函数进阶
Python 函数的进阶特性(如灵活的参数处理、闭包、装饰器)和高阶函数是提升代码灵活性与复用性的核心,尤其在模块化编程和函数式编程中不可或缺。
一、函数参数的进阶用法
除了基础的位置参数、默认参数,Python 还支持可变参数和关键字可变参数,用于处理不确定数量的输入。
1. 可变参数(*args)
接收任意数量的位置参数,在函数内部被包装为一个元组(tuple)。
- 语法:在参数名前加 *(通常用 args 作为参数名,非强制)。
示例:计算任意多个数的和
def sum_all(*args):
"""计算所有传入参数的和"""
print("参数类型:", type(args)) # <class 'tuple'>
total = 0
for num in args:
total += num
return total
print(sum_all(1, 2, 3)) # 传入3个参数 → 6
print(sum_all(10, 20, 30, 40)) # 传入4个参数 → 100
print(sum_all()) # 可传入0个参数 → 0
- 若已有列表/元组,可通过
*解包后传入:
nums = [1, 2, 3, 4]
print(sum_all(*nums)) # 等价于 sum_all(1,2,3,4) → 10
2. 关键字可变参数(**kwargs)
接收任意数量的关键字参数(key=value 形式),在函数内部被包装为一个字典(dict)。
- 语法:在参数名前加 **(通常用 kwargs 作为参数名,非强制)。
示例:打印用户信息(支持任意字段)
def print_user(** kwargs):
"""打印用户信息,支持任意关键字参数"""
print("参数类型:", type(kwargs)) # <class 'dict'>
for key, value in kwargs.items():
print(f"{key}: {value}")
print_user(name="小明", age=18, gender="男")
# 输出:
# name: 小明
# age: 18
# gender: 男
print_user(id=1001, score=90) # 传入不同的关键字参数
- 若已有字典,可通过
**解包后传入:
user_info = {"name": "小红", "age": 20}
print_user(** user_info) # 等价于 print_user(name="小红", age=20)
3. 参数组合顺序
