Pod探针是K8s保障容器运行稳定性的核心机制,直接决定了故障容器能否被自动修复、服务流量能否精准路由。
K8s通过三类探针监控Pod状态,分别对应“容器是否存活”“是否可用”“是否启动完成”三个核心场景,实现故障自动干预。
一、核心探针类型:三类探针的核心区别
三类探针的核心差异在于监控目标和失败后的处理逻辑,具体如下表所示:
| 探针类型 | 核心作用 | 失败后果 | 典型使用场景 |
|---|---|---|---|
| 存活探针(livenessProbe) | 判断容器是否“存活”(如进程是否卡死) | 触发容器重启(符合重启策略时) | 应用死锁、进程无响应 |
| 就绪探针(readinessProbe) | 判断容器是否“可用”(如服务是否启动完成、能处理请求) | 容器从Service endpoints中移除,流量不转发 | 应用启动慢(如加载配置/数据)、依赖服务未就绪(如连不上数据库) |
| 启动探针(startupProbe) | 给慢启动容器“兜底”,判断是否“启动完成” | 同存活探针,触发容器重启 | 超大应用启动(如大数据组件、重型服务),避免存活探针误判重启 |
二、探针的实现方式:3种常用检测手段
配置探针时,需指定具体的检测方法,K8s支持以下3种主流方式:
1.exec命令:在容器内执行命令,通过命令退出码判断状态(0=成功,非0=失败)。
- 示例:执行
cat /tmp/healthy,若文件存在则探针成功。
2.httpGet请求:向容器内的指定IP、端口、路径发送HTTP GET请求,通过响应码判断(2xx/3xx=成功,其他=失败)。
- 示例:访问
http://localhost:8080/actuator/health(Spring Boot健康检查接口)。
3.tcpSocket检查:尝试与容器内的指定IP、端口建立TCP连接,连接成功=探针成功。
- 示例:检查容器的80端口是否能正常建立连接(适用于非HTTP服务,如MySQL、Redis)。
三、关键配置参数:避免探针误判的核心
配置探针时,需合理设置以下参数,防止因“检测时机不当”导致误判:
- initialDelaySeconds:容器启动后,延迟多久开始第一次探针检查(单位:秒)。
- 示例:启动慢的应用设为30秒,避免启动中被误判为失败。
- periodSeconds:探针检查的周期(单位:秒),默认10秒。
- failureThreshold:连续失败多少次后,判定为探针失败(默认3次)。
- successThreshold:探针失败后,连续成功多少次后,恢复为成功状态(默认1次)。
四、配置示例:yaml中如何写探针
以“Spring Boot应用”为例,同时配置存活探针和就绪探针的yaml片段如下:
spec:
containers:
- name: spring-boot-app
image: my-spring-app:v1
ports:
- containerPort: 8080
# 存活探针:检查服务是否存活,失败重启
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 30 # 启动30秒后开始检查
periodSeconds: 10 # 每10秒检查一次
failureThreshold: 3 # 连续3次失败则重启
# 就绪探针:检查服务是否可用,失败移除流量
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 20
periodSeconds: 5
YMAL详解
apiVersion: v1 # Kubernetes API 版本
kind: Pod # 资源类型为 Pod
metadata:
name: probe-pod # Pod 的名称
labels: # Pod 的标签
app: example # 标签值为 example
spec:
containers: # 定义容器列表
- name: app-container # 容器的名称
image: nginx:1.19 # 使用的镜像为 nginx 1.19 版本
livenessProbe: # 存活探针配置
httpGet: # 使用 HTTP GET 请求进行探针检测
path: /healthz # 请求的路径
port: 80 # 请求的端口
initialDelaySeconds: 30 # 容器启动后延迟30秒开始探针检测
periodSeconds: 10 # 探针检测的时间间隔为10秒
timeoutSeconds: 5 # 探针检测的超时时间为5秒
successThreshold: 1 # 探针检测成功所需的最小连续成功次数
failureThreshold: 3 # 探针检测失败所需的最小连续失败次数
readinessProbe: # 就绪探针配置
httpGet: # 使用 HTTP GET 请求进行探针检测
path: /ready # 请求的路径
port: 80 # 请求的端口
initialDelaySeconds: 5 # 容器启动后延迟5秒开始探针检测
periodSeconds: 10 # 探针检测的时间间隔为10秒
