RAID简介
RAID(冗余阵列独立磁盘)是一种将多个物理磁盘组合在一起以提供数据冗余或性能增强的技术。
1988年,美国加利福尼亚大学伯克利分校首次提出并定义了RAID技术的概念。RAID技术通过把多个硬盘设备组合成一个容量更大、安全性更好的磁盘阵列,并把数据切割成多个区段后分别存放在各个不同的物理硬盘设备上,然后利用分散读写技术来提升磁盘阵列整体的性能,同时把多个重要数据的副本同步到不同的物理硬盘设备上,从而起到了非常好的数据冗余备份效果。
1. RAID 0
RAID 0技术把多块物理硬盘设备(至少两块)通过硬件或软件的方式串联在一起,组成一个大的卷组,并将数据依次写入各个物理硬盘中。这样一来,在最理想的状态下,硬盘设备的读写性能会提升数倍,但是若任意一块硬盘发生故障,将导致整个系统的数据都受到破坏。通俗来说,RAID 0技术能够有效地提升硬盘数据的吞吐速度,但是不具备数据备份和错误修复能力。如下图所示,数据被分别写入到不同的硬盘设备中,即硬盘A和硬盘B设备会分别保存数据资料,最终实现提升读取、写入速度的效果。
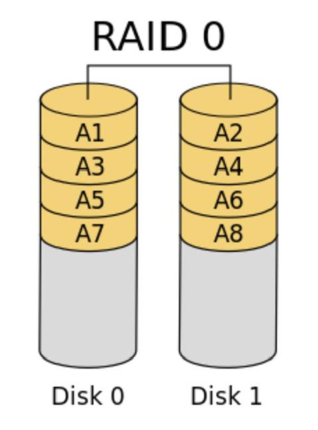
RAID 0的特点:
- 最少需要两块磁盘
- 数据条带式分布
- 没有冗余,性能最佳(不存储镜像、校验信息)
- 不能应用于对数据安全性要求高的场合
2. RAID 1
尽管RAID 0技术提升了硬盘设备的读写速度,但它是将数据依次写入到各个物理硬盘中。也就是说,它的数据是分开存放的,其中任何一块硬盘发生故障都会损坏整个系统的数据。因此,如果生产环境对硬盘设备的读写速度没有要求,而是希望增加数据的安全性时,就需要用到RAID 1技术了。
在下图所示的RAID 1技术示意图中可以看到,它是把两块以上的硬盘设备进行绑定,在写入数据时,是将数据同时写入到多块硬盘设备上(可以将其视为数据的镜像或备份)。当其中某一块硬盘发生故障后,一般会立即自动以热交换的方式来恢复数据的正常使用。
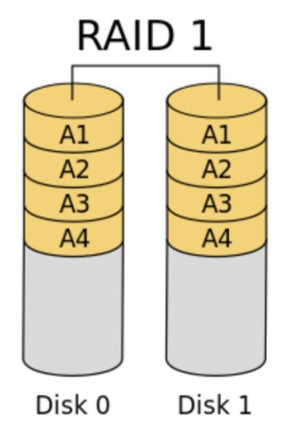
以下为RAID 1的特点:
- 最少需要2块磁盘
- 提供数据块冗余
- 性能好
考虑到在进行写入操作时因硬盘切换带来的开销,因此RAID 1的速度会比RAID 0有微弱地降低。但在读取数据的时候,操作系统可以分别从两块硬盘中读取信息,因此理论读取速度的峰值可以是硬盘数量的倍数。另外,平时只要保证有一块硬盘稳定运行,数据就不会出现损坏的情况,可靠性较高。
RAID 1技术虽然十分注重数据的安全性,但是因为是在多块硬盘设备中写入了相同的数据,因此硬盘设备的利用率得以下降。从理论上来说,上图所示的硬盘空间的真实可用率只有50%,由3块硬盘设备组成的RAID 1磁盘阵列的可用率只有33%左右;以此类推。而且,由于需要把数据同时写入到两块以上的硬盘设备,这无疑也在一定程度上增大了系统计算功能的负载。