当多种参数共存时,需遵循固定顺序:
位置参数 → 可变参数(*args) → 默认参数 → 关键字可变参数(**kwargs)
def func(a, b, *args, c=0, **kwargs):
print(f"位置参数:a={a}, b={b}")
print(f"可变参数:args={args}")
print(f"默认参数:c={c}")
print(f"关键字可变参数:kwargs={kwargs}")
func(1, 2, 3, 4, c=5, d=6, e=7)
# 输出:
# 位置参数:a=1, b=2
# 可变参数:args=(3, 4)
# 默认参数:c=5
# 关键字可变参数:kwargs={'d': 6, 'e': 7}
二、函数嵌套与闭包
1. 函数嵌套
在一个函数内部定义另一个函数(内部函数仅在外部函数内可见),用于封装细节逻辑。
def outer():
print("这是外部函数")
def inner(): # 内部函数
print("这是内部函数")
inner() # 外部函数内调用内部函数
outer()
# 输出:
# 这是外部函数
# 这是内部函数
# inner() # 报错:外部无法直接调用内部函数
2. 闭包(Closure)
若内部函数引用了外部函数的变量,且外部函数返回内部函数,则内部函数称为“闭包”。闭包可“记住”外部函数的变量状态。
核心作用:保存外部函数的局部变量,避免全局变量污染。
示例:实现一个计数器(每次调用自增1)
def make_counter():
count = 0 # 外部函数的局部变量(被闭包引用)
def counter():
nonlocal count # 声明引用外部函数的变量(非全局)
count += 1
return count
return counter # 返回内部函数(闭包)
# 创建计数器实例
counter1 = make_counter()
print(counter1()) # 1(第一次调用,count=1)
print(counter1()) # 2(第二次调用,count=2)
# 再创建一个独立的计数器
counter2 = make_counter()
print(counter2()) # 1(与counter1的count独立)
nonlocal关键字:用于在内部函数中修改外部函数的局部变量(若无nonlocal,直接赋值会被视为内部函数的局部变量)。
三、装饰器(Decorator)
装饰器是闭包的高级应用,用于在不修改原函数代码的前提下,给函数添加额外功能(如日志、计时、权限验证等)。
