Hadoop环境搭建
1.配置Linux基础环境
# 获取IP
[root@base ~]# ifconfig |grep inet|head -1
inet 192.168.91.10 netmask 255.255.255.0 broadcast 192.168.91.255
# 设置主机名
[root@base ~]# hostnamectl set-hostname master
[root@base ~]# hostname
master
# 绑定主机名和IP地址
[root@base ~]# vim /etc/hosts
192.168.91.10 master
# 关闭防火墙
[root@base ~]# systemctl stop firewalld
[root@base ~]# systemctl disable firewalld
# 创建hadoop账户
[root@base ~]# useradd hadoop
[root@base ~]# passwd hadoop
更改用户 hadoop 的密码 。
新的 密码:hadoop
无效的密码: 密码少于 8 个字符
重新输入新的 密码:hadoop
passwd:所有的身份验证令牌已经成功更新。密码设置为hadoop
2.安装Java环境
[root@base ~]# mkdir /opt/software
[root@base ~]# cd /opt/software/
[root@base software]# rz
# 上传 jdk 到此目录
[root@base software]# ls
jdk-8u131-linux-x64.tar.gz
[root@base software]#tar -xvf jdk-8u131-linux-x64.tar.gz -C /usr/local/
[root@base software]# ln -s /usr/local/jdk1.8.0_131/ /usr/local/jdk
# 配置Java环境变量
[root@base ~]# vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
[root@base ~]# source /etc/profile
[root@base ~]# echo $JAVA_HOME
/usr/local/jdk
[root@base ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
3.安装Hadoop
# 上传安装包
[root@base software]# ls
hadoop-2.7.7.tar.gz jdk-8u131-linux-x64.tar.gz
[root@base software]# tar -xvf hadoop-2.7.7.tar.gz -C /usr/local/
[root@base software]# ln -s /usr/local/hadoop-2.7.7/ /usr/local/hadoop
# 配置Hadoop环境变量
[root@base ~]# vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@base ~]# source /etc/profile
[root@base ~]# hadoop version
Hadoop 2.7.7
Subversion Unknown -r c1aad84bd27cd79c3d1a7dd58202a8c3ee1ed3ac
Compiled by stevel on 2018-07-18T22:47Z
Compiled with protoc 2.5.0
From source with checksum 792e15d20b12c74bd6f19a1fb886490
This command was run using /usr/local/hadoop-2.7.7/share/hadoop/common/hadoop-common-2.7.7.jar
# 修改权限
[root@base ~]# chown hadoop.hadoop -R /usr/local/hadoop
4.安装单机版Hadoop系统
[root@base ~]# cd /usr/local/hadoop
[root@base hadoop]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
# 测试 Hadoop 本地模式的运行
[root@base hadoop]# su - hadoop
[hadoop@master ~]$ mkdir ~/input
[hadoop@master ~]$ vim ~/input/data.txt
## 输入如下内容,保存退出。
Hello World
Hello Hadoop
Hello Huasan
[hadoop@master ~]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount ~/input/data.txt ~/output
[hadoop@master ~]$ cd output/
[hadoop@master output]$ ls
part-r-00000 _SUCCESS
[hadoop@master output]$ cat ~/output/part-r-00000
Hadoop 1
Hello 3
Huasan 1
World 1
5.集群网络配置
服务器集群
3 个以上节点,节点间网络互通,各节点最低配置:双核 CPU、8GB 内存、100G硬盘
IP地址
192.168.91.10 master 192.168.91.11 slave1 192.168.91.12 slave2
运行环境
CentOS 7.X
服务和组件
完成前面的实验,其他服务根据实验需求安装
# 修改 修改 slave1 机器IP和主机名
[root@master ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.91.11"
[root@master ~]# systemctl restart network
[root@master ~]# hostnamectl set-hostname slave1
192.168.91.10 master
192.168.91.11 slave1
192.168.91.12 slave2
# 修改 slave2 机器IP和主机名
[root@master ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.91.12"
[root@master ~]# systemctl restart network
[root@master ~]# hostnamectl set-hostname slave2
192.168.91.10 master
192.168.91.11 slave1
192.168.91.12 slave2
[root@master ~]# ping master
PING master (192.168.91.10) 56(84) bytes of data.
