pathtype: ImplementationSpecific
annotations: {}
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
hosts:
- host: kibana.kubernets.cn
paths:
- path: /
安装部署:
helm upgrade --install kibana -f values.yaml --namespace logging .
查看状态:
kubectl get pod -n logging -o wide |grep kibana
# ------------------------------------------------
kibana-kibana-6bb4864dd6-4jbvc 1/1 Running 0 12m 10.240.3.119 node1 <none> <none>
kubectl get svc -n logging |grep kibana
# ------------------------------------------------
kibana-kibana ClusterIP 10.99.192.156 <none> 5601/TCP 52m
kubectl get ingress -n logging
# ------------------------------------------------
NAME CLASS HOSTS ADDRESS PORTS AGE
kibana-kibana nginx kibana.kubernets.cn 192.10.192.223 80 59m
curl kibana.kubernets.cn/app/home#/ -i
四、Fluentd采集组件
4.1、前言
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少。
另外一个工具 Fluent-bit 更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富。
Fluentd 更加成熟,使用更加广泛,所以这里我们使用 Fluentd 来作为日志收集工具。
4.2、工作原理
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。
Fluentd 支持超过 300 个日志存储和分析服务,在这方面是非常灵活的。
主要运行步骤如下:
- 首先 Fluentd 从多个日志源获取数据;
- 结构化并且标记这些数据;
- 然后根据匹配的标签将数据发送到多个目标服务去;
4.3、日志源配置
收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
<source>
@id fluentd-containers.log
@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
path /var/log/containers/*.log # 挂载的宿主机容器日志地址
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.* # 设置日志标签
read_from_head true
<parse> # 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern>
format json # JSON 解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
上面配置部分参数说明如下:
- id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
- type:Fluentd 内置的指令,
tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据。 - path:
tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。 - pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
- tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
4.4、路由配置
配置将日志数据发送到 Elasticsearch:
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
type_name fluentd
host "#{ENV['OUTPUT_HOST']}"
port "#{ENV['OUTPUT_PORT']}"
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"
queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"
overflow_action block
</buffer>
</match>
- match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成
**。 - id:目标的一个唯一标识符。
- type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
- log_level:指定要捕获的日志级别,我们这里配置成
info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。 - host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
- logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为
true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。 - Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
4.5、过滤
由于 Kubernetes 集群中应用太多,也有很多历史数据,所以我们可以只将某些应用的日志进行收集,比如我们只采集具有 logging=true 这个 Label 标签的 Pod 日志,这个时候就需要使用 filter,如下所示:
# 删除无用的属性
<filter kubernetes.**>
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有logging=true标签的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
五、Fluentd部署配置
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。
当然,也可以直接使用 Helm 来进行一键安装。不过为了能够了解更多实现细节,我们这里还是采用手动方法来进行安装。
可以直接使用官方的对于 Kubernetes 集群的安装文档: https://docs.fluentd.org/container-deployment/kubernetes。