本质
装饰器是一个高阶函数,它接收原函数作为参数,返回一个新的函数(包装了原函数的增强版本)。
1. 基础装饰器
示例:给函数添加“执行时间统计”功能
import time
# 定义装饰器(高阶函数)
def timer(func):
def wrapper(*args, **kwargs): # 接收任意参数(适配原函数的参数)
start = time.time() # 前置操作:记录开始时间
result = func(*args, **kwargs) # 调用原函数
end = time.time() # 后置操作:记录结束时间
print(f"{func.__name__} 执行时间:{end - start:.4f}秒")
return result # 返回原函数的结果
return wrapper # 返回包装后的函数
# 使用装饰器(@语法糖,等价于:func = timer(func))
@timer
def slow_function(n):
time.sleep(n) # 模拟耗时操作
return n
# 调用被装饰的函数
slow_function(1) # 输出:slow_function 执行时间:1.0012秒(示例值)
@timer是语法糖,等价于slow_function = timer(slow_function),即把原函数传给装饰器,再用返回的新函数覆盖原函数名。
2. 带参数的装饰器
若装饰器需要自定义参数(如日志等级),需在基础装饰器外再嵌套一层函数。
示例:带“前缀”参数的日志装饰器
def logger(prefix):
def decorator(func):
def wrapper(*args, **kwargs):
print(f"[{prefix}] 调用函数:{func.__name__}")
result = func(*args, **kwargs)
return result
return wrapper
return decorator
# 使用带参数的装饰器
@logger(prefix="INFO")
def add(a, b):
return a + b
add(3, 5) # 输出:[INFO] 调用函数:add → 返回8
四、高阶函数(Higher-Order Function)
定义:满足以下任一条件的函数:
1.接收函数作为参数;
2.返回函数作为结果。
1. 常见内置高阶函数
(1)map(func, iterable)
将函数 func 应用到可迭代对象 iterable 的每个元素,返回一个迭代器(需转换为列表查看结果)。