timeoutSeconds: 1 # 探针检测的超时时间为1秒
successThreshold: 1 # 探针检测成功所需的最小连续成功次数
failureThreshold: 3 # 探针检测失败所需的最小连续失败次数
startupProbe: # 启动探针配置
httpGet: # 使用 HTTP GET 请求进行探针检测
path: /start # 请求的路径
port: 80 # 请求的端口
initialDelaySeconds: 10 # 容器启动后延迟10秒开始探针检测
periodSeconds: 10 # 探针检测的时间间隔为10秒
timeoutSeconds: 5 # 探针检测的超时时间为5秒
successThreshold: 1 # 探针检测成功所需的最小连续成功次数
failureThreshold: 30 # 探针检测失败所需的最小连续失败次数
部署 Pod
1.将上述 YAML 文件保存为 probe-pod.yaml。
2.使用 kubectl 命令创建 Pod:
kubectl apply -f probe-pod.yaml
3.检查 Pod 的状态:
kubectl get pod probe-pod
4.查看 Pod 的事件和日志,以了解探针的检查结果:
kubectl describe pod probe-pod
kubectl logs probe-pod
就绪检测:
# vim readinessProbe-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
spec:
containers:
- name: readiness-httpget-container
image: docker.io/nginx
imagePullPolicy: IfNotPresent # 表示只有当镜像在本地不存在时,才会从镜像仓库中拉取。
readinessProbe: # 就绪探针,如果失败,K8S 不会将流量路由到该 Pod,直到探测成功。
httpGet:
port: 80
path: /index.html
initialDelaySeconds: 1 # 表示容器启动后等待 1 秒再进行第一次健康检查。
periodSeconds: 3 # 表示每隔 3 秒进行一次健康检查。
我们先运行该 Pod 然后查看其状态:
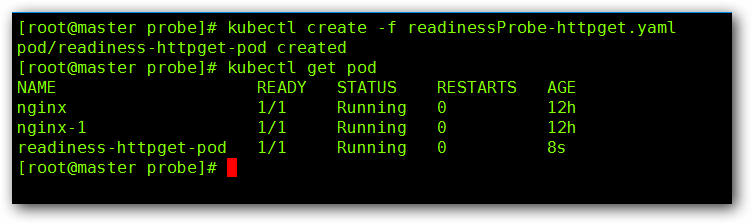
已经成功开始运行,这个时候我们进入到该 Pod 然后将其 index.html 文件删除后,在看其状态:
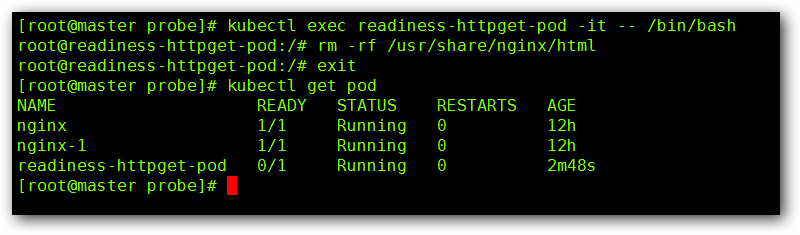
这个时候我们可以看到,虽然容器处于 Running 状态,但是却处于 No Ready 的状态,这个时候我们通过kubectl describe pod readiness-httpget-pod 命令,查看一下具体的信息:

我们看到,显示 “Readiness probe failed: HTTP probe failed with statuscode: 404” 就绪探测失败,错误代码 404 表明页面不存在。
存活检测
- EXEC
# vim livenessProbe-exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
spec:
containers:
- name: liveness-exec-container
image: docker.io/busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/live ; sleep 60; rm -rf /tmp/live; sleep 3600"]
livenessProbe:
exec:
command: ["test","-e","/tmp/live"]
initialDelaySeconds: 1
periodSeconds: 3
然后查看下我们 Pod 的实时状态:
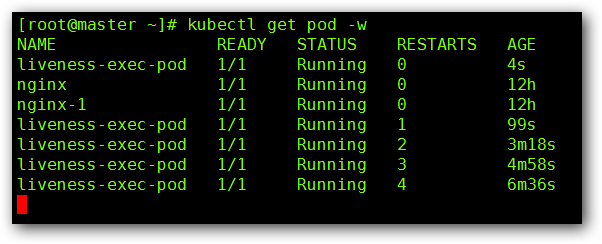
经过一段时间等待,我们发现 liveness-exec-pod 出现了重启的现象,这是因为,在我们创建这个 Pod 的时候,我们会在 /tmp 下创建一个 live 的文件,60 秒以后会将其删除,当进行存活检测的时候发现该文件没有了,那么 Pod 认为里面的容器死亡了,就会重启,那么就会重新执行一遍 yaml 文件内的配置,这个时候 live 文件又存在了,但是 60 秒以后,又会被删除,就会在重启一遍,以此类推。
- HTTPGET
# vim livenessProbe-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
spec:
containers:
- name: liveness-httpget-container
image: docker.io/nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
然后我们查看一下 Pod 的状态:
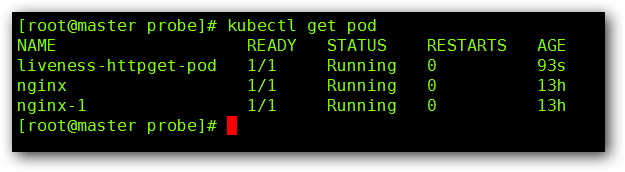
这个时候我们通过 “kubectl exec liveness-httpget-pod -it – rm -rf /usr/share/nginx/html/index.html” 命令将 index.html 文件删除掉,我们在进行查看 Pod 的状态:
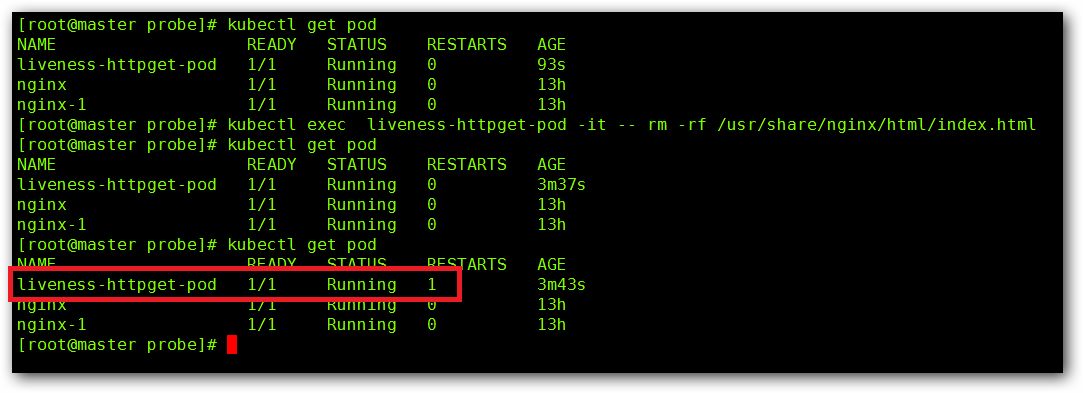
经过一段时间等待,我们发现 liveness-httpget-pod 出现了重启的现象,这是因为,当我们手动删除了 index.html 文件后,当进行存活检测的时候发现该文件没有了,那么 Pod 认为里面的容器死亡了,就会重启,那么就会重新执行一遍 yaml 文件内的配置,这个时候 index.html 文件又存在了,如果我们再次删除该文件,就会在重启一遍,以此类推。
- TCPSocket
# vim livenessProbe-tcp.yaml
apiVersion: v1
kind: Pod
metadata:
name: probe-tcp
spec:
containers:
- name: nginx
image: docker.io/nginx
livenessProbe:
initialDelaySeconds: 5
timeoutSeconds: 1
tcpSocket:
port: 808 # 故意检测错误的端口号
然后我们查看一下 Pod 的状态:
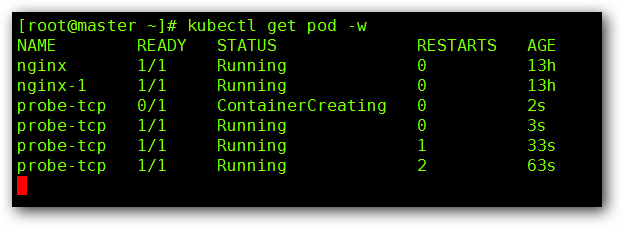
我们可以看到,开始的时候,Pod 创建成功,但是 30 秒以后,重启了第一次,在经过 30 秒以后,又重启了一次,这是因为, nginx 默认开启的端口为 80 ,而当我们开始存活检测的时候,端口为 808 ,因为没有这个端口,所以认定 Pod 死亡,所以重启,当又开始存活检测的时候,依然没有端口,所以继续重启,以此类推。
二、实战
模拟一个容器发生故障时的场景 :
# 先来生成一个pod的yaml配置文件,并对其进行相应修改
kubectl run busybox --image=busybox --dry-run=client -o yaml > testHealthz.yaml
vim testHealthz.yaml
#----------------以下为文件内容--------------------
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: busybox
name: busybox
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
name: busybox
resources: {}
args:
- /bin/sh
- -c
- sleep 10; exit 1 # 并添加pod运行指定脚本命令,模拟容器启动10秒后发生故障,退出状态码为1
dnsPolicy: ClusterFirst # Pod 的 DNS 请求将优先指向 Kubernetes 集群内部的 DNS 服务(通常是 CoreDNS)。
restartPolicy: OnFailure # 将默认的Always修改为OnFailure。
status: {}
重启策略说明
- Always:当容器失效时,由kubelet自动重启该容器
- OnFailure:表示只有当容器以非零状态码(即失败状态)退出时,Kubernetes 才会重新启动该容器。
- Never:不论容器运行状态如何,kubelet都不会重启该容器
执行配置创建pod
# kubectl apply -f testHealthz.yaml
pod/busybox created
# 观察几分钟,利用-w 参数来持续监听pod的状态变化
# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
busybox 0/1 ContainerCreating 0 4s
busybox 1/1 Running 0 6s
busybox 0/1 Error 0 16s
busybox 1/1 Running 1 22s
busybox 0/1 Error 1 34s
busybox 0/1 CrashLoopBackOff 1 47s
busybox 1/1 Running 2 63s
busybox 0/1 Error 2 73s
busybox 0/1 CrashLoopBackOff 2 86s
busybox 1/1 Running 3 109s
busybox 0/1 Error 3 2m
busybox 0/1 CrashLoopBackOff 3 2m15s
busybox 1/1 Running 4 3m2s
busybox 0/1 Error 4 3m12s
busybox 0/1 CrashLoopBackOff 4 3m23s
busybox 1/1 Running 5 4m52s
busybox 0/1 Error 5 5m2s
busybox 0/1 CrashLoopBackOff 5 5m14s
