一、什么是高可用
通过前面课程的学习,我们知道LVS、Nginx、HaProxy可以实现很多种不同类型的分发,我们还知道,集群系统存在的作用就是为了解决单点故障的问题。
LVS、Nginx集群的单点故障问题
这个单点故障主要体现在两个方面
- 分发器宕机怎么处理?
- 假如负载均衡服务器挂掉了,那么所有的服务也会跟着瘫痪。
- 一种方法是人为监控,发现主分发器宕机后,立马登录备分发器,并给它分配虚ip。
-
另一种办法是用软件来替代人来监控,自动登录备分发器,分配虚ip。
-
数据服务器宕机怎么处理? 分发器可以自动判断数据服务器的存活状态,不对宕机服务器要数据。
二、Keepalived介绍
Keepalived软件起初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后来又加入了可以实现高可用的VRRP功能。因此,Keepalived除了能够管理LVS软件外,还可以作为其他服务(例如:Nginx、Haproxy、MySQL等)的高可用解决方案软件。
原理
keepalived一般是2个节点运行keepalived,一台是主节点(MASTE),一台是备节点(BACKUP),对外表现都是一个虚拟IP。
主节点会发送特定的消息给备节点,如果备节点收不到这个特定消息时,说明主节点就宕机了,此时备节点就会接管虚拟IP进行服务提供,这就实现了高可用。
Keepalived高可用服务对之间的故障切换转移,是通过VRRP协议(Virtual Router Redundancy Protocol 中文虚拟路由器冗余协议)来实现的。
在Keepalived服务正常工作时,主Master节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备Backup节点自己还活着,当主Master节点发生故障时,就无法发送心跳消息了,备节点也就因此无法继续检测到来自主Master节点的心跳了,进而调用自身的接管程序,接管主Master节点的IP资源及服务。而当主Master节点恢复时,备Backup节点又会释放主节点故障时自身接管的IP资源及服务,恢复到原来的备用角色。
Keepalived核心功能
1.管理LVS
2.对LVS节点做健康检查(基于端口和URL)
3.实现VRRP高可用功能
keepalived使用架构图
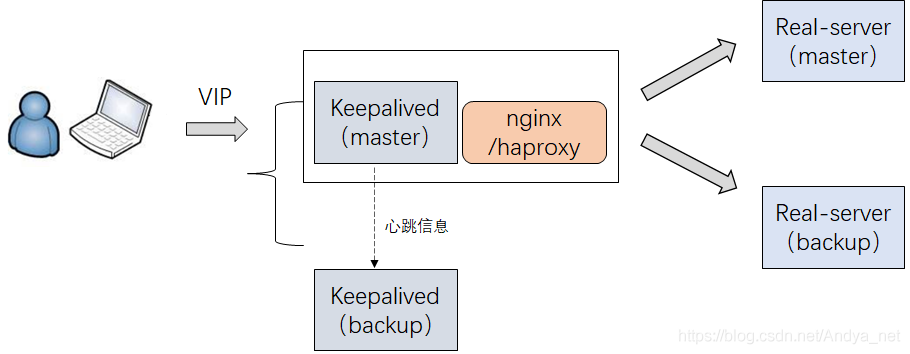 将keepalived和nginx部署在一台服务器。
将keepalived和nginx部署在一台服务器。
keepalived高可用故障切换转移
keepalived是基于VRRP协议来实现高可用的,有两种模式,一种是抢占模式(默认使用),另一种是非抢占模。
当使用抢占模式的时候,这是一种竞选机制进行通信,主节点优先级大于备节点优先级。当主节点宕机的时候,可以切到备节点进行提供服务,主节点恢复还会切换回主节点。
使用非抢占模时,当主节点宕机的时候,可以切到备节点进行提供服务。是当主节点恢复时,vip不会漂移回主节点上,只有当备节点发生故障时,vip才会飘移回主节点。
keepalived默认是抢占模式,需要加上nopreempt参数才能开启非抢占模式,非抢占模式需要所有节点都是backup状态,但是优先级还是有区分,而且优先级高的节点才需要配置非抢占模式,优先级低的不需要配置非抢占模式。
抢占模式原理如下:
-
keepalived正常工作的时候,MASTER主节点会向BACKUP备节点不断的发送特定消息(多播心跳消息),就是一种健康检查机制,告诉备节点“我还活着,虚拟IP我来管就行了!”。
-
当主节点发生故障出现宕机情况的时候,无法向备节点发送心跳信息,备节点无法收到主节点的健康检查心跳信息,这个时候,备节点终于转正了,机会来了,就接管虚拟IP进行服务提供。
-
当主节点故障恢复后,又不断的发送心跳给备节点,告知“我现在活着呢,我来管虚拟IP”,备节点就会释放主节点宕机时所接管的IP资源以及服务,默默的做回一个备胎。
keepalived是使用C语言编写的路由热备软件,该项目主要目标是为linux系统提供简单高效的负载均衡及高可用解决方案。keepalived由一组检查器,根据服务器的健康状况动态的维护和管理服务器池,另外keepalived通过vrrp协议实现高可用架构,vrrp是路由灾备的实现基础。通过前面的课程我们知道,在lvs中只解决了真实服务器的单点故障,但是如果分发器也就是lvs主机发生故障的话,整个集群系统都会崩溃,所以我们需要keepalived来实现集群系统的高可用。我们可以部署两台或更多的分发器,仅有一台调度器做为主服务器,其它的做为备用,当主调度器发生故障时,keepalived可以自动将备用调度器升级为主调度器,从而实现整个集群系统的高负载,高可用。