示例:计算列表中每个元素的平方
nums = [1, 2, 3, 4]
# 定义处理函数
def square(x):
return x** 2
# 用map应用函数
result = map(square, nums)
print(list(result)) # [1, 4, 9, 16]
- 配合匿名函数
lambda更简洁:
print(list(map(lambda x: x**2, nums))) # [1, 4, 9, 16]
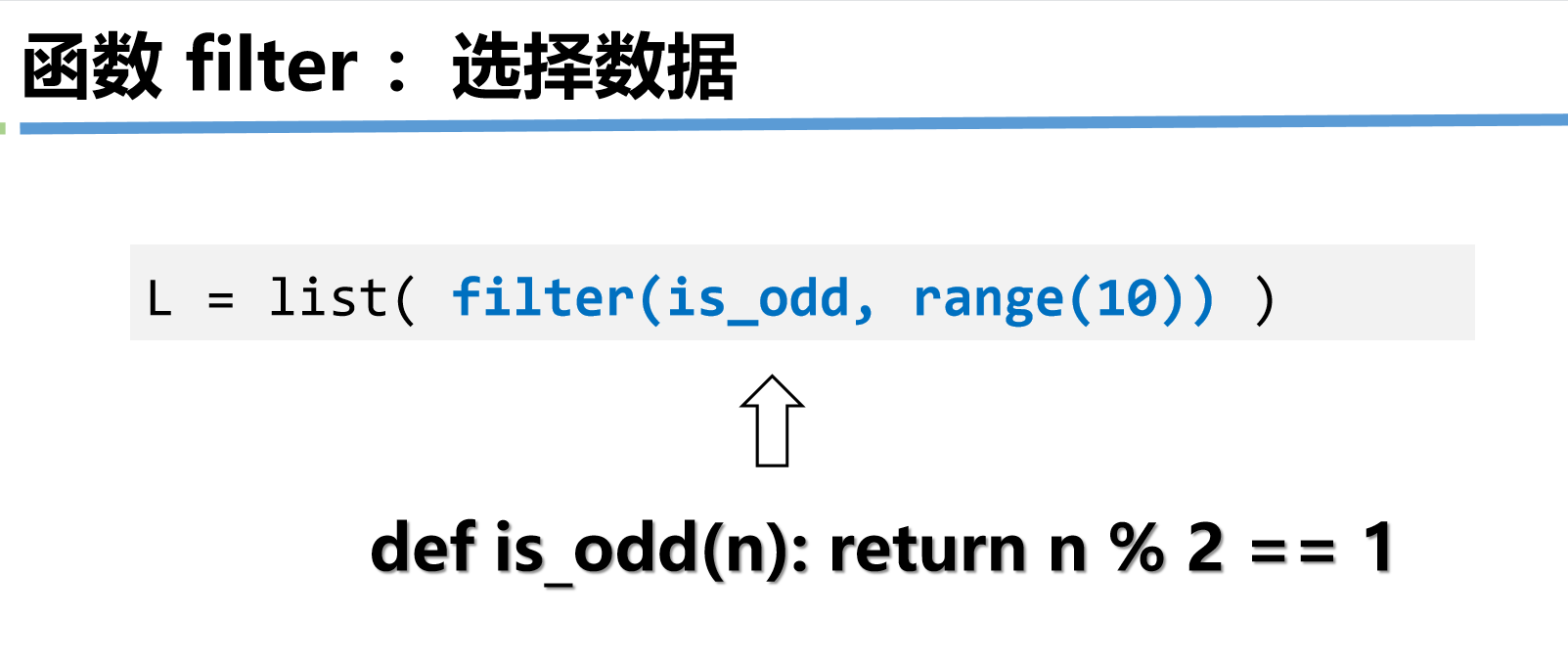
(2)filter(func, iterable)
筛选出可迭代对象中使 func 返回 True 的元素,返回迭代器。
示例:筛选列表中的偶数
nums = [1, 2, 3, 4, 5, 6]
# 定义筛选函数(返回布尔值)
def is_even(x):
return x % 2 == 0
# 用filter筛选
result = filter(is_even, nums)
print(list(result)) # [2, 4, 6]
- 匿名函数简化:
print(list(filter(lambda x: x%2 == 0, nums))) # [2, 4, 6]
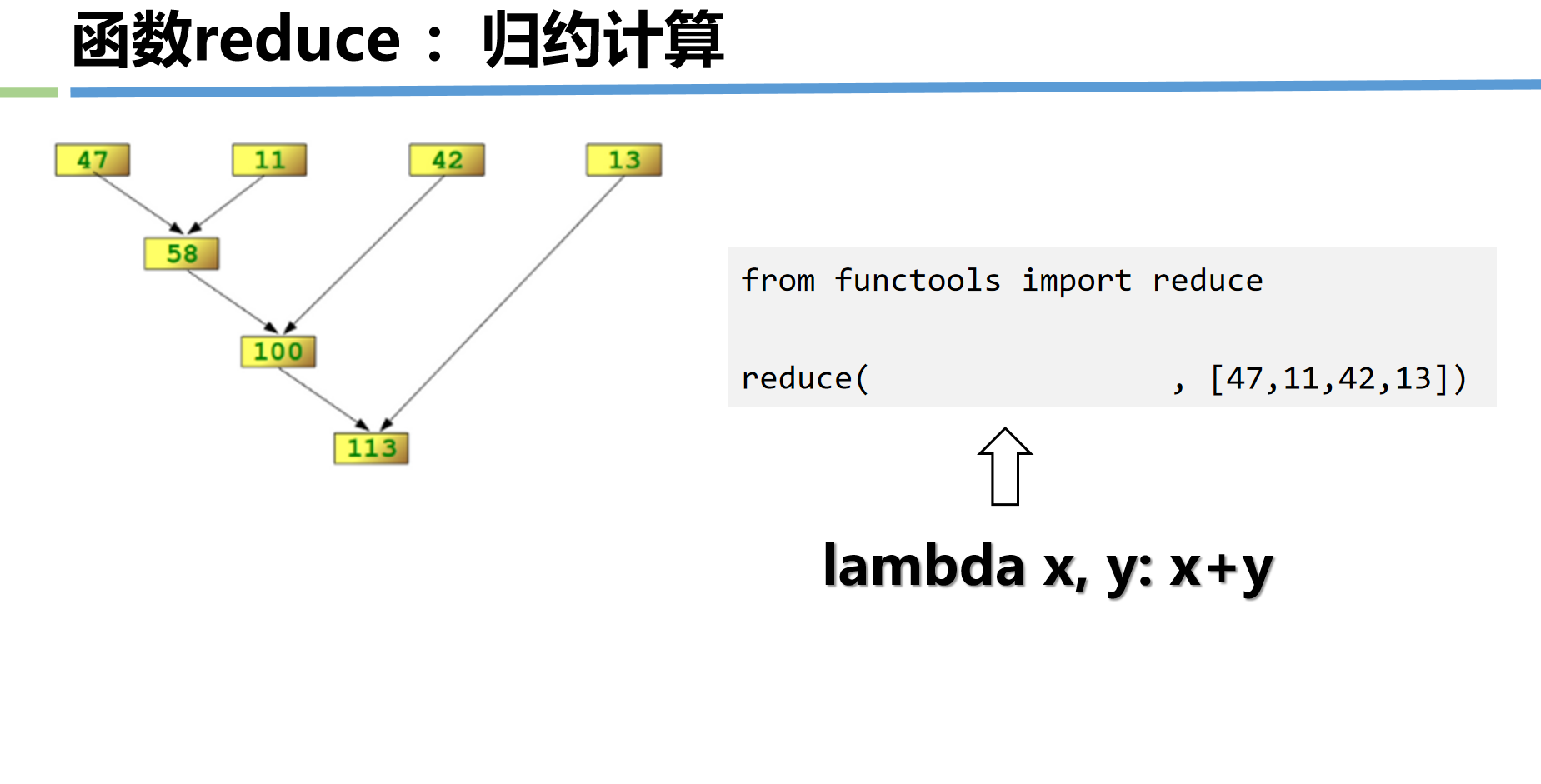
(3)reduce(func, iterable, [initial])
从 functools 模块导入,对可迭代对象进行累积操作(用 func 依次处理前两个元素,结果与下一个元素继续处理)。
示例:计算列表所有元素的乘积
from functools import reduce
nums = [1, 2, 3, 4]
# 定义累积函数(接收两个参数,返回一个结果)
def multiply(a, b):
return a * b
# 用reduce累积
result = reduce(multiply, nums)
print(result) # 1*2*3*4 = 24
- 匿名函数简化:
print(reduce(lambda a,b: a*b, nums)) # 24
(4)sorted(iterable, key=func, reverse=False)
对可迭代对象排序,key 参数接收一个函数,用于指定排序依据(高阶函数特性)。
示例:按字符串长度排序
words = ["apple", "banana", "cat", "dog"]
