Pandas数据分析基础
Pandas之所以能成为Python数据分析领域的事实标准库,是因为它对日常数据分析的便捷操作和全面覆盖。
数据读写
Pandas可以将指定格式的数据读取到DataFrame中,并将DataFrame输出为指定格式的文件。

Pandas读写函数
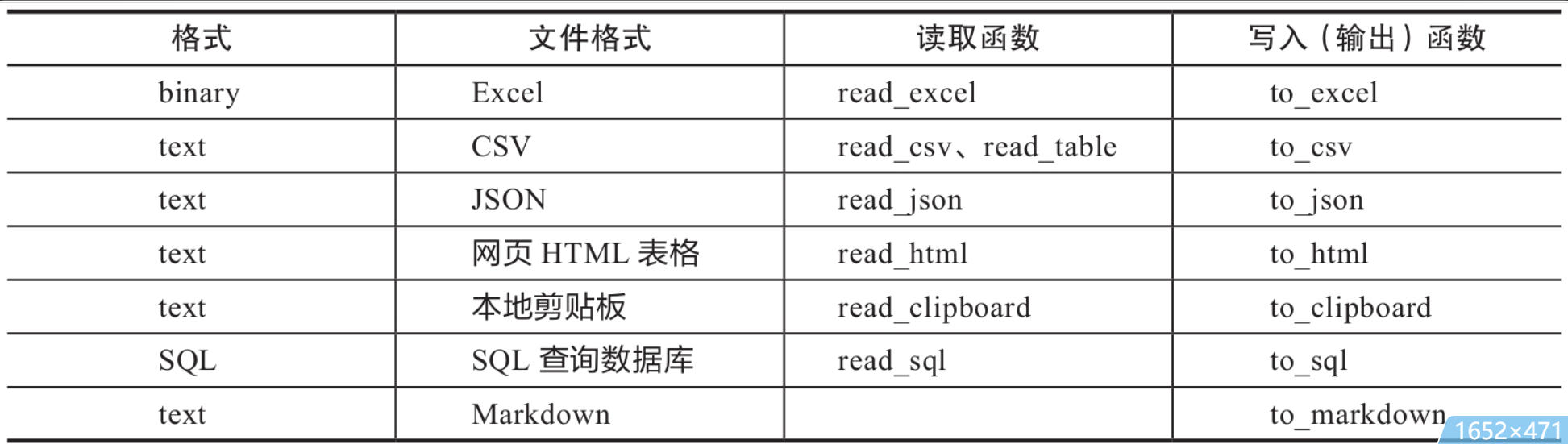
读写案例
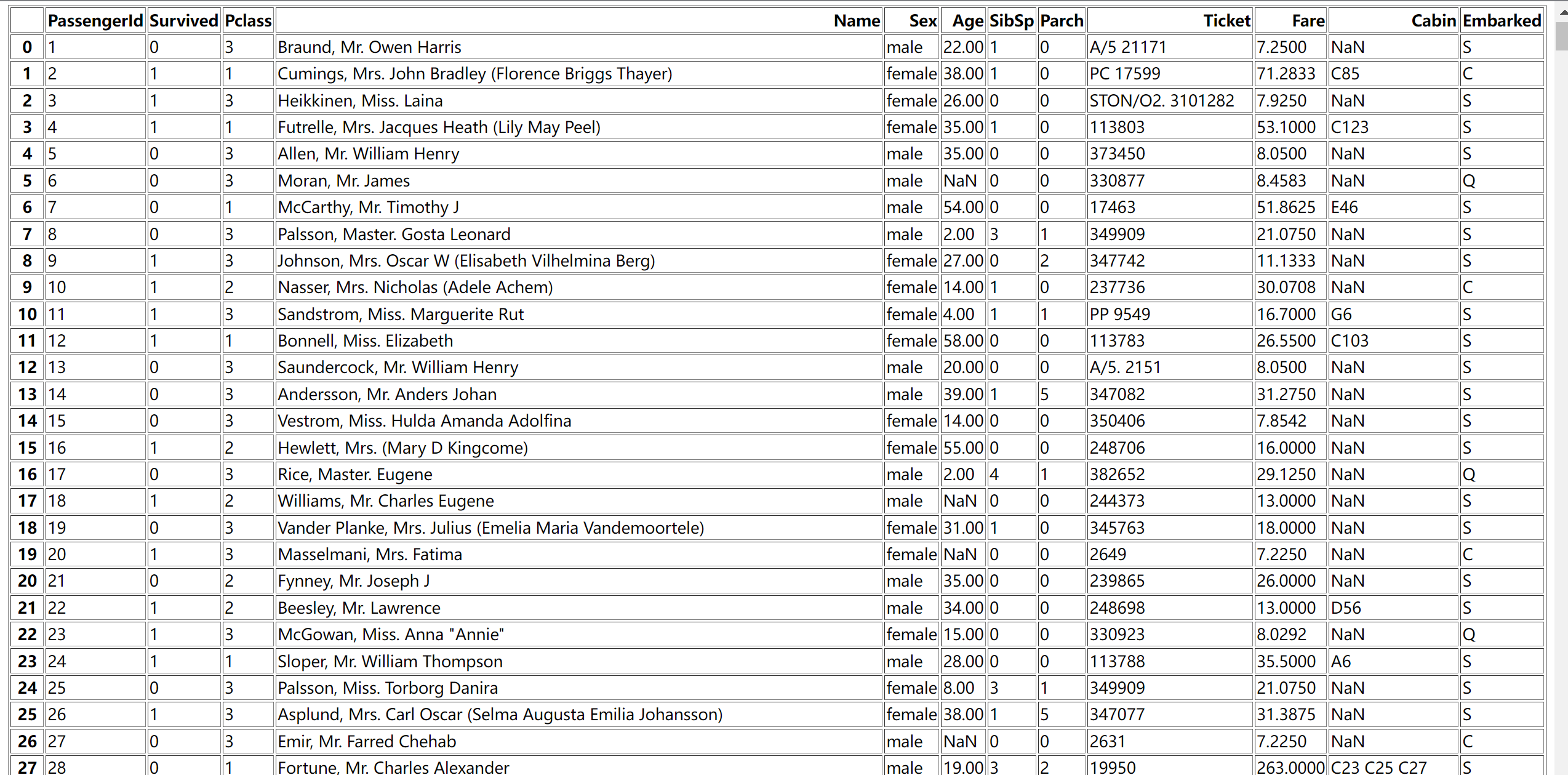
CSV 格式存储的泰坦尼克号数据集。数据由以下数据列组成:
- PassengerId:每位乘客的 ID。
- Survived: 此功能的值为 0 和 1。0 表示未存活,1 表示存活。
- Pclass: 有3个级别:1级,2级和3级。
- Name:乘客姓名。
- Sex:乘客性别。
- Age:乘客年龄。
- SibSp:表明乘客有兄弟姐妹和配偶。
- Parch:乘客是独自一人还是有家人。
- Ticket:乘客的船票号码。
- Fare:注明票价。
- Cabin:乘客的客舱。
- Embarked:已登船类别。
import pandas as pd
df = pd.read_csv('data/titanic.csv')
print(df)
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
.. ... ... ... ... ... ... ...
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns]
显示时,默认情况下将显示前 5 行和后 5 行。
# 显示前8行
print(df.head(8))
--------------------------------------------------------------------
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
6 7 0 1 ... 51.8625 E46 S
7 8 0 3 ... 21.0750 NaN S
[8 rows x 12 columns]
--------------------------------------------------------------------
使用head()方法,并将所需的行数(在本例中为 8)作为参数。
tail()将返回数据帧的最后n行例如:titanic.tail(10)。
print(df.dtypes)
--------------------------------------------------------------------
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
--------------------------------------------------------------------
pandas 每个列数据类型:dtypes属性。
将泰坦尼克号的数据输出为Excel。
df.to_excel("titanic.xlsx", sheet_name="passengers", index=False)
to_excel()方法将数据存储为 Excel 文件。在此处的sheet,命名为"passengers",而不是默认的Sheet1。通过设置行索引标签不会保存在电Excel中。
pd.read_excel("titanic.xlsx", sheet_name="passengers")
read_excel()读取excel中的数据。
df.info()
--------------------------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
--------------------------------------------------------------------
info() 显示数据的详细信息。
DataFrame.to_html会将DataFrame中的数据组装在HTML代码的table标签中,输入一个字符串,这部分HTML代码可以放在网页中进行展示,也可以作为邮件正文。