三、vrrp协议
vrrp协议是为了静态路由环境下防止单点故障而设计的主从灾备协议,在主设备发生故障时业务自动切换至从设备,而这一切对于用户而言是透明的。vrrp将两台或多台设备虚拟成一个设备,对外仅提供一个虚拟的IP地址,这些设备在同一时刻仅有一台设备可有拥有该IP地址,而拥有该IP地址的设备就是主设备,其它的就是备用设备。主设备会不断发送自己的状态信息给备用设备,当备用设备接收不到主设备的状态信息时,多个备用设备会根据自身的优先级选择出新的主设备,并拥有所有的业务功能。vrrp协议需要为每个路由设备定义一个虚拟路由ID(VRID)以及优先,所有主备路由设备的VRID必须一样,这样才会被视为同一组设备,而优先级最高的设备就是主路由设备,VRID和优先级的范围为0-255之间的整数,数值越大优先级越高,如果优先级相等,则会对比IP地址,地址越大优先级越高
keepalived安装部署
安装keepalived
# CentOS7
yum install -y keepalived
# Ubuntu
apt install -y keepalived
查看keepalived版本
[root@keepalived /etc/keepalived]# keepalived -v
Keepalived v1.3.5 (03/19,2017), git commit v1.3.5-6-g6fa32f2
更改keepalived配置
cd /etc/keepalived
vim keepalived.conf
主要修改分配的虚拟ip地址等配置。
启动keepalived
systemctl start keepalived.service
或者
service keepalived start`
**其他相关命令**
1)重启:
systemctl restart keepalived
2)停止:
systemctl stop keepalived
3)状态:
systemctl status keepalived
4)开机重启:
systemctl enable keepalived
查看keepalived状态
$ systemctl status keepalived
查看keepalived进程
$ ps -ef | grep keepalived
查看ip列表
$ ip add show
配置文件说明
[root@lvs1 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs { #全局配置
notification_email { #指定keepalived在发生切换时需要发送email到的对象,一行一个
acassen@firewall.loc #指定收件人邮箱
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc #指定发件人
smtp_server 192.168.200.1 #指定smtp服务器地址
smtp_connect_timeout 30 #指定smtp连接超时时间
router_id LVS_DEVEL #此处注意router_id为负载均衡标识,在局域网内应该是唯一的。
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 { #虚拟路由的标识符
state MASTER #状态只有MASTER和BACKUP两种,并且要大写,MASTER为工作状态,BACKUP是备用状态
interface eth0 #通信所使用的网络接口
virtual_router_id 51 #虚拟路由的ID号,是虚拟路由MAC的最后一位地址
priority 100 #此节点的优先级,主节点的优先级需要比其他节点高
advert_int 1 #通告的间隔时间
authentication { #认证配置
auth_type PASS #认证方式
auth_pass 1111 #认证密码
}
virtual_ipaddress { #虚拟ip地址,可以有多个地址,每个地址占一行,不需要子网掩码,同时这个ip 必须与我们在lvs 客户端设定的vip 相一致!