# 按字符串长度排序(key=len 表示用len函数的结果作为排序依据)
sorted_words = sorted(words, key=len)
print(sorted_words) # ['cat', 'dog', 'apple', 'banana'](长度:3→3→5→6)
2. 自定义高阶函数
示例:定义一个高阶函数,接收函数和两个数,返回函数处理后的结果
def apply_func(func, a, b):
"""将函数func应用到a和b,返回结果"""
return func(a, b)
# 传入不同函数实现不同功能
print(apply_func(lambda x,y: x+y, 3, 5)) # 8(加法)
print(apply_func(lambda x,y: x*y, 3, 5)) # 15(乘法)
print(apply_func(lambda x,y: x**y, 3, 5)) # 243(幂运算)
总结
- 参数进阶:
*args和**kwargs处理可变参数,灵活适配不同输入场景。 - 闭包:通过嵌套函数保存外部变量状态,为装饰器提供基础。
- 装饰器:不修改原函数即可增强功能,常用于日志、计时、权限控制。
- 高阶函数:接收或返回函数,如
map/filter/reduce实现通用数据处理逻辑,提升代码抽象能力。
掌握这些特性,能写出更简洁、模块化、可扩展的 Python 代码,尤其在框架开发和函数式编程中至关重要。
高阶函数
在函数式编程中,可以把函数当作变量⼀样自由使用。⼀个函数接收另⼀个函数作为参数,这种函数称之为高阶函数(Higher-order Functions)。
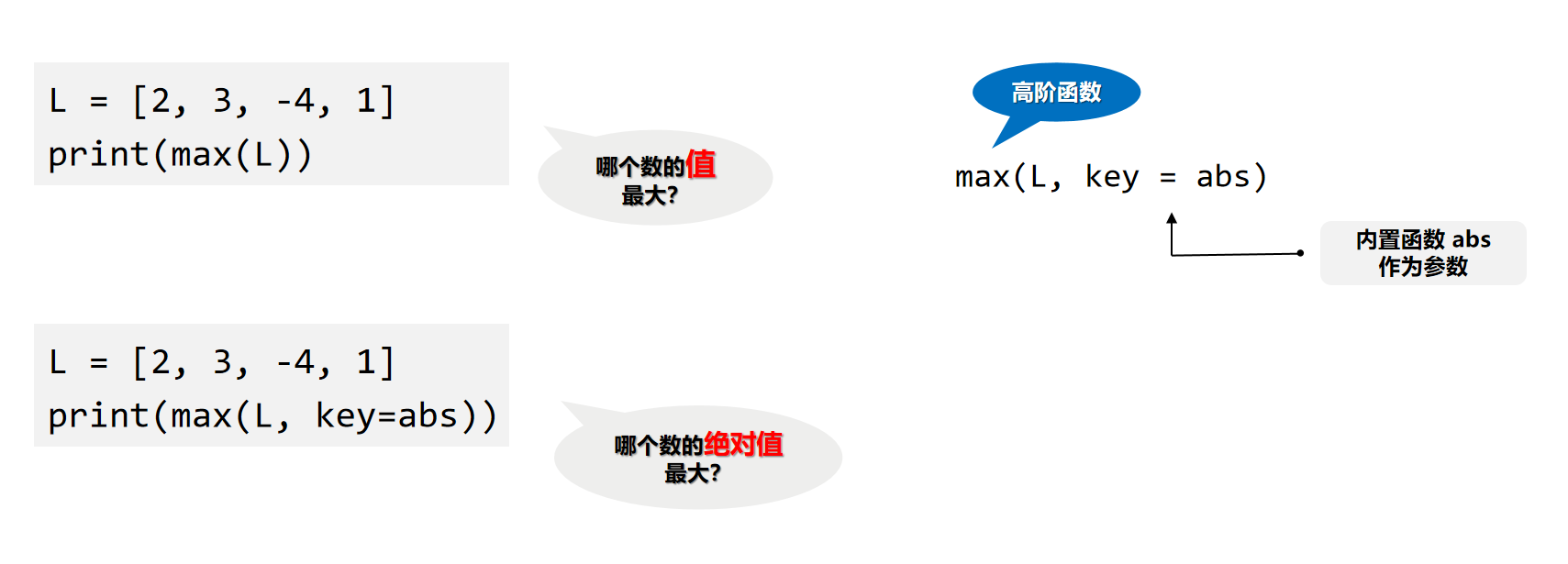
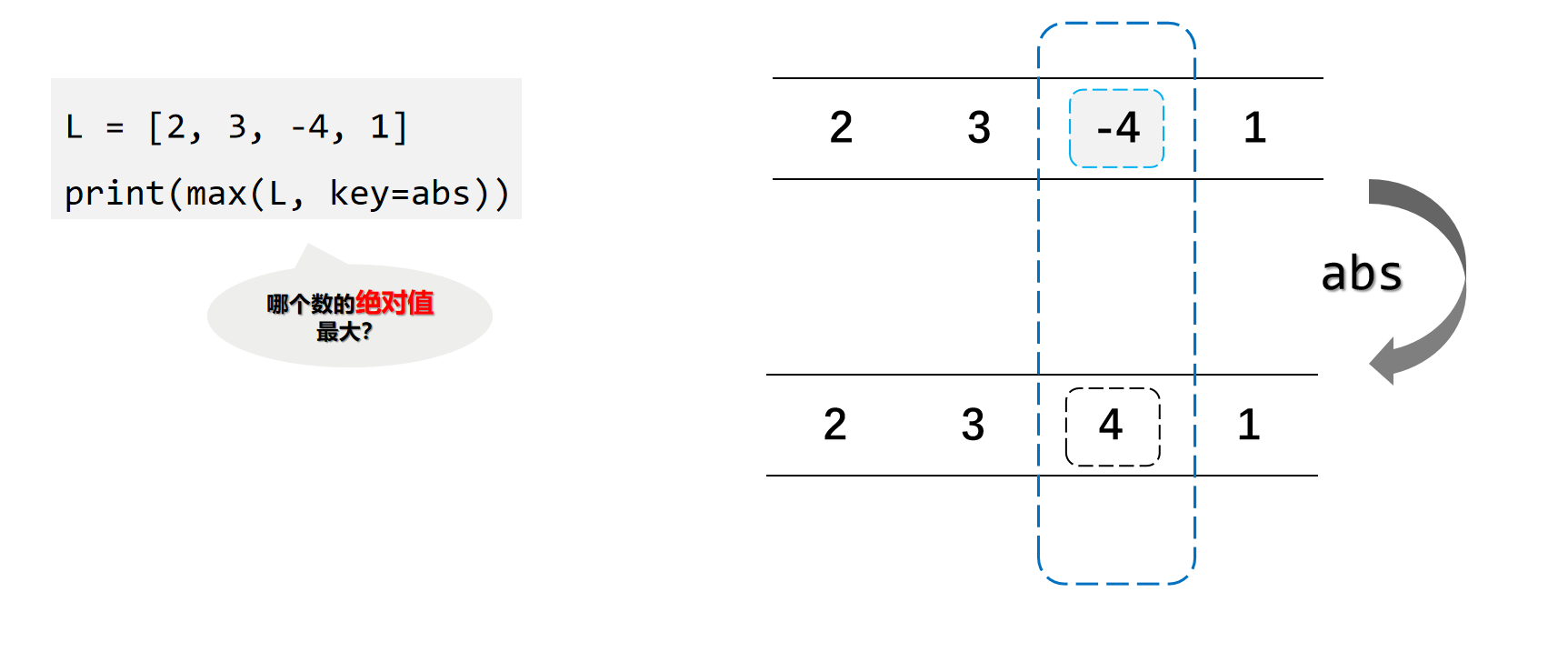

编写自己的高阶函数

匿名函数 lambda
- 只用一次
- 让代码更简洁
在Python中,如果一个函数的函数体非常简单,我们可以使用lambda来创建匿名函数。例如,求某数的n次方的函数,可以这样定义:
power = lambda a,n:a**n
让代码变得更简洁


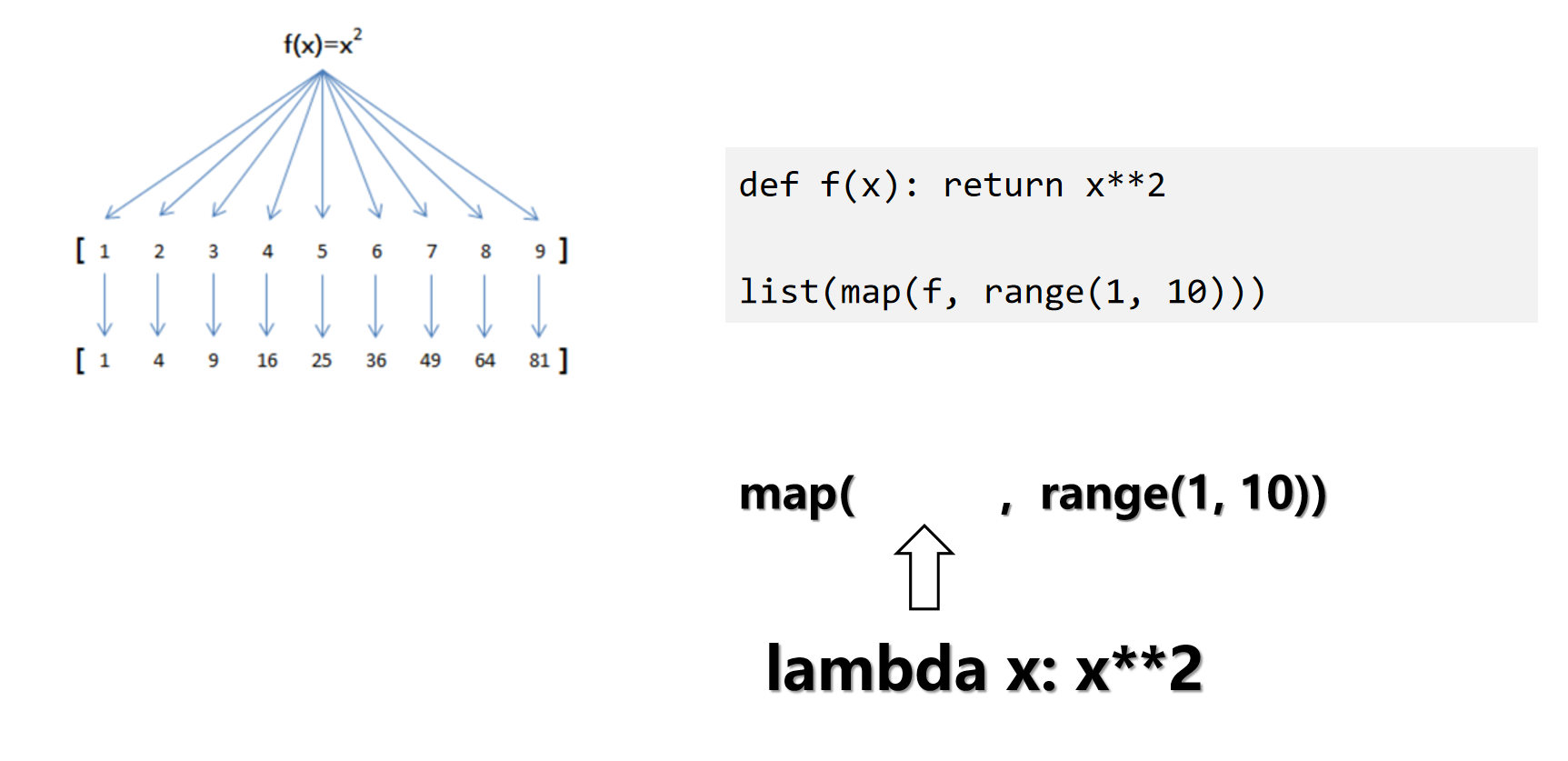
函数式编程

函数 map :映射序列
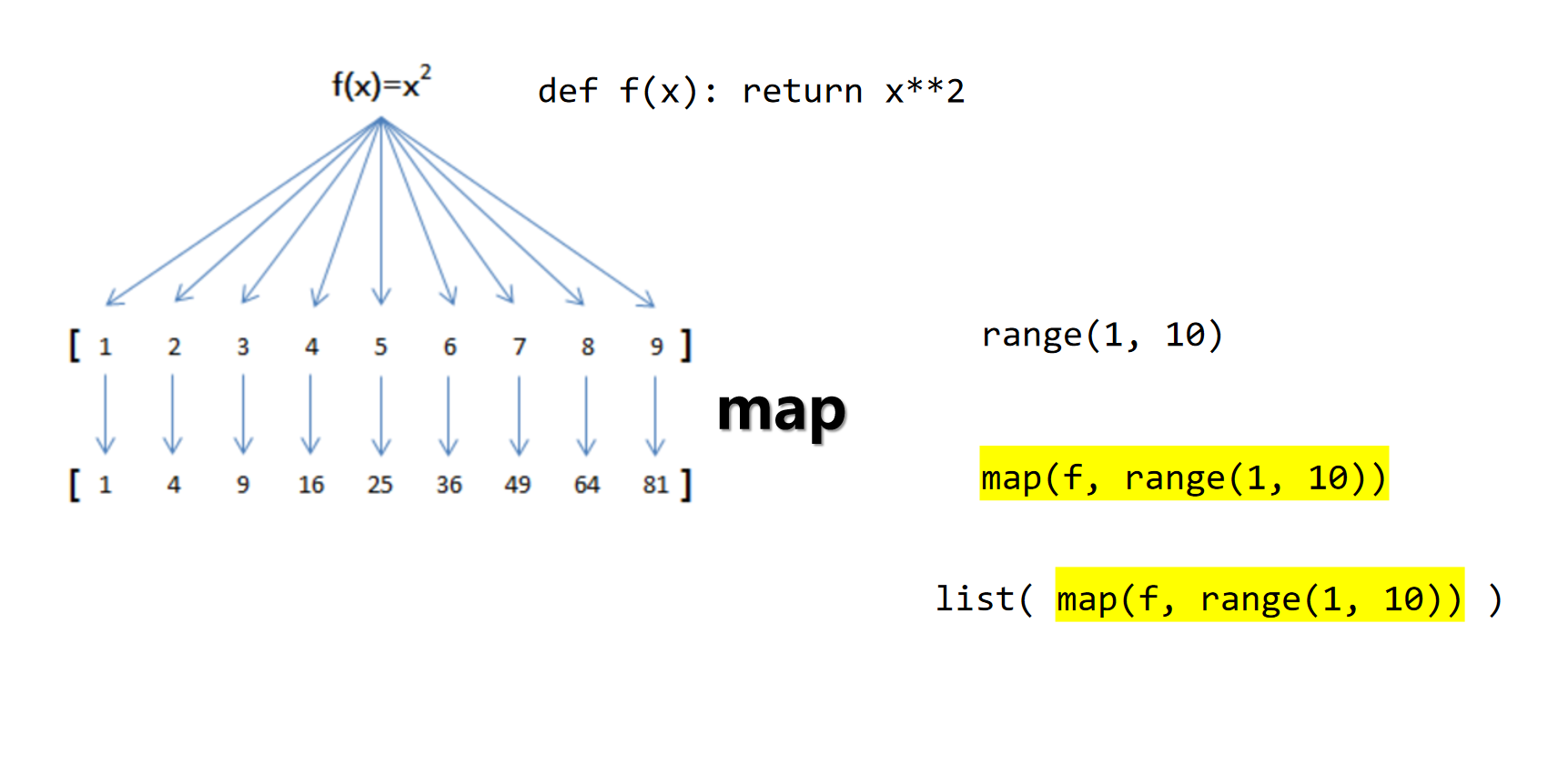
使用匿名函数


递归函数

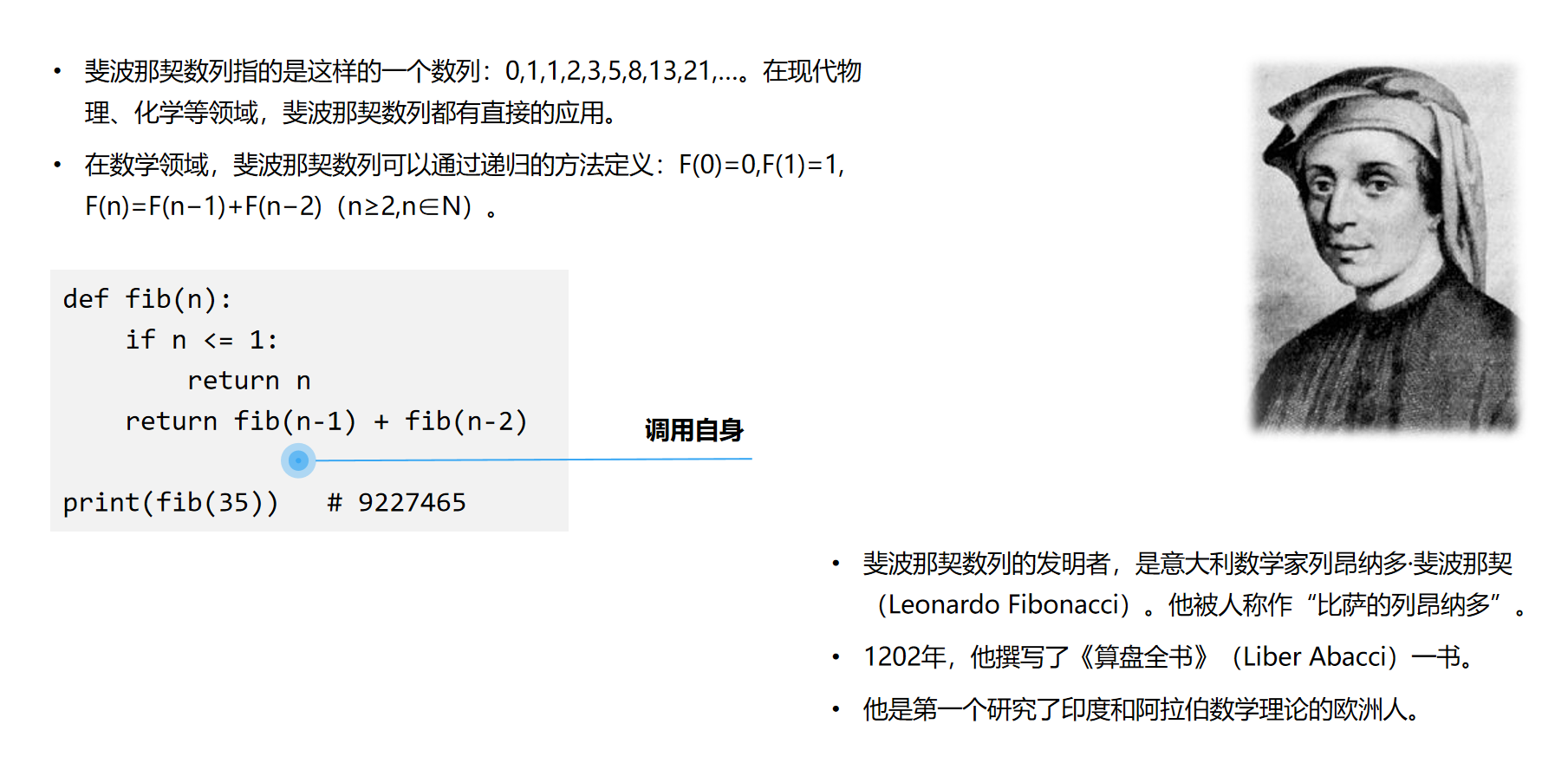