df.to_html("titanic.html")
导出成markdown文档pip install tabulate ,安装tabulate模块
df.to_markdown('titanic.md')
Panda基础操作
索引操作
Pandas数据的索引就像一本书的目录,让我们可以很快地找到想要看的章节,对于大量数据,创建合理的具有业务意义的索引对我们分析数据至关重要。
-
行索引是数据的索引,列索引指向的是一个Series;
-
DataFrame的索引也是系列形成的Series的索引;
-
建立索引让数据更加直观明确,每行数据是针对哪个主体的;
-
建立索引方便数据处理;
-
索引允许重复,但业务上一般不会让它重复。
Series只有行索引,而DataFrame对象既有行索引,也有列索引 行索引,表明不同行,横向索引,叫index,0轴,axis=0 列索引,表明不同列,纵向索引,叫columns,1轴,axis=1
建立索引
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(10).reshape(2, 5), index=list("ab"), columns=list("一二三四五"))
print(df)
--------------------------------------------------------------------
一 二 三 四 五
a 0 1 2 3 4
b 5 6 7 8 9
--------------------------------------------------------------------
temp_dict = {"name": ["Tom", "Lily"], "age": [28, 29], "tel": ["88888", "99999"]}
df = pd.DataFrame(temp_dict)
print(df)
--------------------------------------------------------------------
name age tel
0 Tom 28 88888
1 Lily 29 99999
--------------------------------------------------------------------
行和列的索引在Pandas里其实是一个Index对象,以下是创建一个Index对象的方法。
pd.Index([1, 2, 3])
# Int64Index([1, 2, 3], dtype='int64')
pd.Index(list('abc'))
# Index(['a', 'b', 'c'], dtype='object')
# 可以用name指定一个索引名称
pd.Index(['e', 'd', 'a', 'b'], name='something')
索引对象可以传入构建数据和读取数据的操作中。可以查看索引对象,列和行方向的索引对象如下:
df.index
# RangeIndex(start=0, stop=4, step=1)
df.columns
# Index(['month', 'year', 'sale'], dtype='object')
可以通过以下一系列操作查询索引的相关属性,以下方法也适用于df.columns,因为它们都是index对象。
# 常用属性
df.index.name # 名称
df.index.array # array数组
df.index.dtype # 数据类型
df.index.shape # 形状
df.index.size # 元素数量
df.index.values # array数组
# 其他,不常用
df.index.empty # 是否为空
df.index.is_unique # 是否不重复
df.index.names # 名称列表
df.index.is_all_dates # 是否全是日期时间
df.index.has_duplicates # 是否有重复值
df.index.values # 索引的值array