上面可以看到这个测试pod被重启了5次,然而服务始终正常不了,就会保持在CrashLoopBackOff了,等待运维人员来进行下一步错误排查
注:kubelet会以指数级的退避延迟(10s,20s,40s等)重新启动它们,上限为5分钟
这里我们是人为模拟服务故障来进行的测试,在实际生产工作中,对于业务服务,我们如何利用这种重启容器来恢复的机制来配置业务服务呢,答案是`liveness`检测
Liveness
Liveness检测让我们可以自定义条件来判断容器是否健康,如果检测失败,则K8s会重启容器,我们来个例子实践下,准备如下yaml配置并保存为liveness.yaml:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness
spec:
restartPolicy: OnFailure
containers:
- name: liveness
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测
periodSeconds: 5 # 每隔 5 秒再检测一次
启动进程首先创建文件 /tmp/healthy,30 秒后删除,在我们的设定中,如果 /tmp/healthy 文件存在,则认为容器处于正常状态,反正则发生故障。
livenessProbe 部分定义如何执行 Liveness 检测:
检测的方法是:通过 cat 命令检查 /tmp/healthy 文件是否存在。如果命令执行成功,返回值为零,K8s 则认为本次 Liveness 检测成功;如果命令返回值非零,本次 Liveness 检测失败。
initialDelaySeconds: 10 指定容器启动 10 之后开始执行 Liveness 检测,我们一般会根据应用启动的准备时间来设置。比如某个应用正常启动要花 30 秒,那么 initialDelaySeconds 的值就应该大于 30。
periodSeconds: 5 指定每 5 秒执行一次 Liveness 检测。K8s 如果连续执行 3 次 Liveness 检测均失败,则会杀掉并重启容器。
接着来创建这个Pod:
# kubectl apply -f liveness.yaml
pod/liveness created
从配置文件可知,最开始的 30 秒,/tmp/healthy 存在,cat 命令返回 0,Liveness 检测成功,这段时间 kubectl describe pod liveness 的 Events部分会显示正常的日志
# kubectl describe pod liveness
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 53s default-scheduler Successfully assigned default/liveness to 10.0.1.203
Normal Pulling 52s kubelet Pulling image "busybox"
Normal Pulled 43s kubelet Successfully pulled image "busybox"
Normal Created 43s kubelet Created container liveness
Normal Started 42s kubelet Started container liveness
35 秒之后,日志会显示 /tmp/healthy 已经不存在,Liveness 检测失败。再过几十秒,几次检测都失败后,容器会被重启。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3m53s default-scheduler Successfully assigned default/liveness to 10.0.1.203
Normal Pulling 73s (x3 over 3m52s) kubelet Pulling image "busybox"
Normal Pulled 62s (x3 over 3m43s) kubelet Successfully pulled image "busybox"
Normal Created 62s (x3 over 3m43s) kubelet Created container liveness
Normal Started 62s (x3 over 3m42s) kubelet Started container liveness
Warning Unhealthy 18s (x9 over 3m8s) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 18s (x3 over 2m58s) kubelet Container liveness failed liveness probe, will be restarted
除了 Liveness 检测,Kubernetes Health Check 机制还包括 Readiness 检测。
Readiness
