Kubernetes网络入门
一、为什么Kubernetes网络很重要?
想象Kubernetes集群是一个大型小区,里面有很多“快递仓库”(服务器节点),每个仓库里存放着许多“快递盒”(Pod),每个快递盒里装着不同的物品(容器)。
Kubernetes网络就像小区内的道路系统和快递配送规则,确保:
- 快递盒(Pod)无论在哪个仓库,都能互相通信
- 外部快递(外部请求)能准确找到目标快递盒
- 快递盒地址变化时(如仓库搬迁),通信不受影响
二、核心概念:用“小区快递”类比理解
1. Pod:最小的“快递盒单元”
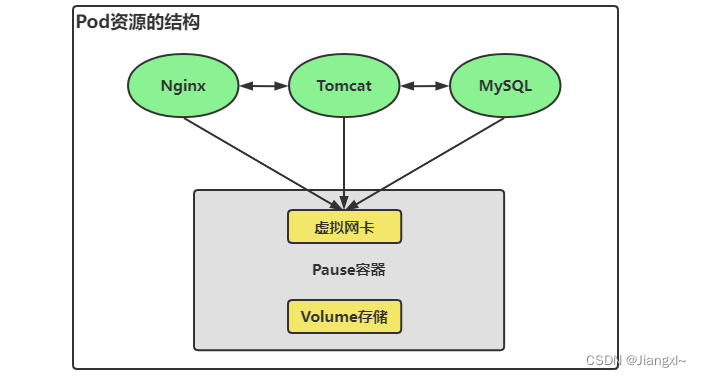
Pod是什么:
- 多个容器(如Web服务+配置工具)组成的“容器组”,共享一个“唯一快递单号”(IP地址)。
- 类比:一个快递盒里装着手机和充电器,它们共用同一个单号(Pod的IP),盒内物品通过localhost:端口直接传递(无需出盒)。
关键特性:
- IP独立:每个Pod的IP在集群内全局唯一,跨仓库(节点)也能直接访问(像手机号全国通用)。
- 共享网络:同一Pod内的容器共享网络空间,相当于快递盒内的“小房间”,互通无阻。
2. 扁平化网络:仓库之间没有“围墙”
CNI

-
目标:所有Pod(无论在哪个仓库)都能直接通信,无需中转或地址转换(NAT)。
-
实现方式:通过CNI网络插件搭建“虚拟大网络”:
-
Flannel(基础款):给每个仓库分配一段IP地址(如仓库A用10.1.1.0段),用“隧道”(VXLAN技术)连接仓库,让快递(数据包)穿越物理网络。
-
Calico(进阶款):支持复杂“交通规则”(网络策略),如禁止某两个仓库的快递互发。
-
类比:整个小区是一个大平层,所有快递盒的单号(IP)可直接定位,不管在哪个仓库。
-
技术支撑:CNI插件是“网络装修队”,按统一标准为Pod分配IP,构建逻辑二层/三层网络。
3. Service:集群的“智能传达室”
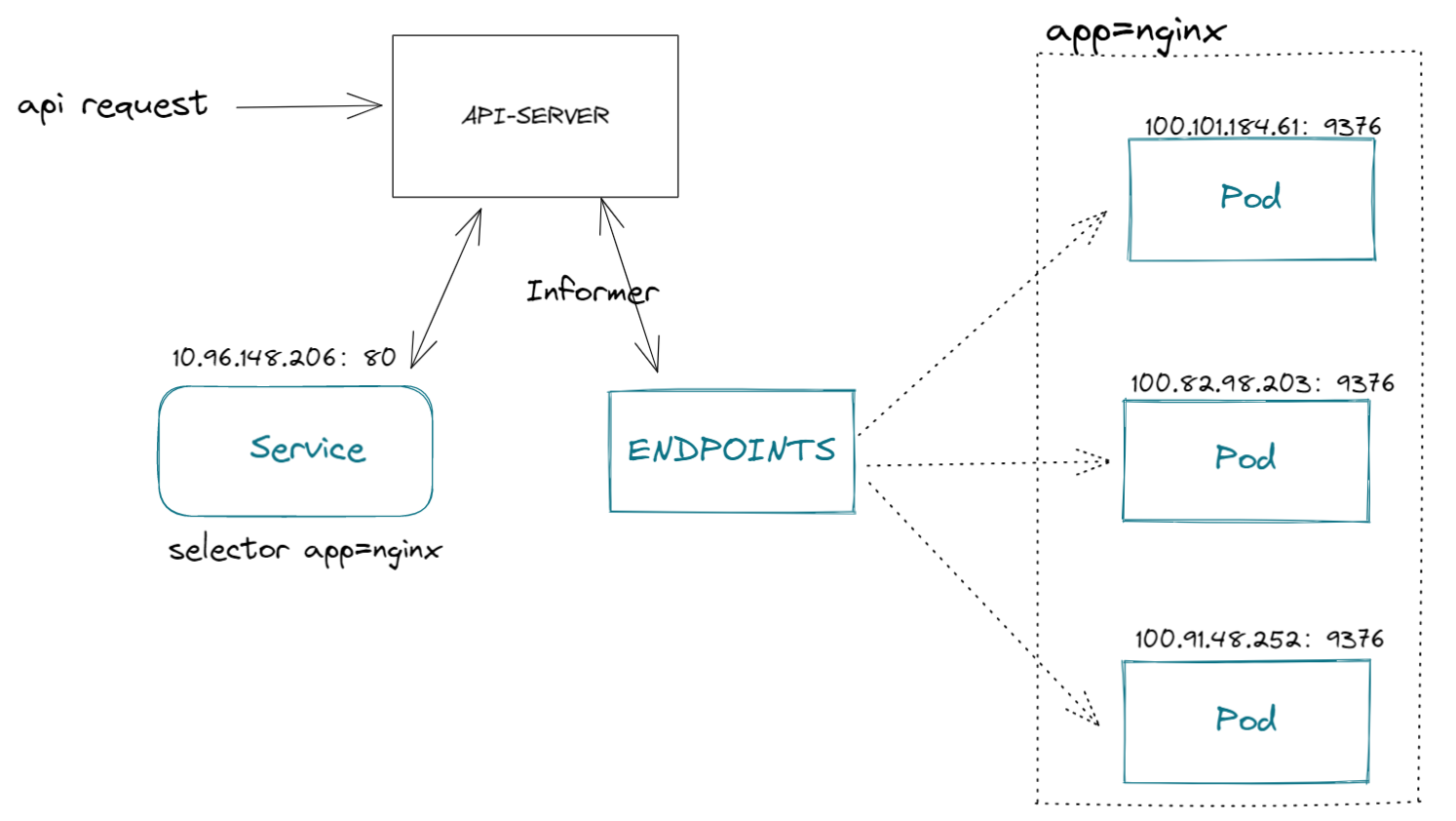
为什么需要: Pod的IP会因扩容、故障等频繁变化(如快递盒损坏后换盒,单号变更),直接记单号太麻烦!
核心作用:
给一组功能相同的Pod(如3个Web服务Pod)一个固定入口(Service的IP/域名),外部只需记住传达室地址,背后的Pod随便换,入口不变。