以下是索引的常用操作,这些操作会在我们今后处理数据中发挥作用。以下方法也适用于df.columns,因为都是index对象。
# 常用方法
df.index.astype('int64') # 转换类型
df.index.isin() # 是否存在,见下方示例
df.index.rename('number') # 修改索引名称
df.index.nunique() # 不重复值的数量
df.index.sort_values(ascending=False,) # 排序,倒序
df.index.map(lambda x:x+'_') # map函数处理
df.index.str.replace('_', '') # str替换
df.index.str.split('_') # 分隔
df.index.to_list() # 转为列表
df.index.to_frame(index=False, name='a') # 转成DataFrame
df.index.to_series() # 转为series
df.index.to_numpy() # 转为numpy
df.index.unique() # 去重
df.index.value_counts() # 去重及计数
df.index.where(df.index=='a') # 筛选
df.index.rename('grade', inplace=False) # 重命名索引
df.index.rename(['species', 'year']) # 多层,重命名索引
df.index.max() # 最大值
df.index.argmax() # 最大索引值
df.index.any()
df.index.all()
df.index.T # 转置,在多层索引里很有用
索引重命名
s.rename_axis("student_name") # 索引重命名
df.rename_axis(["dow", "hr"]) # 多层索引修改索引名
df.rename_axis('info', axis="columns") # 修改行索引名
# 修改多层列索引名
df.rename_axis(index={'a': 'A', 'b': 'B'})
# 修改多层列索引名
df.rename_axis(columns={'name': 's_name', 'b': 'B'})
df.rename_axis(columns=str.upper) # 行索引名变大写
# 一一对应修改列索引
df.rename(columns={"A": "a", "B": "c"})
df.rename(str.lower, axis='columns')
# 修改行索引
df.rename(index={0: "x", 1: "y", 2: "z"})
df.rename({1: 2, 2: 4}, axis='index')
# 修改数据类型
df.rename(index=str)
# 重新修改索引
replacements = {l1:l2 for l1, l2 in zip(list1, list2)}
df.rename(replacements)
# 列名加前缀
df.rename(lambda x:'t_' + x, axis=1)
# 利用iter()函数的next特性修改
df.rename(lambda x, y=iter('abcdef'): next(y), axis=1)
# 修改列名,用解包形式生成新旧字段字典
df.rename(columns=dict(zip(df, list('abcd'))))
# 修改索引
df.set_axis(['a', 'b', 'c'], axis='index')
# 修改列名
df.set_axis(list('abcd'), axis=1)
# 使修改生效
df.set_axis(['a', 'b'], axis='columns', inplace=True)
# 传入索引内容
df.set_axis(pd.Index(list('abcde')), axis=0)
查看数据信息
df.head(10) # 查看前10条数据
s.tail() # 查看后5条数据