递归方法是指在程序中不断反复调用自身来求解问题的方法。这里强调的重点是调用自身,所以需要等待求解的问题能够分解为相同问题的一个子问题。这样通过多次递归调用,便可完成求解。 递归方法的具体实现过程一般通过函数(或子过程)来完成。在函数(或子过程)的内部,编代码直接或者间接地调用函数(或子过程)自身,即可完成递归操作。这种函数也称为“递归函数”。 在递归函数中,主调函数同时又是被调函数。执行递归函数将反复调用其自身,每调用一次就进入新的一层。



变量的作用域




生成器
生成器是由函数+yield关键字创造出来的写法,在特定情况下,用他可以帮助我们节省内存。
- 生成器函数,但函数中有yield存在时,这个函数就是生产生成器函数。
def func():
print(111)
yield 1
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
print(444)
- 生成器对象,执行生成器函数时,会返回一个生成器对象。
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
print(444)
data = func()
# 执行生成器函数func,返回的生成器对象。
# 注意:执行生成器函数时,函数内部代码不会执行。
def func():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
print(444)
data = func()
v1 = next(data)
print(v1)
v2 = next(data)
print(v2)
v3 = next(data)
print(v3)
v4 = next(data)
print(v4) # 结束或中途遇到return,程序爆:StopIteration 错误
data = func()
for item in data:
print(item)
生成器的特点是,记录在函数中的执行位置,下次执行next时,会从上一次的位置基础上再继续向下执行。
应用场景
-
假设要让你生成 300w个随机的4位数,并打印出来。
- 在内存中一次性创建300w个
- 动态创建,用一个创建一个。
import random
val = random.randint(1000, 9999)
print(val)
import random
data_list = []
for i in range(300000000):
val = random.randint(1000, 9999)
data_list.append(val)