64 bytes from master (192.168.91.10): icmp_seq=1 ttl=64 time=0.013 ms
[root@master ~]# ping slave1
PING slave1 (192.168.91.11) 56(84) bytes of data.
64 bytes from slave1 (192.168.91.11): icmp_seq=1 ttl=64 time=0.264 ms
[root@master ~]# ping slave2
PING slave2 (192.168.91.12) 56(84) bytes of data.
64 bytes from slave2 (192.168.91.12): icmp_seq=1 ttl=64
# SSH 无密码验证配置
# 切换到 hadoop 用户
[root@master ~]# su - hadoop
[root@slave1 ~]# su - hadoop
[root@slave2 ~]# su - hadoop
# 每个节点生成秘钥对
[hadoop@master ~]$ ssh-keygen
[hadoop@slave1 ~]$ ssh-keygen
[hadoop@slave2 ~]$ ssh-keygen
# 交换 SSH 密钥公
[hadoop@master ~]$ ssh-copy-id master
[hadoop@master ~]$ ssh-copy-id slave1
[hadoop@master ~]$ ssh-copy-id slave2
[hadoop@slave1 ~]$ ssh-copy-id master
[hadoop@slave1 ~]$ ssh-copy-id slave1
[hadoop@slave1 ~]$ ssh-copy-id slave2
[hadoop@slave2 ~]$ ssh-copy-id master
[hadoop@slave2 ~]$ ssh-copy-id slave1
[hadoop@slave2 ~]$ ssh-copy-id slave2
# 测试 SSH 无密码登录
[hadoop@master ~]$ ssh slave1
Last login: Wed Apr 13 10:50:39 2022
[hadoop@slave1 ~]$
6.hadoop 全分布配置
先在master上进行配置
# 配置 hdfs-site.xml 文件参数
[hadoop@master ~]$ cd /usr/local/hadoop/etc/hadoop/
[hadoop@master hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
Hadoop 文件参数配置:
| 序号 | 参数名 | 默认值 | 参数解释 |
|---|---|---|---|