df.tail(10) # 查看后10条数据
df.sample() # 随机查看一条数据
s.sample(3) # 随机查看3条数据
数据形状
执行df.shape会返回一个元组,该元组的第一个元素代表行数,第二个元素代表列数,这就是这个数据的基本形状,也是数据的大小。
df.shape
# (100, 6)
# 共100行6列(索引不算)
# Series 只有一个值
s.shape
# (100,)
基础信息
执行df.info会显示所有数据的类型、索引情况、行列数、各字段数据类型、内存占用等。Series不支持。
执行df.info会显示所有数据的类型、索引情况、行列数、各字段数据类型、内存占用等。Series不支持。
df.axes会返回一个列内容和行内容组成的列表[列索引, 行索引]。
# 索引对象
df.index
# RangeIndex(start=0, stop=100, step=1)
# 列索引,Series不支持
df.columns
# Index(['name', 'team', 'Q1', 'Q2', 'Q3', 'Q4'], dtype='object')
df.values # array(<所有值的列表矩阵>)
df.ndim # 2 维度数
df.size # 600行×列的总数,就是总共有多少数据
# 是否为空,注意,有空值不认为是空
df.empty # False
# Series的索引,DataFrame的列名
df.keys()
Series独有以下方法:
s.name # 'Q1'
s.array # 值组成的数组 <PandasArray>
s.dtype # 类型,dtype('int64')
s.hasnans # False
统计计算
Pandas可以对Series与DataFrame进行快速的描述性统计,如求和、平均数、最大值、方差等,这些是最基础也最实用的统计方法。对于DataFrame,这些统计方法会按列进行计算,最终产出一个以列名为索引、以计算值为值的Series。
df.describe()会返回一个有多行的所有数字列的统计表,每一行对应一个统计指标,有总数、平均数、标准差、最小值、四分位数、最大值等,这个表对我们初步了解数据很有帮助。
df.describe()
'''
Q1 Q2 Q3 Q4
count 100.000000 100.000000 100.000000 100.000000
mean 49.200000 52.550000 52.670000 52.780000
std 29.962603 29.845181 26.543677 27.818524
min 1.000000 1.000000 1.000000 2.000000
25% 19.500000 26.750000 29.500000 29.500000
50% 51.500000 49.500000 55.000000 53.000000
75% 74.250000 77.750000 76.250000 75.250000
max 98.000000 99.000000 99.000000 99.000000
'''
数学统计
Pandas支持常用的数学统计方法,如平均数、中位数、众数、方差等,还可以结合NumPy使用其更加丰富的统计功能
我们先来使用mean()计算一下平均数,DataFrame使用统计函数后会生成一个Series,这个Series的索引为每个数字类型列的列名,值为此列的平均数。如果DataFrame没有任何数字类型列,则会报错。
df.mean()
'''
Q1 49.20
Q2 52.55
Q3 52.67
Q4 52.78
dtype: float64
'''
type(df.mean())
# pandas.core.series.Series
如果我们希望按行计算平均数,即数据集中每个学生Q1到Q4的成绩的平均数,可以传入axis参数,列传index或0,行传columns或1:
df.mean(axis='columns')
df.mean(axis=1) # 效果同上
df.mean(1) # 效果同上
'''
0 49.50
1 41.75
2 54.75
3 84.50
4 65.25
...