# 再使用时,去 data_list 中获取即可。
# ...
import random
def gen_random_num(max_count):
counter = 0
while counter < max_count:
yield random.randint(1000, 9999)
counter += 1
data_list = gen_random_num(3000000)
# 再使用时,去 data_list 中获取即可。
高阶函数
-
一切皆为对象(地址、数据成员、类型)
-
First Class Object
- 函数在Python中是一等公民
- 函数也对象,可调用的对象
- 函数可以作为普通变量、参数、返回值等等
-
高阶函数
- 数学中概念y=g(f(x))
-
在数学和计算机科学中,高阶函数至少应该满足下面的一个条件的函数
- 接收一个或多个函数的引用作为参数的函数
- 返回值是一个函数引用的函数
-
函数的引用 :函数的名字
- 函数的执行结果:func() is return 的结果
-
计数器
def counter(base):
def inc(step=1):
base += step
return base
return inc
-
分析:
- 函数counter是不是一个高阶函数
- 上面的代码有没有什么问题,怎么改进
- 如何调用完成计数功能
- f1 = counter(5) 和 f2= counter(5) f1和f2相等吗?
自定义my_sort函数
- 排序问题
- 仿照内置函数sorted,自行设计一个my_sort函数(不适用内置函数)
- 思路
- 内建函数sorted函数返回一个新的列表,可以设置升序或降序,可以设置一个排序函数,自定义的my_sort函数也要拥有相同的功能。
- 新建一个列表,遍历原列表,和新列表的值一次比较决定如何插入到新列表中。
- 思考my_sort函数的实现原理,扩展到map\filter函数中。
- 实现简单排序
# 实现简单排序
lis = [1, 6, 2, 5, 4, 3, 7]
def my_sort(iterable):
ret = []
for x in iterable:
for i, y in enumerate(ret):
if x < y:
ret.insert(i, x)
break
else:
ret.append(x)
return ret
new_lis = my_sort(lis)
print(new_lis)
- 实现升序/降序
# 实现reverse功能
def my_sort(iterable, reverse=False):
ret = []
for x in iterable:
for i, y in enumerate(ret):
flag = x > y if reverse else x < y
if flag:
ret.insert(i, x)
break
else:
ret.append(x)
return ret
new_lis = my_sort(lis)
print(new_lis)
# 将比较函数单独定义
def comp(x, y, reverse):
return x > y if reverse else x < y
def my_sort(iterable, reverse=False):
ret = []
for x in iterable:
for i, y in enumerate(ret):
if comp(x, y, reverse):
ret.insert(i, x)
break
else:
ret.append(x)
return ret
# 使用高阶函数方法重新实现
def my_sort(iterable, reverse=False, key=lambda x, y: x > y):
ret = []
for x in iterable:
for i, y in enumerate(ret):
flag = key(x, y) if reverse else key(y, x)
if flag:
ret.insert(i, x)
break
else:
ret.append(x)
return ret
# 优化一下,让这个函数更接近sorted函数
def my_sort(iterable, reverse=False, key=lambda x: x):
ret = []
for x in iterable:
for i, y in enumerate(ret):
a, b = key(x), key(y)
flag = a > b if reverse else a < b
if flag:
ret.insert(i, x)
break
else:
ret.append(x)
return ret
- 函数是一步一步抽取功能实现的。
内建函数-高阶函数
sorted(iterable[,key][,reverse]) 排序
filter(func,iterable) --> filer objet
map(func,*iterables) --> map object 映射
sorted
功能: 返回一个新的列表,对一个可迭代对象的素有元素排序,排序规则是由key定义,revere表示是否翻转。
sorted(lis,key=str) # 返回新列表
list.sort(key=lambda x:len(str(x))) # 原地修改
filter
功能:过滤可迭代对象的元素,返回一个迭代器
funtion一个具有一个参数的函数返回bool(布尔)
例如:过滤出数字中所有的偶数
list(filter(lambda x:x%2 ==0,range(100)))
map
作用:对多个可迭代对象的元素按照指定的函数进行映射,返回一个迭代器。
list(map(lambda x:2*x+1,range(5)))
dict(map(lambda x: (str(x), x), range(500)))
reduce
# reduce函数 累计 函数必须能够接受两个参数,让序列中的值累计运算,前两个在函数中执行的执行结果在作为参数与下一个元素运算。
from functools import reduce
res2 = reduce(lambda x,y: x*y,[1,2,3,4,5])
print(res2)
柯里化Currying
-
柯里化
- 是指将原来接收多个参数的函数,变成新的接收一个参数的函数的过程。
- z = f(x,y) 转换成z=f(x)(y)的形式
- 通过嵌套函数可以普通函数改变为柯里化函数
-
举例
# 将加法柯里化
def add(x):
def _add(y):
return x + y
return _add
n = add(10)(3)
print(n)
装饰器
Python的装饰器(decorator)可以说是Python的一个神器,它可以在不改变一个函数代码和调用方式的情况下给函数添加新的功能。Python的装饰器同时也是Python学习从入门到精通过程中必需要熟练掌握的知识。
-
装饰器就是一个嵌套函数,要满足以下特点
- 外层函数要接受一个要包装的函数作为参数
- 内层函数可以执行被包装的函数
- 外层函数要返回内层函数的引用
-
需求增强add函数,让它具有输出功能,但不能改变它
def add(x,y):
return x + y
- 实现功能
def add(x, y):
return x + y
def logger(fn):
print("begin")
res = fn(3, 7)
print(res)
print("end")
logger(add)
# 优化一下
def logger(fn):
def _logger(*args, **kwargs):
print("begin")