首先,我们通过 ConfigMap 对象来指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件内容如下:
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
fluent.conf: |-
<source>
@id fluentd-containers.log
@type tail # Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.* # 设置日志标签
read_from_head true
<parse> # 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern>
format json # JSON解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
# 在日志输出中检测异常,并将其作为一条日志转发
# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
<match raw.kubernetes.**> # 匹配tag为raw.kubernetes.**日志信息
@id kubernetes
@type detect_exceptions # 使用detect-exceptions插件处理异常栈信息
remove_tag_prefix raw # 移除 raw 前缀
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
<filter **> # 拼接日志
@id filter_concat
@type concat # Fluentd Filter 插件,用于连接多个事件中分隔的多行日志。
key message
multiline_end_regexp /\n$/ # 以换行符“\n”拼接
separator ""
</filter>
# 添加 Kubernetes metadata 数据
<filter kubernetes.**>
@id filter_kubernetes_metadata
@type kubernetes_metadata
</filter>
# 修复 ES 中的 JSON 字段
# 插件地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser
<filter kubernetes.**>
@id filter_parser
@type parser # multi-format-parser多格式解析器插件
key_name log # 在要解析的记录中指定字段名称。
reserve_data true # 在解析结果中保留原始键值对。
remove_key_name_field true # key_name 解析成功后删除字段。
<parse>
@type multi_format
<pattern>
format json
</pattern>
<pattern>
format none
</pattern>
</parse>
</filter>
# 删除一些多余的属性
<filter kubernetes.**>
@type record_transformer
remove_keys $.kubernetes.namespace_labels.project,$.kubernetes.pod_ip,$.kubernetes.labels.app,$.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有logging=true标签的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host elasticsearch-master.logging.svc
port 9200
logstash_format true
logstash_prefix k8slog # 设置 index 前缀为 k8slog
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
上面配置文件中我们只配置了 docker 容器日志目录,收集到数据经过处理后发送到 elasticsearch-client:9200 服务。
注意:挂载的日志目录出现 unreadable 说明日志软连接有问题,无法读取日志。
如果有小伙伴,更改了docker的数据目录,这个时候需要更改为对应的数据目录,尤其是/var/log/pods/:
在我的 ds.yaml 中,必须挂载/data/docker/containers 而不是/var/lib/containers/
volumeMounts:
- name: fluentconfig
mountPath: /etc/fluent/config.d
- name: varlog
mountPath: /var/log
- name: varlogpods
mountPath: /var/log/pods
- name: datadockercontainers
mountPath: /data/docker/containers
volumes:
- name: fluentconfig
configMap:
name: fluentd-conf
- name: varlog
hostPath:
path: /var/log
- name: varlogpods
hostPath:
path: /var/log/pods
- name: datadockercontainers
hostPath:
path: /data/docker/containers
然后新建一个 fluentd-daemonset.yaml 的文件,文件内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
serviceAccountName: fluentd-es
containers:
- name: fluentd
image: quay.io/fluentd_elasticsearch/fluentd:v3.4.0
volumeMounts:
- name: fluentconfig
mountPath: /etc/fluent/config.d
- name: varlog
mountPath: /var/log
- name: varlogpods
mountPath: /var/log/pods
volumes:
- name: fluentconfig
configMap:
name: fluentd-conf
- name: varlog
hostPath:
path: /var/log
- name: varlogpods
hostPath:
path: /var/log/pods
我们将上面创建的 fluentd-config 这个 ConfigMap 对象通过 volumes 挂载到了 Fluentd 容器中。
场景:为了能够灵活控制哪些节点的日志可以被收集,还可以添加了一个 nodSelector 属性:
哪台节点上的日志需要采集,那么我们就需要给节点打上上面的标签。
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
如果你需要在其他节点上采集日志,则需要给对应节点打上标签,使用如下命令:
kubectl label nodes <node_name> beta.kubernetes.io/fluentd-ds-ready=true
另外集群使用的是 kubeadm 搭建的,默认情况下 master 节点有污点,所以如果想要也收集 master 节点的日志,则需要添加上容忍:
tolerations:
- operator: Exists
分别创建上面的 ConfigMap 对象和 DaemonSet:
kubectl create -f fluentd-configmap.yaml
# ------------------------------------------------
configmap "fluentd-conf" created
kubectl create -f fluentd-daemonset.yaml
# ------------------------------------------------
serviceaccount "fluentd-es" created
clusterrole.rbac.authorization.k8s.io "fluentd-es" created
clusterrolebinding.rbac.authorization.k8s.io "fluentd-es" created
daemonset.apps "fluentd" created
创建完成后,查看对应的 Pods 列表,检查是否部署成功:
kubectl get pods -n logging
# ------------------------------------------------
NAME READY STATUS RESTARTS AGE
elasticsearch-master-0 1/1 Running 0 3d5h
elasticsearch-master-1 1/1 Running 0 3d5h
elasticsearch-master-2 1/1 Running 0 3d5h
fluentd-2vz5z 1/1 Running 0 12m
fluentd-75vhz 1/1 Running 0 12m
fluentd-8t9z7 1/1 Running 0 12m
fluentd-98jj7 1/1 Running 6 7m58s
fluentd-9tlqp 1/1 Running 6 7m56s
fluentd-j7s2n 1/1 Running 0 12m
fluentd-m46sc 1/1 Running 6 7m55s
kafka-0 1/1 Running 0 3d2h
kafka-zookeeper-0 1/1 Running 0 3d2h
kibana-kibana-6bb4864dd6-4jbvc 1/1 Running 0 3d4h
Fluentd 启动成功后,就可以发送日志到 ES 了,但是我们这里是过滤了只采集具有 logging=true 标签的 Pod 日志,所以现在还没有任何数据会被采集。
下面我们部署一个简单的测试应用, 新建 counterlog.yaml 文件,文件内容如下:
apiVersion: v1
kind: Pod
metadata:
name: counterlog
labels:
logging: "true" # 一定要具有该标签才会被采集
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]
该 Pod 只是简单将日志信息打印到 stdout,所以正常来说 Fluentd 会收集到这个日志数据,在 Kibana 中也就可以找到对应的日志数据了,使用 kubectl 工具创建该 Pod:
kubectl create -f counterlog.yaml
kubectl get pods
# ------------------------------------------------
NAME READY STATUS RESTARTS AGE
counterlog 1/1 Running 0 9h
也可以手动测试下,是否kibana成功绑定了es集群;
手动推送一条测试数据
$ curl -X POST -H "Content-Type: application/json" -d '{
"message": "This is a test log message",
"timestamp": "2023-07-04T10:00:00",
"source": "kubernets.cn"
}' http://10.105.9.115:9200/mylog/_doc
- 选择"Stack Management"(堆栈管理)。
- 在堆栈管理界面中,您将看到一个"Data"(数据)菜单。在该菜单中,选择"Index Management"(索引管理)。这将显示 Elasticsearch 中的索引列表。
Pod 创建并运行后,回到 Kibana Dashboard 页面,点击左侧最下面的 Management -> Stack Management,进入管理页面,点击左侧 Kibana 下面的 索引模式,点击 创建索引模式 开始导入索引数据:
在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,定义了一个 k8s 的前缀,所以这里只需要在文本框中输入 k8slog-* 即可匹配到 Elasticsearch 集群中采集的 Kubernetes 集群日志数据,然后点击下一步,进入以下页面:
在该页面中配置使用哪个字段按时间过滤日志数据,在下拉列表中,选择@timestamp字段,然后点击 创建索引模式,创建完成后,点击左侧导航菜单中的 Discover,然后就可以看到一些直方图和最近采集到的日志数据了:
现在的数据就是上面 Counter 应用的日志,如果还有其他的应用,我们也可以筛选过滤:
我们也可以通过其他元数据来过滤日志数据,比如您可以单击任何日志条目以查看其他元数据,如容器名称,Kubernetes 节点,命名空间等。
六、总结
在 Kubernetes(K8S)架构下使用 EFK(Elasticsearch + Fluentd + Kibana)服务,具有如下优势:
- 日志集中管理:EFK 提供了一个集中的平台来收集、存储和管理容器化应用程序的日志。它能够从多个容器和节点收集日志,并将其发送到集中的 Elasticsearch 数据存储中。
- 可扩展性:Elasticsearch 和 Fluentd 支持水平扩展,可以根据需要增加节点或副本数量,以适应日志量的增长。
- 实时日志分析:通过 Kibana 可视化界面,EFK 提供了实时的日志分析和查询功能。可以轻松地搜索、过滤和分析大量的日志数据,以便进行故障排除、性能优化和监控。
- 灵活的日志解析:Fluentd 是一个高度可配置的日志收集代理,可以轻松进行日志解析、过滤和转换。它支持多种输入和输出插件,可以适应各种应用程序和日志格式。
- 强大的搜索和聚合功能:Elasticsearch 是一个分布式搜索和分析引擎,具有强大的搜索和聚合功能。它可以通过全文搜索、关键字过滤、聚合和可视化等功能,帮助用户快速定位和分析关键日志信息。
- 集成与生态系统:EFK 与 Kubernetes 生态系统紧密集成,支持通过标签过滤、命名空间隔离和动态配置等方式来灵活管理日志收集和展示。此外,EFK 还可以与其他监控和告警工具集成,以提供全面的应用程序运行时监控和报警能力。