| 1 | dfs.namenode.secondary.http-address | 0.0.0.0:50090 | 定义 HDFS 对应的 HTTP 服务器地址和端口 |
| 2 | dfs.namenode.name.dir | file://${hadoop.tmp.dir}/dfs/name | 定义 DFS 的名称节点在本地文件系统的位置 |
| 3 | dfs.datanode.data.dir | file://${hadoop.tmp.dir}/dfs/data | 定义 DFS 数据节点存储数据块时存储在本地文件系统的位置 |
| 4 | dfs.replication | 3 | 缺省的块复制数量 |
| 5 | dfs.webhdfs.enabled | true | 是否通过 http 协议读取 hdfs 文件,则集群安全性较差 |
# 配置 core-site.xml 文件参数
[hadoop@master hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
```
| 序号 | 参数名 | 默认值 | 参数解释 |
| ---- | ------------------- | ------------------------ | ------------------ |
| 1 | fs.defaultFS | file:/// | 文件系统主机和端口 |
| 2 | io.file.buffer.size | 4096 | 流文件的缓冲区大小 |
| 3 | hadoop.tmp.dir | /tmp/hadoop-${user.name} | 临时文件夹 |
```ini
# 配置 mapred-site.xml
[hadoop@master hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@master hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
| 序号 | 参数名 | 默认值 | 参数解释 |
|---|---|---|---|
| 1 | mapreduce.framework.name | local | 取值 local、classic 或yarn 其中之一,如果不是yarn,则不会使用 YARN 集群来实现资源的分配 |
| 2 | mapreduce.jobhistory.address | 0.0.0.0:10020 | 定义历史服务器的地址和端口,通过历史服务器查看已经运行完的Mapreduce 作业记录 |
| 3 | mapreduce.jobhistory.webapp.addres | 0.0.0.0:19888 | 定义历史服务器 web 应用访问的地址和端口 |
# 配置 yarn-site.xml
[root@master hadoop]# vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