95 67.00
96 31.25
97 53.00
98 58.50
99 44.75
Length: 100, dtype: float64
'''
统计函数
df.mean() # 返回所有列的均值
df.mean(1) # 返回所有行的均值,下同
df.corr() # 返回列与列之间的相关系数
df.count() # 返回每一列中的非空值的个数
df.max() # 返回每一列的最大值
df.min() # 返回每一列的最小值
df.abs() # 绝对值
df.median() # 返回每一列的中位数
df.std() # 返回每一列的标准差,贝塞尔校正的样本标准偏差
df.var() # 无偏方差
df.sem() # 平均值的标准误差
df.mode() # 众数
df.prod() # 连乘
df.mad() # 平均绝对偏差
df.cumprod() # 累积连乘,累乘
df.cumsum(axis=0) # 累积连加,累加
df.nunique() # 去重数量,不同值的量
df.idxmax() # 每列最大值的索引名
df.idxmin() # 每列最小值的索引名
df.cummax() # 累积最大值
df.cummin() # 累积最小值
df.skew() # 样本偏度(第三阶)
df.kurt() # 样本峰度(第四阶)
df.quantile() # 样本分位数(不同 % 的值)
Pandas还提供了一些特殊的用法:
# 很多支持指定行列(默认是axis=0列)等参数
df.mean(1) # 按行计算
# 很多函数均支持
df.sum(0, skipna=False) # 不除缺失数据
# 很多函数均支持
df.sum(level='blooded') # 索引级别
df.sum(level=0)
# 执行加法操作所需的最小有效值数
df.sum(min_count=1)
非统计计算
df.all() # 返回所有列all()值的Series
df.any()
# 四舍五入
df.round(2) # 指定字段指定保留小数位,如有
df.round({'Q1': 2, 'Q2': 0})
df.round(-1) # 保留10位
# 每个列的去重值的数量
df.nunique()
s.nunique() # 本列的去重值
# 真假检测
df.isna() # 值的真假值替换
df.notna() # 与上相反
df + 1 # 等运算
df.add() # 加
df.sub() # 减
df.mul() # 乘
df.div() # 除
df.mod() # 模,除后的余数
df.pow() # 指数幂
df.dot(df2) # 矩阵运算
以下是Series专有的一些函数:
# 不重复的值及数量
s.value_counts()
s.value_counts(normalize=True) # 重复值的频率
s.value_counts(sort=False) # 不按频率排序
s.unique() # 去重的值 array
s.is_unique # 是否有重复
# 最大最小值
s.nlargest() # 最大的前5个
s.nlargest(15) # 最大的前15个
s.nsmallest() # 最小的前5个
s.nsmallest(15) # 最小的前15个
s.pct_change() # 计算与前一行的变化百分比
s.pct_change(periods=2) # 前两行
s1.cov(s2) # 两个序列的协方差
位置计算
diff()和shift()经常用来计算数据的增量变化,rank()用来生成数据的整体排名。
df.diff()可以做位移差操作,经常用来计算一个序列数据中上一个数据和下一个数据之间的差值,如增量研究。默认被减的数列下移一位,原数据在同位置上对移动后的数据相减,得到一个新的序列,第一位由于被减数下移,没有数据,所以结果为NaN。可以传入一个数值来规定移动多少位,负数代表移动方向相反。Series类型如果是非数字,会报错,DataFrame会对所有数字列移动计算,同时不允许有非数字类型列。
pd.Series([9, 4, 6, 7, 9])
'''
0 9
1 4
2 6
3 7