我们可以通过Readiness检测来告诉K8s什么时候可以将pod加入到服务Service的负载均衡池中,对外提供服务,这个在生产场景服务发布新版本时非常重要,当我们上线的新版本发生程序错误时,Readiness会通过检测发布,从而不导入流量到pod内,将服务的故障控制在内部,在生产场景中,建议这个是必加的,Liveness不加都可以,因为有时候我们需要保留服务出错的现场来查询日志,定位问题,告之开发来修复程序。
Readiness 检测的配置语法与 Liveness 检测完全一样,下面是个例子:
apiVersion: v1
kind: Pod
metadata:
labels:
test: readiness
name: readiness
spec:
restartPolicy: OnFailure
containers:
- name: readiness
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
readinessProbe: # 这里将livenessProbe换成readinessProbe即可,其它配置都一样
exec:
command:
- cat
- /tmp/healthy
#initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测
periodSeconds: 5 # 每隔 5 秒再检测一次
startupProbe: # 启动探针,更灵活,完美代替initialDelaySeconds强制等待时间配置,启动时每3秒检测一次,一共检测100次
exec:
command:
- cat
- /tmp/healthy
failureThreshold: 100
periodSeconds: 3
timeoutSeconds: 1
保存上面这个配置为readiness.yaml,并执行它生成pod:
# kubectl apply -f readiness.yaml
pod/liveness created
# 观察,在刚开始创建时,文件并没有被删除,所以检测一切正常
# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness 1/1 Running 0 50s
# 然后35秒后,文件被删除,这个时候READY状态就会发生变化,K8s会断开Service到pod的流量
# kubectl describe pod liveness
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 56s default-scheduler Successfully assigned default/liveness to 10.0.1.203
Normal Pulling 56s kubelet Pulling image "busybox"
Normal Pulled 40s kubelet Successfully pulled image "busybox"
Normal Created 40s kubelet Created container liveness
Normal Started 40s kubelet Started container liveness
Warning Unhealthy 5s (x2 over 10s) kubelet Readiness probe failed: cat: can't open '/tmp/healthy': No such file or directory
# 可以看到pod的流量被断开,这时候即使服务出错,对外界来说也是感知不到的,这时候我们运维人员就可以进行故障排查了
# kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness 0/1 Running 0 61s
下面对 Liveness 检测和 Readiness 检测做个比较: Liveness 检测和 Readiness 检测是两种 Health Check 机制,如果不特意配置,Kubernetes 将对两种检测采取相同的默认行为,即通过判断容器启动进程的返回值是否为零来判断检测是否成功。
两种检测的配置方法完全一样,支持的配置参数也一样。不同之处在于检测失败后的行为:Liveness 检测是重启容器;Readiness 检测则是将容器设置为不可用,不接收 Service 转发的请求。
Liveness 检测和 Readiness 检测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用。用 Liveness 检测判断容器是否需要重启以实现自愈;用 Readiness 检测判断容器是否已经准备好对外提供服务。
Liveness 和 Readiness 的三种使用方式
readinessProbe: # 定义只有http检测容器6222端口请求返回是 200-400,则接收下面的Service web-svc 的请求
httpGet:
scheme: HTTP
path: /check
port: 6222