| 序号 | 参数名 | 默认值 | 参数解释 |
|---|---|---|---|
| 1 | yarn.resourcemanager.address | 0.0.0.0:8032 | ResourceManager 提供给客户端访问的地址。客户端通过该地址向 RM 提交应用程序,杀死应用程序等 |
| 2 | yarn.resourcemanager.scheduler.address | 0.0.0.0:8030 | 定义历史服务器的地址和端口,通过历史服务器查看已经运行完的Mapreduce 作业记录 |
| 3 | yarn.resourcemanager.resource-tracker.address | 0.0.0.0:8031 | ResourceManager 提供给 NodeManager 的地址。NodeManager 通过该地址向RM 汇报心跳,领取任务等 |
| 4 | yarn.resourcemanager.admin.address | 0.0.0.0:8033 | ResourceManager 提供给管理员的访问地址。管理员通过该地址向 RM 发送管理命令等 |
| 5 | yarn.resourcemanager.webapp.address | 0.0.0.0:8088 | ResourceManager 对 web 服务提供地址。用户可通过该地址在浏览器中查看集群各类信息 |
| 6 | yarn.nodemanager.aux-services | org.apache.hadoop. mapred.ShuffleHand ler |
通过该配置项,用户可以自定义一些服务,MapReduce 的 shuffle 功能就是采用这种方式实现的,这样就可以在NodeManager 上扩展自己的服务。 |
# 配置 masters 文件
[hadoop@master hadoop]$ vim masters
192.168.91.10
# 配置 slaves 文件
[hadoop@master hadoop]$ vim slaves
192.168.91.11
192.168.91.12
[hadoop@master hadoop]$ mkdir -p /usr/local/hadoop/{data,dfs/name,dfs/data}
[hadoop@master ~]$ chown hadoop.hadoop -R /usr/local/hadoop
# 同步配置文件到 Slave 节点
[hadoop@master ~]$ scp -r /usr/local/hadoop/ hadoop@slave1:/usr/local/
[hadoop@master ~]$ scp -r /usr/local/hadoop/ hadoop@slave2:/usr/local/
7.配置 Hadoop 集群运行
# master 格式化 NameNode
[hadoop@master hadoop]$ hdfs namenode -format