三大功能:
- 服务发现:通过DNS域名(如
web-service.default.svc.cluster.local)替代动态Pod IP,像“baidu.com”替代具体IP。 - 负载均衡:把请求平均分给背后的多个Pod,避免单个Pod过载(如食堂多个窗口分流人群)。
- 端口映射:隐藏Pod内部端口(如外部访问80端口,转发到Pod的8080端口)。
三、网络插件入门:先学最简单的Flannel
1. Flannel:中小集群的“基础快递系统”
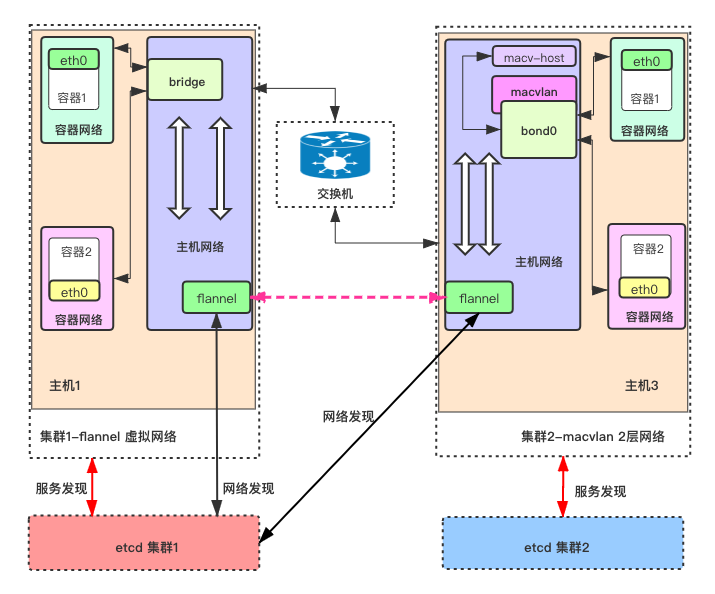
适合场景: 小规模集群(几十节点)、开发测试环境,无需复杂网络策略(如禁止通信)。
核心功能:
-
IP地址分配:给每个仓库分一块“地址池”(如仓库A:10.1.1.0/24),Pod从所属仓库的地址池获取IP。
-
覆盖网络(Overlay):通过“隧道”封装数据包(如VXLAN技术),让跨仓库的Pod通信像在同一网络内。
- 举例:PodA(10.1.1.10)给仓库B的PodB(10.1.2.5)发快递,Flannel给数据包套上“大信封”(含仓库B的真实IP),物理网络传递后拆封送达。
优缺点:
| 优点 | 缺点 | 适合谁 |
|---|---|---|
| 简单易配置,5分钟搞定 | 不支持网络策略(如禁止某Pod通信) | 新手入门、中小项目 |
| 兼容性强,适配多数K8s版本 | 大规模集群可能性能瓶颈 | 测试环境、非复杂场景 |
2. Flannel工作原理(三步搞定跨仓库通信)
-
分配子网:集群启动时,为每个仓库分配唯一IP段(如仓库A:10.1.1.0/24,仓库B:10.1.2.0/24)。
-
封装数据包:跨仓库通信时,用VXLAN技术给数据包加“外层包装”(含目标仓库IP),让物理网络能识别路径([插入Flannel网络流程图:显示VXLAN封装过程])。
-
路由转发:每个仓库维护路由表,指引数据包“去XX网段请走Flannel隧道”。
四、深入理解Service:集群的“万能入口”
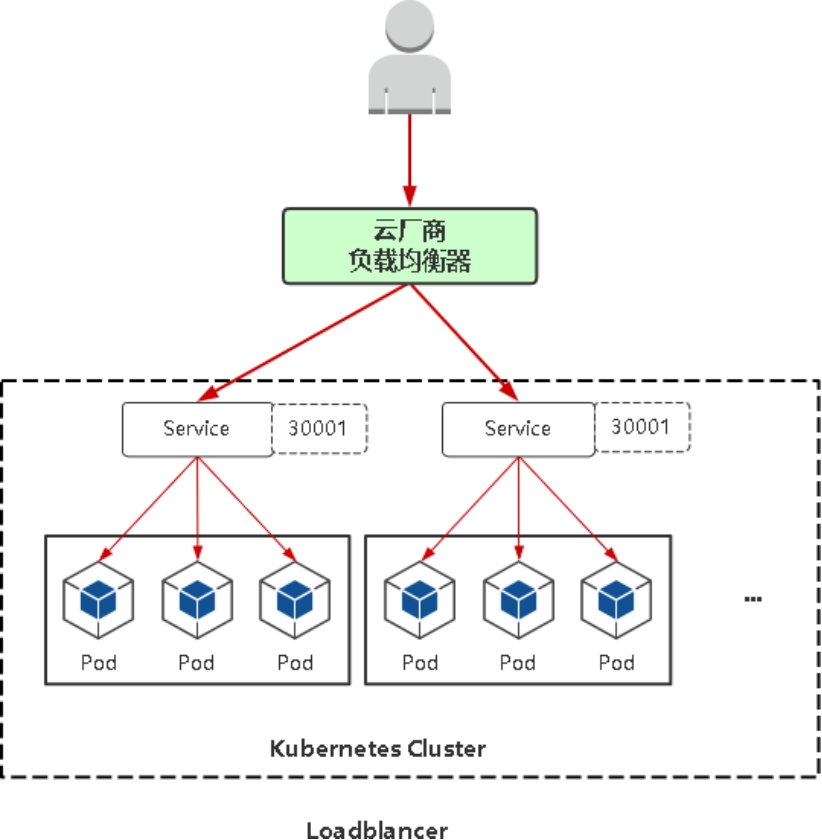
1. Service的四种类型(超详细对比)
| 类型 | 作用 | 访问方式 | 适用场景 | 类比 |
|---|---|---|---|---|