initialDelaySeconds: 10 # 容器启动 10 秒之后开始探测,注意观察下g1的启动成功时间
periodSeconds: 5 # 每隔 5 秒再探测一次
timeoutSeconds: 5 # http检测请求的超时时间
successThreshold: 1 # 检测到有1次成功则认为服务是`就绪`
failureThreshold: 3 # 检测到有3次失败则认为服务是`未就绪`
livenessProbe: # 定义只有http检测容器6222端口请求返回是 200-400,否则就重启pod
httpGet:
scheme: HTTP
path: /check
port: 6222
initialDelaySeconds: 10
periodSeconds: 5
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
#-----------------------------------------
readinessProbe:
exec:
command:
- sh
- -c
- "redis-cli ping"
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
livenessProbe:
exec:
command:
- sh
- -c
- "redis-cli ping"
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
#-----------------------------------------
readinessProbe:
tcpSocket:
port: 9092
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 9092
initialDelaySeconds: 15
periodSeconds: 10
Health Check 在 业务生产中滚动更新(rolling update)的应用场景 对于运维人员来说,将服务的新项目代码更新上线,确保其稳定运行是一项很关键,且重复性很高的任务,在传统模式下,我们一般是用saltsatck或者ansible等批量管理工具来推送代码到各台服务器上进行更新,那么在K8s上,这个更新流程就被简化了,在后面高阶章节我会讲到CI/CD自动化流程,大致就是开发人员开发好代码上传代码仓库即会触发CI/CD流程,这之间基本无需运维人员的参与。那么在这么高度自动化的流程中,我们运维人员怎么确保服务能稳定上线呢?Health Check里面的Readiness 能发挥很关键的作用,这个其实在上面也有讲过,这里我们再以实例来说一遍,加深印象:
我们准备一个deployment资源的yaml文件
# cat myapp-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytest
spec:
replicas: 10 # 这里准备10个数量的pod
selector:
matchLabels:
app: mytest
template:
metadata:
labels:
app: mytest
spec:
containers:
- name: mytest
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- sleep 10; touch /tmp/healthy; sleep 30000
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5
运行这个配置
# kubectl apply -f myapp-v1.yaml --record
deployment.apps/mytest created
# 等待一会,可以看到所有pod已正常运行
# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytest-d9f48585b-2lmh2 1/1 Running 0 3m22s
mytest-d9f48585b-5lh9l 1/1 Running 0 3m22s
mytest-d9f48585b-cwb8l 1/1 Running 0 3m22s
mytest-d9f48585b-f6tzc 1/1 Running 0 3m22s
mytest-d9f48585b-hb665 1/1 Running 0 3m22s
mytest-d9f48585b-hmqrw 1/1 Running 0 3m22s
mytest-d9f48585b-jm8bm 1/1 Running 0 3m22s
mytest-d9f48585b-kxm2m 1/1 Running 0 3m22s
mytest-d9f48585b-lqpr9 1/1 Running 0 3m22s
mytest-d9f48585b-pk75z 1/1 Running 0 3m22s
接着我们来准备更新这个服务,并且人为模拟版本故障来进行观察,新准备一个配置myapp-v2.yaml
# cat myapp-v2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytest
spec:
strategy:
rollingUpdate:
maxSurge: 35% # 滚动更新的副本总数最大值(以10的基数为例):10 + 10 * 35% = 13.5 --> 14
maxUnavailable: 35% # 可用副本数最大值(默认值两个都是25%): 10 - 10 * 35% = 6.5 --> 7
replicas: 10
selector:
matchLabels:
app: mytest
template:
metadata:
labels:
app: mytest
spec:
containers:
- name: mytest
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- sleep 30000 # 可见这里并没有生成/tmp/healthy这个文件,所以下面的检测必然失败
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5
很明显这里因为我们更新的这个v2版本里面不会生成/tmp/healthy文件,那么自动是无法通过Readiness 检测的,详情如下:
# kubectl apply -f myapp-v2.yaml --record
deployment.apps/mytest configured
# kubectl get deployment mytest
NAME READY UP-TO-DATE AVAILABLE AGE
mytest 7/10 7 7 4m58s
# READY 现在正在运行的只有7个pod
# UP-TO-DATE 表示当前已经完成更新的副本数:即 7 个新副本
# AVAILABLE 表示当前处于 READY 状态的副本数
# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytest-7657789bc7-5hfkc 0/1 Running 0 3m2s
mytest-7657789bc7-6c5lg 0/1 Running 0 3m2s
mytest-7657789bc7-c96t6 0/1 Running 0 3m2s
mytest-7657789bc7-nbz2q 0/1 Running 0 3m2s
mytest-7657789bc7-pt86c 0/1 Running 0 3m2s
mytest-7657789bc7-q57gb 0/1 Running 0 3m2s
mytest-7657789bc7-x77cg 0/1 Running 0 3m2s
mytest-d9f48585b-2bnph 1/1 Running 0 5m4s
mytest-d9f48585b-965t4 1/1 Running 0 5m4s
mytest-d9f48585b-cvq7l 1/1 Running 0 5m4s
mytest-d9f48585b-hvpnq 1/1 Running 0 5m4s
mytest-d9f48585b-k89zs 1/1 Running 0 5m4s
mytest-d9f48585b-wkb4b 1/1 Running 0 5m4s
mytest-d9f48585b-wrkzf 1/1 Running 0 5m4s
# 上面可以看到,由于 Readiness 检测一直没通过,所以新版本的pod都是Not ready状态的,这样就保证了错误的业务代码不会被外界请求到
# kubectl describe deployment mytest
# 下面截取一些这里需要的关键信息
......
Replicas: 10 desired | 7 updated | 14 total | 7 available | 7 unavailable
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m55s deployment-controller Scaled up replica set mytest-d9f48585b to 10
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 4 # 启动4个新版本的pod
Normal ScalingReplicaSet 3m53s deployment-controller Scaled down replica set mytest-d9f48585b to 7 # 将旧版本pod数量降至7
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 7 # 新增3个启动至7个新版本
综合上面的分析,我们很真实的模拟一次K8s上次错误的代码上线流程,所幸的是这里有Health Check的Readiness检测帮我们屏蔽了有错误的副本,不至于被外面的流量请求到,同时保留了大部分旧版本的pod,因此整个服务的业务并没有因这此更新失败而受到影响。
接下来我们详细分析下滚动更新的原理,为什么上面服务新版本创建的pod数量是7个,同时只销毁了3个旧版本的pod呢?