res = fn(*args, **kwargs)
print(res)
print("end")
return _logger
# add = logger(add)
# add(3, 7)
logger(add)(4,6)
# 使用装饰器语法糖
@logger # 等价于 add = logger(add)
def add(x,y):
return x + y
add(2,8)
带参装饰器
- 三层嵌套的装饰器函数可以实现带参装饰器
- 案例:实现求其他函数n次执行的平均时间的装饰器函数
import time
# 最外层接收装饰器的参数
def timer(n=1):
# 中间层接收的是函数
def _timer(fn):
# 最内层接收函数的参数
def __timer(*args, **kwargs):
lis = []
print("begin")
start_time = time.time()
for i in range(n):
result = fn(*args, **kwargs)
lis.append(result)
print(f"执行{n}次后的平均运行时间是:{(time.time()-start_time)/n}")
return lis
# 最内层函数
return __timer
# 返回中间层
return _timer
@timer(10)
def func():
s = 0
for i in range(1000):
for j in range(10000):
s += i * j
print(s)
func()
- 带参数装饰器
- 它是一个函数
- 函数作为它的形参
- 返回值是一个不带参数的装饰器函数
- 使用@functionname(参数列表)方法调用
- 可以看做是在装饰器外层又加了一层函数
装饰器的应用
-
日志、监控、权限、设计、参数检查、路由处理。
-
这些功能与业务无关,很多业务都需要公共功能,所以适合独立出来,需要的时候对目标进行增强。
上面的装饰器已经非常完美了,但是有我们正常情况下查看函数信息的方法在此处都会失效:
def index():
'''这是一个主页信息'''
print('from index')
print(index.__doc__) #查看函数注释的方法
print(index.__name__) #查看函数名的方法
# 解决方法
from functools import wraps
def deco(func):
#加在最内层函数正上方,用func的属性替换掉wrapper原先的属性
@wraps(func)
def wrapper(*args,**kwargs):
return func(*args,**kwargs)
return wrapper
@deco
def index():
'''哈哈哈哈'''
print('from index')
print(index.__doc__)
print(index.__name__)
functools模块
from functools import update_wrapper
# 将被包装函数的所有特殊属性覆盖掉包装函数
update_wrapper(wrapper, # 包装函数
wrapped, # 被包装函数
assigned = WRAPPER_ASSIGNMENTS,
updated = WRAPPER_UPDATES)
# WRAPPER_ASSIGNMENTS元组 要被覆盖的属性
WRAPPER_ASSIGNMENTS = ('__module__', # 模块名
'__name__', # 函数名
'__qualname__', # 限定名
'__doc__', # 文档
'__annotations__' # 参数注解
)
# 更新包含函数的字典
WRAPPER_UPDATES = ('__dict__',)
# 解决方法
from functools import update_wrapper
def deco(func):
def wrapper(*args,**kwargs):
return func(*args,**kwargs)
update_wrapper(wrapper,func)
return wrapper
@deco
def index():
'''哈哈哈哈'''
print('from index')
print(index.__doc__)
print(index.__name__)
Python类型注解
python函数定义的弊端
-
Python是动态语言,变量随时可以被赋值,且赋值可以为不同的类型
-
Python不是静态编译语言,变量类型是机器运行决定的。
-
动态语言很灵活,但是这种特性也是弊端
def add(x,y):
return x+y
print(add(4,5))
print(add("hello","world"))
print(add(5,"abcd"))
-
错误难以发现,由于不做类型检查,直到运行期间才会显现问题
-
难使用:函数使用者看到函数时,并不知道你的函数设计,并不知道函数的类型。
解决弊端的方法
- 1.增加文档
def add(x,y):
"""
:param x:int
:param y:int
:return int
"""
return x + y
print(help(add))
* 这只是一个惯例,不是强制标准
* 函数更新了,文档未必更新
- 2.函数注解Function Annotations
def add(x:int,y:int)->int:
"""
:param x:int
:param y:int
:return int
"""
return x + y
print(help(add))
-
Python3.5引入
-
对函数的参数进行类型的注解
-
对函数的返回值进行类型的注解
-
对函数的参数做一个辅助的说明,并不对函数参数进行类型检查
-
提供第三方工具,做代码分析,发现隐藏bug
-
函数注解的信息,保存在
__annotations__中
print(add.__annotations__)
{'x': <class 'int'>, 'y': <class 'int'>, 'return': <class 'int'>}
-
变量注解
- Python3.6中引入
- i:int = 100
-
inspet模块提供了获取对象信息函数,可以检查函数、类的类型检查。
inspect模块中的signature(callable)函数
获取对象签名
import inspect
def add(x:int,y:int)->int:
"""
:param x:int
:param y:int
:return int
"""
return x + y
sig = inspect.signature(add)
print(sig)
print(sig.parameters)
print(sig.return_annotation)
inspect模块主要提供了四种用处:
"""
1.对是否是模块、框架、函数进行类型检查
2.获取源码
3.获取类或者函数的参数信息
4.解析堆栈
"""
inspect.ismodule(object): 是否为模块
inspect.isclass(object):是否为类
inspect.ismethod(object):是否为方法(bound method written in python)
inspect.isfunction(object):是否为函数(python function, including lambda expression)
inspect.isgeneratorfunction(object):是否为python生成器函数
inspect.isgenerator(object):是否为生成器