| ClusterIP(默认) | 集群内通信,外部不可见 | 集群内域名/IP | Pod间调用(如后端服务互调) | 小区内的快递中转站,仅内部可见 |
| NodePort | 外部通过节点端口访问 | 节点IP:端口(如192.168.1.10:30080) | 简单外部访问(开发测试) | 每栋楼外墙开统一窗口,外部通过“楼号+窗口”访问 |
| LoadBalancer(云环境) | 对接云服务商负载均衡器 | 公网IP(如47.98.123.45) | 生产环境公网服务(如Web网站) | 小区门口的大型快递柜,外部直接通过柜号取件 |
| Headless(无IP) | 不做负载均衡,返回Pod列表 | 客户端获取Pod IP列表自行选择 | 分布式系统(如ZooKeeper、etcd) | 给快递员住户名单,让其自己决定送哪家 |
2. Service如何找到背后的Pod?——标签选择器(Label Selector)
步骤:
A.给Pod打标签(如app=web、env=prod),相当于贴“住户类型”标签。
B.在Service配置中用selector指定标签,例如:
spec:
selector:
app: web # 关联所有标签app=web的Pod
C.Kubernetes自动将符合标签的Pod加入Service的“后端列表”,动态更新(新增/删除Pod时自动调整。
3. Service与Endpoint:访问外部服务的神器
当需要访问集群外服务(如第三方数据库)时:
创建同名Service和Endpoint:
- Service定义入口(如
external-db),不关联任何Pod。 - Endpoint配置外部服务的IP和端口。
集群内通过Service域名访问,流量自动转发到Endpoint的外部地址(外部IP变更只需修改Endpoint,内部配置无需改动)。
4. 流量转发原理:Kube-Proxy的三种模式
Service的负载均衡由Kube-Proxy实现,根据集群规模选择模式
- iptables(默认):用Linux防火墙规则直接转发,适合中小集群。
- IPVS(推荐大规模):基于内核级模块,支持更多负载均衡算法,性能更高。
- User-Space(已淘汰):流量经Kube-Proxy程序转发,速度慢,已弃用。
五、通信模式:集群内外如何互通?
1. Pod之间通信