原因就在于这段配置:
我们不显式配置这段的话,默认值均是25
strategy:
rollingUpdate:
maxSurge: 35%
maxUnavailable: 35%
滚动更新通过参数maxSurge和maxUnavailable来控制pod副本数量的更新替换。
maxSurge 这个参数控制滚动更新过程中pod副本总数超过设定总副本数量的上限。maxSurge 可以是具体的整数(比如 3),也可以是百分比,向上取整。maxSurge 默认值为 25%
在上面测试的例子里面,pod的总副本数量是10,那么在更新过程中,总副本数量的上限大最值计划公式为:
10 + 10 * 35% = 13.5 --> 14
我们查看下更新deployment的描述信息:
Replicas: 10 desired | 7 updated | 14 total | 7 available | 7 unavailable
旧版本available 的数量7个 + 新版本unavailable`的数量7个 = 总数量 14 total
maxUnavailable-00:38:51 这个参数控制滚动更新过程中不可用的pod副本总数量的值,同样,maxUnavailable 可以是具体的整数(比如 3),也可以是百分百,向下取整。maxUnavailable 默认值为 25%。
在上面测试的例子里面,pod的总副本数量是10,那么要保证正常可用的pod副本数量为:
10 - 10 * 35% = 6.5 --> 7
所以我们在上面查看的描述信息里,7 available 正常可用的pod数量值就为7
maxSurge 值越大,初始创建的新副本数量就越多;maxUnavailable 值越大,初始销毁的旧副本数量就越多。
正常更新理想情况下,我们这次版本发布案例滚动更新的过程是:
首先创建4个新版本的pod,使副本总数量达到14个 然后再销毁3个旧版本的pod,使可用的副本数量降为7个 当这3个旧版本的pod被 成功销毁后,可再创建3个新版本的pod,使总的副本数量保持为14个 当新版本的pod通过Readiness 检测后,会使可用的pod副本数量增加超过7个 然后可以继续销毁更多的旧版本的pod,使整体可用的pod数量回到7个 随着旧版本的pod销毁,使pod副本总数量低于14个,这样就可以继续创建更多的新版本的pod 这个新增销毁流程会持续地进行,最终所有旧版本的pod会被新版本的pod逐渐替换,整个滚动更新完成 而我们这里的实际情况是在第4步就卡住了,新版本的pod数量无法能过Readiness 检测。上面的描述信息最后面的事件部分的日志也详细说明了这一切:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m55s deployment-controller Scaled up replica set mytest-d9f48585b to 10
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 4 # 启动4个新版本的pod
Normal ScalingReplicaSet 3m53s deployment-controller Scaled down replica set mytest-d9f48585b to 7 # 将旧版本pod数量降至7
Normal ScalingReplicaSet 3m53s deployment-controller Scaled up replica set mytest-7657789bc7 to 7 # 新增3个启动至7个新版本
这里按正常的生产处理流程,在获取足够的新版本错误信息提交给开发分析后,我们可以通过kubectl rollout undo 来回滚到上一个正常的服务版本:
# 先查看下要回滚版本号前面的数字,这里为1
# kubectl rollout history deployment mytest
deployment.apps/mytest
REVISION CHANGE-CAUSE
1 kubectl apply --filename=myapp-v1.yaml --record=true
2 kubectl apply --filename=myapp-v2.yaml --record=true
# kubectl rollout undo deployment mytest --to-revision=1
deployment.apps/mytest rolled back
# kubectl get deployment mytest
NAME READY UP-TO-DATE AVAILABLE AGE
mytest 10/10 10 10 96m
# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytest-d9f48585b-2bnph 1/1 Running 0 96m
mytest-d9f48585b-8nvhd 1/1 Running 0 2m13s
mytest-d9f48585b-965t4 1/1 Running 0 96m
mytest-d9f48585b-cvq7l 1/1 Running 0 96m
mytest-d9f48585b-hvpnq 1/1 Running 0 96m
mytest-d9f48585b-k89zs 1/1 Running 0 96m
mytest-d9f48585b-qs5c6 1/1 Running 0 2m13s
mytest-d9f48585b-wkb4b 1/1 Running 0 96m
mytest-d9f48585b-wprlz 1/1 Running 0 2m13s
mytest-d9f48585b-wrkzf 1/1 Running 0 96m
OK,到这里为止,我们真实的模拟了一次有问题的版本发布及回滚,并且可以看到,在这整个过程中,虽然出现了问题,但我们的业务依然是没有受到任何影响的,这就是K8s的魅力所在。
pod小怪战斗(作业)
# 把上面整个更新及回滚的案例,自己再测试一遍,注意观察其中的pod变化,加深理解