# 启动 NameNode
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
# 查看 Java 进程
[hadoop@master hadoop]$ jps
127978 Jps
126445 NameNode
# slave1 启动 DataNode
[hadoop@slave1 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/hadoop-2.7.7/logs/hadoop-hadoop-datanode-slave1.out
[hadoop@slave1 ~]$ jps
2148 DataNode
2602 Jps
# slave2 启动 DataNode
[hadoop@slave2 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/hadoop-2.7.7/logs/hadoop-hadoop-datanode-slave2.out
[hadoop@slave2 ~]$ jps
129265 DataNode
129813 Jps
# master 启动 SecondaryNameNode
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /usr/local/hadoop-2.7.7/logs/hadoop-hadoop-secondarynamenode-master.out
[hadoop@master hadoop]$ jps
2244 Jps
2069 SecondaryNameNode
126445 NameNode
# 查看 HDFS 数据存放位置
[hadoop@master hadoop]$ ls -l /usr/local/hadoop/dfs/
总用量 8
drwxrwxr-x. 2 hadoop hadoop 4096 4月 13 12:33 data
drwxrwxr-x. 3 hadoop hadoop 4096 4月 13 14:26 name
[hadoop@master hadoop]$ ls -l /usr/local/hadoop/tmp/dfs/
总用量 4
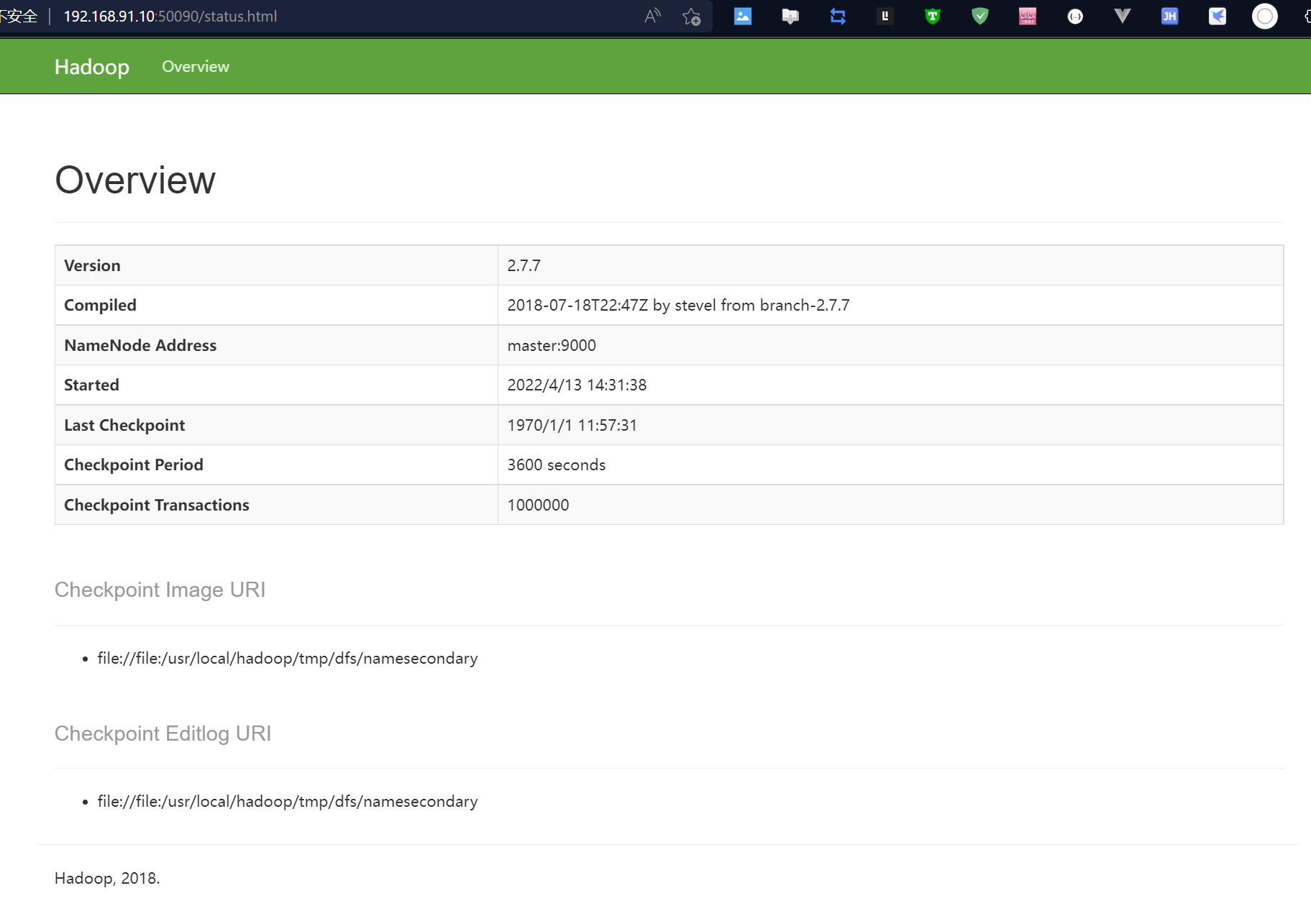
drwxrwxr-x. 3 hadoop hadoop 4096 4月 13 14:32 namesecondary
# 查看 HDFS 的报告
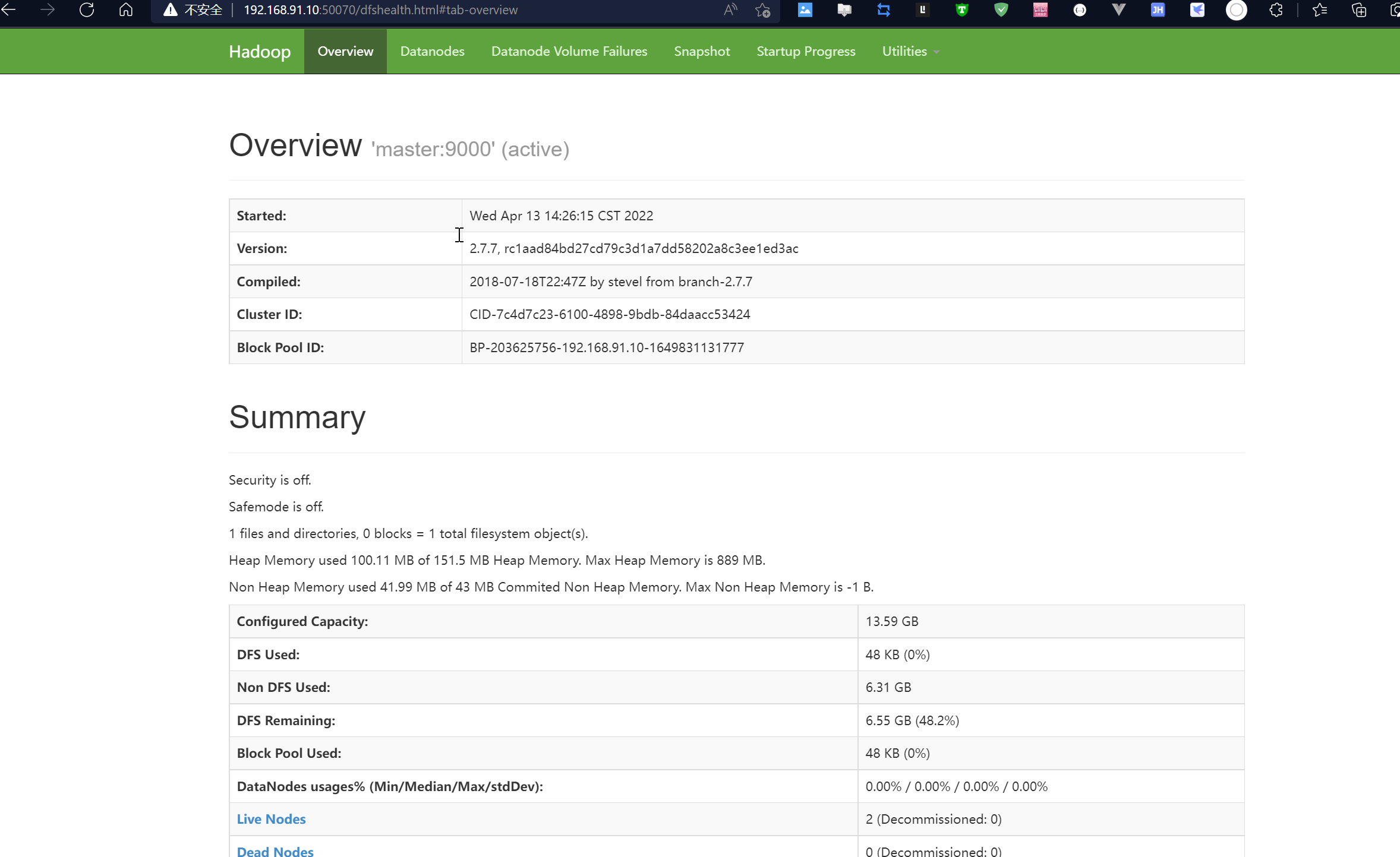
[hadoop@master hadoop]$ hdfs dfsadmin -report
Configured Capacity: 14593703936 (13.59 GB)
Present Capacity: 7035142144 (6.55 GB)
DFS Remaining: 7035092992 (6.55 GB)