4 9
dtype: int64
'''
# 后面与前面的差值
pd.Series([9, 4, 6, 7, 9]).diff()
'''
0 NaN
1 -5.0
2 2.0
3 1.0
4 2.0
dtype: float64
'''
# 后方向,移动两位求差值
pd.Series([9, 4, 6, 7, 9]).diff(-2)
'''
0 3.0
1 -3.0
2 -3.0
3 NaN
4 NaN
dtype: float64
'''
对于DataFrame,还可以传入axis=1进行左右移动:
# 只筛选4个季度的5条数据
df.loc[:5,'Q1':'Q4'].diff(1, axis=1)
'''
Q1 Q2 Q3 Q4
0 NaN -68.0 3.0 40.0
1 NaN 1.0 0.0 20.0
2 NaN 3.0 -42.0 66.0
3 NaN 3.0 -25.0 7.0
4 NaN -16.0 12.0 25.0
5 NaN -11.0 74.0 -44.0
'''
shift()可以对数据进行移位,不做任何计算,也支持上下左右移动,移动后目标位置的类型无法接收的为NaN。
# 整体下移一行,最顶的一行为NaN
df.shift()
df.shift(3) # 移三行
# 整体上移一行,最底的一行为NaN
df.Q1.head().shift(-1)
# 向右移动一位
df.shift(axis=1)
df.shift(3, axis=1) # 移三位
# 向左移动一位
df.shift(-1, axis=1)
# 实现了df.Q1.diff()
df.Q1 - df.Q1.shift()
rank()可以生成数据的排序值替换掉原来的数据值,它支持对所有类型数据进行排序,如英文会按字母顺序。使用rank()的典型例子有学生的成绩表,给出排名:
# 排名,将值变了序号
df.head().rank()
'''
name team Q1 Q2 Q3 Q4
0 4.0 5.0 4.0 1.0 2.0 2.0
1 2.0 2.5 1.0 2.0 3.0 1.0
2 1.0 1.0 2.0 4.0 1.0 4.0
3 3.0 2.5 5.0 5.0 5.0 3.0
4 5.0 4.0 3.0 3.0 4.0 5.0
'''
# 横向排名
df.head().rank(axis=1)
'''
Q1 Q2 Q3 Q4
0 4.0 1.0 2.0 3.0
1 1.0 2.5 2.5 4.0
2 2.0 3.0 1.0 4.0
3 3.0 4.0 1.0 2.0
4 3.0 1.0 2.0 4.0
'''
df.head().rank(pct=True)
'''
name team Q1 Q2 Q3 Q4
0 0.8 1.0 0.8 0.2 0.4 0.4
1 0.4 0.5 0.2 0.4 0.6 0.2
2 0.2 0.2 0.4 0.8 0.2 0.8
3 0.6 0.5 1.0 1.0 1.0 0.6
4 1.0 0.8 0.6 0.6 0.8 1.0
'''
数据选择
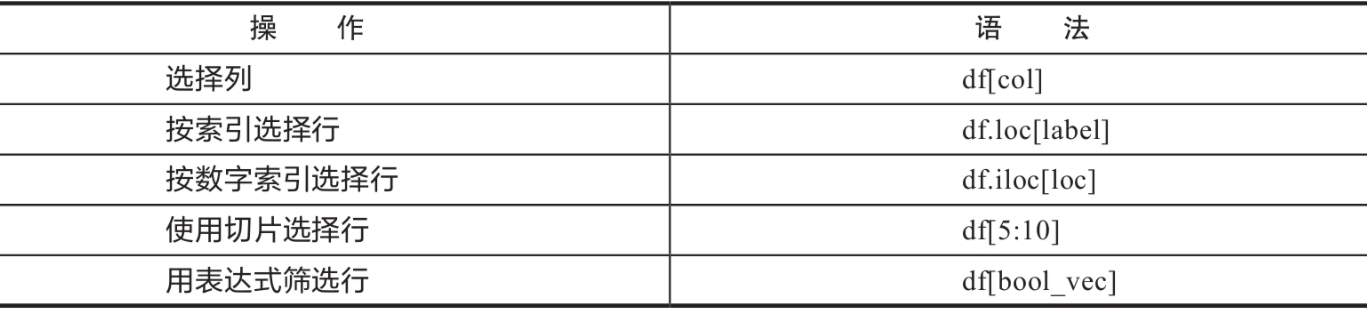
以下两种方法都可以取一列数据,得到的数据类型为Series:
df['name'] # 会返回本列的Series, 下同
df.name
df.Q1
'''
0 89
1 36
2 57
3 93
4 65
..
95 48
96 21
97 98
98 11
99 21
Name: Q1, Length: 100, dtype: int64
'''
type(df.Q1)
# pandas.core.series.Series
df[:2] # 前两行数据
df[4:10]
df[:] # 所有数据,一般不这么用
df[:10:2] # 按步长取
s[::-1] # 反转顺序
df[2] # 报错!
切片的逻辑和Python列表的逻辑一样,不包括右边的索引值。如果切片里是一个列名组成的列表,则可筛选出这些列:
df[['name','Q4']]
'''
name Q4
0 Liver 64
1 Arry 57
2 Ack 84
3 Eorge 78
4 Oah 86
.. ... ..