192.168.200.16
192.168.200.17
192.168.200.18
}
}
virtual_server 192.168.200.100 443 { #集群所使用的VIP和端口
delay_loop 6 #健康检查间隔,单位为秒
lb_algo rr #lvs调度算法rr|wrr|lc|wlc|lblc|sh|dh
nat_mask 255.255.255.0 #VIP掩码
lb_kind NAT #负载均衡转发规则。一般包括DR,NAT,TUN 3种
persistence_timeout 50 #会话保持时间,会话保持,就是把用户请求转发给同一个服务器,不然刚在1上提交完帐号密码,就跳转到另一台服务器2上了
protocol TCP #转发协议,有TCP和UDP两种,一般用TCP,没用过UDP
real_server 192.168.200.100 443 { #真实服务器,包括IP和端口号
weight 1 #权重
TCP_CHECK { #通过tcpcheck判断RealServer的健康状态
connect_timeout 3 #连接超时时间
nb_get_retry 3 #重连次数
delay_before_retry 3 #重连间隔时间
connect_port 23 #健康检查的端口的端口
bindto <ip>
}
HTTP_GET { #健康检测方式,可选有 SSL_GET、TCP_CHECK、HTTP_GET
url { #检查url,可以指定多个
path / #检查的url路径
digest ff20ad2481f97b1754ef3e12ecd3a9cc #需要检查到的内容。检查后的摘要信息。
}
url {
path /mrtg
digest 9b3a0c85a887a256d6939da88aabd8cd
}
url {
path /testurl3/test.jsp
digest 640205b7b0fc66c1ea91c463fac6334d
}
connect_timeout 3 #连接超时时间
nb_get_retry 3 #检测尝试几次
delay_before_retry 3 #检测的时间间隔
}
}
}
访问
配置好keepalived启动后,我们就可以通过192.168.8.100这个VIP进行服务的访问。
keepalived高可用配置文件详解
主节点
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
# notification_email { # 邮件通知,一般不用
# test1@163.com
# test2@163.com
# }
# notification_email_from test@163.com
router_id hostname1 # 标识本节点的字符串,设置为hostname即可
}
vrrp_instance VI_1 {
state MASTER # 标识主节点服务(只有MASTER和BACKUP两种,大写)
interface ens33 # VIP板顶的网卡接口
virtual_router_id 51 # 虚拟路由id,和备节点保持一致
priority 100 # 优先级,高于备节点的即可。
# nopreempt # 禁止MASTER宕机恢复后抢占服务
# smtp_alert # 激活故障时发送邮件告警
mcast_src_ip 192.168.8.60 # 本机IP地址
advert_int 1 # MASTER和BACKUP节点之间的同步检查时间间隔,单位为秒
authentication { # 验证类型和验证密码
auth_type PASS # PAAS(默认),HA
auth_pass 1234 # MASTER和BACKUP使用相同明文才可以互通
}
virtual_ipaddress { # 虚拟IP地址池,可以多个IP
192.168.8.100 # 虚拟IP1(VIP)
192.168.8.110 # 虚拟IP2(VIP)
}
}
备节点
除了注释#内容以外,其他都和主节点保持一致。
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id hostname2 # 标识本节点的字符串,设置为hostname即可
}
vrrp_instance VI_1 {
state BACKUP # 标识主节点服务(只有MASTER和BACKUP两种,大写)
interface ens33
virtual_router_id 51
priority 99 # 优先级,低于主节点的即可。
mcast_src_ip 192.168.8.70 # 本机IP地址
advert_int 1
authentication {
auth_type PASS
auth_pass 1234
}
virtual_ipaddress {
192.168.8.100
192.168.8.110
}
}
Keepalived高可用裂脑
什么是裂脑?
由于某些原因,导致两台高可用服务器对在指定时间内,无法检测到对方的心跳消息,各自取得资源及服务的所有权,而此时的两台高可用服务器对都还活着并在正常运行,这样就会导致同一个IP或服务在两端同时存在而发生冲突,最严重的是两台主机占用同一个VIP地址,当用户写入数据时可能会分别写入到两端,这可能会导致服务器两端的数据不一致或造成数据丢失,这种情况就被称为裂脑。
裂脑的原因
1)高可用服务器对之间心跳线链路故障,导致无法正常通信。
2)高可用服务器对上开启了iptables防火墙阻挡了心跳消息传输。
3)高可用服务器对上心跳网卡地址等信息配置不正确,导致发送心跳失败。
4)keepalived配置问题。
解决裂脑的常见方案
1)同时使用串行电缆和以太网电缆连接,同时用两条心跳线路
2)当检测到裂脑时强行关闭一个心跳节点(这个功能需特殊设备支持,如Stonith 、fence)。相当于备节点接收不到心跳消息,发送关机命令通过单独的线路关闭主节点的电源。 fence和Stonith设备其实就是一个智能电源。