DFS Used: 49152 (48 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.91.11:50010 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 7296851968 (6.80 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 3385434112 (3.15 GB)
DFS Remaining: 3517128704 (3.28 GB)
DFS Used%: 0.00%
DFS Remaining%: 48.20%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Apr 13 14:34:25 CST 2022
Name: 192.168.91.12:50010 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 7296851968 (6.80 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 3384598528 (3.15 GB)
DFS Remaining: 3517964288 (3.28 GB)
DFS Used%: 0.00%
DFS Remaining%: 48.21%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Apr 13 14:34:26 CST 2022
## 使用浏览器查看节点状态,进入页面可以查看NameNode和DataNode
http://master:50070
## http://master:50090,进入页面可以查看 SecondaryNameNode
信息
可以使用 start-dfs.sh 命令启动 HDFS。这时需要配置 SSH 免密码登录,否则在启动过
程中系统将多次要求确认连接和输入 Hadoop 用户密码
[hadoop@master hadoop]$ stop-dfs.sh
[hadoop@master hadoop]$ start-dfs.sh
# 确保 dfs 和 yarn 都启动成功
[hadoop@master hadoop]$ start-yarn.sh
[hadoop@master hadoop]$ jps
12777 NameNode
15900 Jps
15373 ResourceManager
13150 SecondaryNameNode
# 将输入数据文件复制到 HDFS 的/input 目录中:
[hadoop@master ~]$ hdfs dfs -put ~/input/data.txt /input
[hadoop@master ~]$ hdfs dfs -ls /input