95 Gabriel 74
96 Austin7 43
97 Lincoln4 20
98 Eli 91
99 Ben 74
[100 rows x 2 columns]
'''
按轴标签.loc
df.loc的格式是df.loc[<行表达式>, <列表达式>],如列表达式部分不传,将返回所有列,Series仅支持行表达式进行索引的部分。loc操作通过索引和列的条件筛选出数据。如果仅返回一条数据,则类型为Series。
# 代表索引,如果是字符,需要加引号
df.loc[0] # 选择索引为0的行
df.loc[8]
# 索引为name
df.set_index('name').loc['Ben']
'''
team E
Q1 21
Q2 43
Q3 41
Q4 74
Name: Ben, dtype: object
'''
df.loc[[0,5,10]] # 指定索引为0,5,10的行
'''
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
5 Harlie C 24 13 87 43
10 Leo B 17 4 33 79
'''
df.set_index('name').loc[['Eli', 'Ben']] # 两位学生,索引是name
df.loc[[False, True]*50] # 为真的列显示,隔一个显示一个
df.loc[0:5] # 索引切片,代表0~5行,包括5
df.loc['2010':'2014'] # 如果索引是时间,可以用字符查询,第14章会介绍
df.loc[:] # 所有
# 本方法支持Series
df.loc[0:5, ['name', 'Q2']]
'''
name Q2
0 Liver 21
1 Arry 37
2 Ack 60
3 Eorge 96
4 Oah 49
5 Harlie 13
'''
df.loc[0:9, ['Q1', 'Q2']] # 前10行,Q1和Q2两列
df.loc[:, ['Q1', 'Q2']] # 所有行,Q1和Q2两列
df.loc[:10, 'Q1':] # 0~10行,Q1后边的所有列
df.loc[:, :] # 所有内容
按数字索引.iloc
df.iloc[:3] # 前三行
s.iloc[:3] # 序列中的前三个
df.iloc[:] # 所有数据
df.iloc[2:20:3] # 步长为3
df.iloc[:3, [0,1]] # 前两列
df.iloc[:3, :] # 所有列
df.iloc[:3, :-2] # 从右往左第三列以左的所有列
如果需要取数据中一个具体的值,就像取平面直角坐标系中的一个点一样,可以使用.at[]来实现。.at类似于loc,仅取一个具体的值,结构为df.at[<索引>,<列名>]。如果是一个Series,可以直接值入索引取到该索引的值。
# 注:索引是字符,需要加引号
df.at[4, 'Q1'] # 65
df.set_index('name').at['Ben', 'Q1'] # 21 索引是name
df.at[0, 'name'] # 'Liver'
df.loc[0].at['name'] # 'Liver'
# 指定列的值对应其他列的值
df.set_index('name').at['Eorge', 'team'] # 'C'
df.set_index('name').team.at['Eorge'] # 'C'
# 指定列的对应索引的值
df.team.at[3] # 'C'
获取数据.get
.get可以做类似字典的操作,如果无值,则返回默认值(下例中是0)。格式为df.get(key,default=None),如果是DataFrame,key需要传入列名,返回的是此列的Series;如果是Series,需要传入索引,返回的是一个定值:
df.get('name', 0) # 是name列
df.get('nameXXX', 0) # 0,返回默认值
s.get(3, 0) # 93,Series传索引返回具体值
df.name.get(99, 0) # 'Ben'
df.truncate(before=2, after=4)
'''
name team Q1 Q2 Q3 Q4
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
'''
s.truncate(before=2, after=4)
'''
0 89
1 36
2 57
3 93
4 65
Name: Q1, dtype: int64
'''
df.loc[pd.IndexSlice[:, ['Q1', 'Q2']]]
# 变量化使用
idx = pd.IndexSlice
df.loc[idx[:, ['Q1', 'Q2']]]
df.loc[idx[:, 'Q1':'Q4'], :] # 多索引
# 创建复杂条件选择器
selected = df.loc[(df.team=='A') & (df.Q1>90)]
idxs = pd.IndexSlice[selected.index, 'name']
# 应用选择器
df.loc[idxs]
# 选择这部分区域加样式
df.style.applymap(style_fun, subset=idxs)