- 同一节点内:通过Docker网桥(docker0)直接转发,速度最快(像同层楼内送货,无需出楼)
- 跨节点:通过Flannel等插件的隧道通信,数据包先到仓库物理网卡,再经隧道到目标仓库(像跨楼送货,需通过小区主干道)
2. 外部访问集群:三种“开门方式”对比
| 方式 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| NodePort | 简单,无需额外组件 | 每个节点都开端口,浪费资源 | 开发测试,临时外部访问 |
| HostPort | 仅在运行Pod的节点开端口,省资源 | Pod迁移后端口位置变化 | 有状态服务,Pod不常迁移 |
| Ingress(推荐) | 支持域名、路径、SSL,整洁高效 | 需要部署Ingress控制器(如Nginx) | 生产环境,需复杂路由 |
3. 集群内访问外部服务
- 直接访问:Pod用外部服务的IP:端口直接连接(如
http://192.168.100.10:8080)。 - 通过Endpoint:解耦外部地址变化,集群内通过Service域名访问,实际转发到Endpoint配置的外部地址(适合外部服务IP可能变更的场景,[插入Endpoint通信示意图])。
六、新手总结:必记三大点
1. Pod的IP是“全局通”
每个Pod有独立IP,跨节点直接通信,无需NAT(像手机号,无论在哪都能打通)。
2. Service是“不变的门牌号”
- 别记Pod的动态IP,记Service的固定入口(域名/IP)。
- 根据场景选类型:集群内用ClusterIP,外部访问用NodePort/LoadBalancer,分布式系统用Headless。
3. 从Flannel入门,再学进阶插件
- 新手先掌握Flannel(简单够用),熟练后学习Calico(支持网络策略,适合大规模生产)。
七、一句话总结Kubernetes网络
Kubernetes网络就像一个智能快递系统:
- Pod是装着容器的快递盒,每个有唯一单号(IP)。
- Service是固定收货点,不管快递盒怎么换,收货点不变,还能自动分流快递。
- Flannel等插件是快递通道,保证跨仓库送件畅通。
- Ingress是大门门卫,让外部能通过域名轻松找到目标服务([插入Kubernetes网络整体架构图])。
跟着这个思路,新手也能轻松玩转Kubernetes网络!