-rw-r--r-- 3 hadoop supergroup 38 2022-04-13 14:45 /input
# 运行 WordCount 案例,计算数据文件中各单词的频度
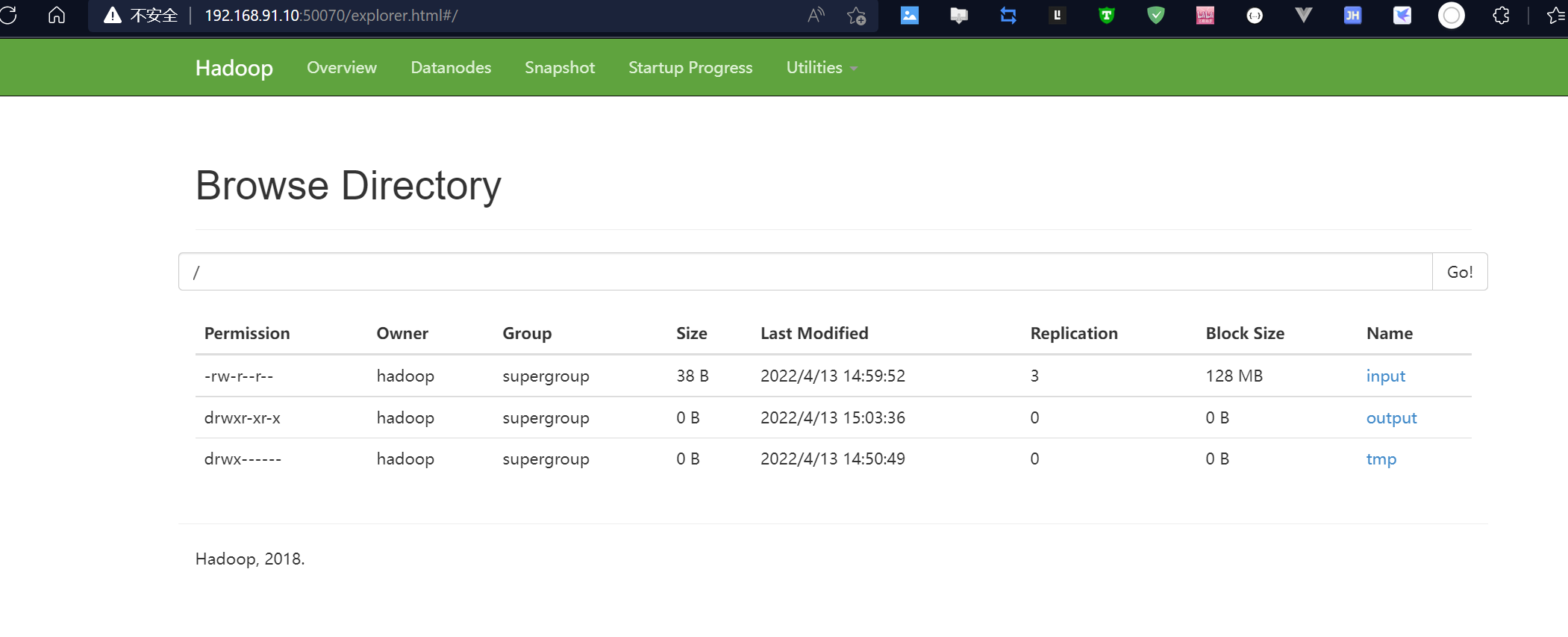
[hadoop@master ~]$ hdfs dfs -mkdir /output
[hadoop@master ~]$ hdfs dfs -ls /
Found 2 items
-rw-r--r-- 3 hadoop supergroup 38 2022-04-13 14:45 /input
drwxr-xr-x - hadoop supergroup 0 2022-04-13 14:46 /output
# 删除 /output
[hadoop@master ~]$ hdfs dfs -rm -r -f /output
22/04/13 14:47:53 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /output
[hadoop@master ~]$ hdfs dfs -ls /
Found 1 items
-rw-r--r-- 3 hadoop supergroup 38 2022-04-13 14:45 /input
[hadoop@master input]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input/ /output
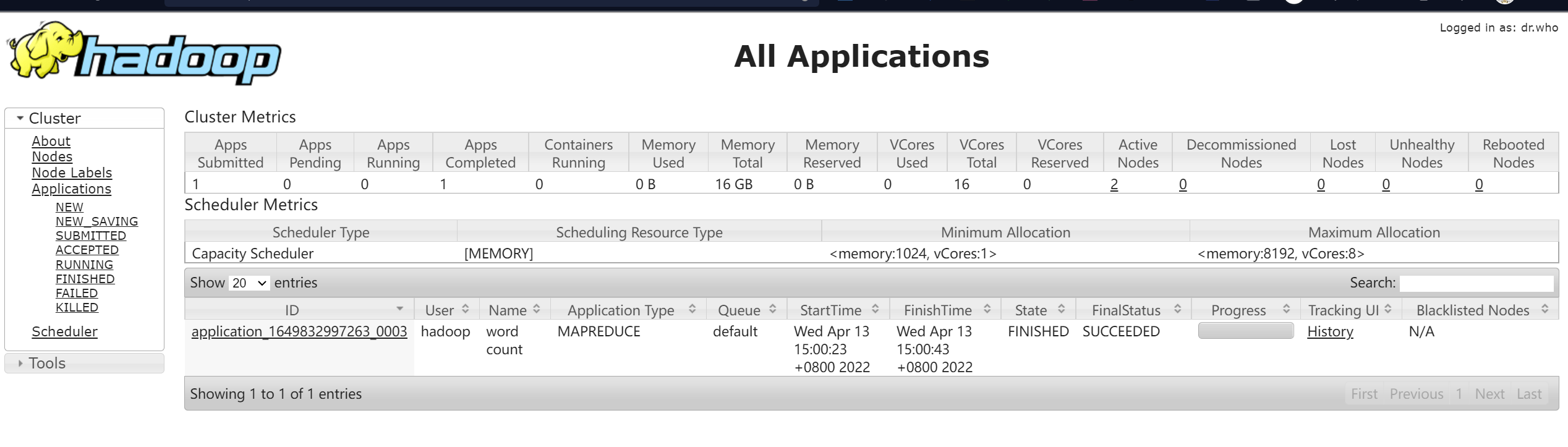
# MapReduce 作业运行过程也可以在 YARN 集群网页中查看。在浏览器的地址栏输入:
http://master:8088
# 可以使用 HDFS 命令直接查看 part-r-00000 文件内容
[hadoop@master input]$ hdfs dfs -cat /output/part-r-00000
Hadoop 1
Hello 3
Huasan 1
World 1
# 停止 Hadoop
# 1.停止yarn
[hadoop@master hadoop]$ stop-yarn.sh
# 2.停止DataNode
[hadoop@slave1 hadoop]$ hadoop-daemon.sh stop datanode
[hadoop@slave2 hadoop]$ hadoop-daemon.sh stop datanode
# 3.停止 NameNode
[hadoop@master hadoop]$ hadoop-daemon.sh stop namenode
# 4.停止 SecondaryNameNode
[hadoop@master hadoop]$ hadoop-daemon.sh stop secondarynamenode
# 4.查看 JAVA 进程,确认 HDFS 进程已全部关闭
[hadoop@master ~]$ jps
49299 Jps