3. RAID 5
如下图所示,RAID5技术是把硬盘设备的数据奇偶校验信息保存到其他硬盘设备中。RAID 5磁盘阵列中数据的奇偶校验信息并不是单独保存到某一块硬盘设备中,而是存储到除自身以外的其他每一块硬盘设备上。这样的好处是,其中任何一设备损坏后不至于出现致命缺陷。图中Parity部分存放的就是数据的奇偶校验信息。换句话说,就是RAID 5技术实际上没有备份硬盘中的真实数据信息,而是当硬盘设备出现问题后通过奇偶校验信息来尝试重建损坏的数据。RAID这样的技术特性“妥协”地兼顾了硬盘设备的读写速度、数据安全性与存储成本问题。
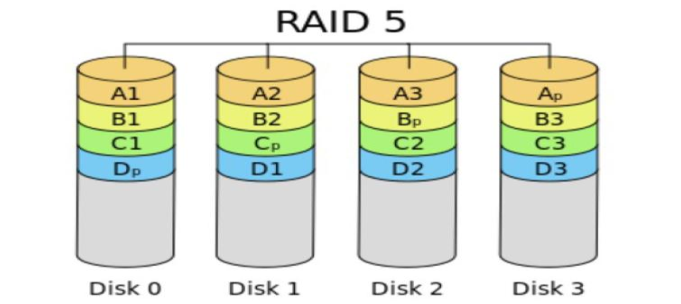
RAID 5特点:
- 最少3块磁盘
- 数据条带形式分布
- 以奇偶校验作冗余
- 适合多读少写的情景,是性能与数据冗余最佳的折中方案
RAID 5最少由3块硬盘组成,使用的是硬盘切割(Disk Striping)技术。相较于RAID 1级别,好处就在于保存的是奇偶校验信息而不是一模一样的文件内容,所以当重复写入某个文件时,RAID 5级别的磁盘阵列组只需要对应一个奇偶校验信息就可以,效率更高,存储成本也会随之降低。
4. RAID 10
RAID 5技术是出于硬盘设备的成本问题对读写速度和数据的安全性能有了一定的妥协,但是大部分企业更在乎的是数据本身的价值而非硬盘价格,因此在生产环境中主要使用RAID 10技术。
顾名思义,RAID 10技术是RAID 1+RAID 0技术的一个“组合体”。如下图所示,RAID 10技术需要至少4块硬盘来组建,其中先分别两两制作成RAID 1磁盘阵列,以保证数据的安全性;然后再对两个RAID 1磁盘阵列实施RAID 0技术,进一步提高硬盘设备的读写速度。这样从理论上来讲,只要坏的不是同一阵列中的所有硬盘,那么最多可以损坏50%的硬盘设备而不丢失数据。由于RAID 10技术继承了RAID 0的高读写速度和RAID 1的数据安全性,在不考虑成本的情况下RAID 10的性能也超过了RAID 5,因此当前成为广泛使用的一种存储技术。
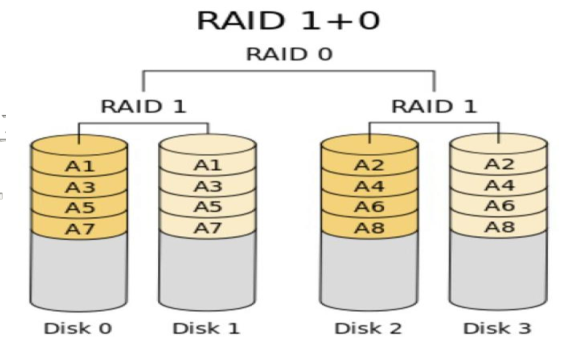
RAID 10(又叫RAID 1+0)特点:
- 最少需要4块磁盘
- 先按RAID 0分成两组,再分别对两组按RAID 1方式镜像
- 兼顾冗余(提供镜像存储)和性能(数据条带形分布)
- 在实际应用中较为常用
核心级别对比表格
| RAID 级别 | 最少硬盘数 | 读写性能 | 冗余能力 | 空间利用率 | 典型应用场景 | 核心特点 |
|---|---|---|---|---|---|---|
| RAID0 | 2 | 最优(并行) | 无(单盘故障全丢) | 100% | 临时缓存、视频编辑 | 性能优先,无安全保障 |
| RAID1 | 2 | 读好,写一般 | 允许 1 块故障(镜像) | 50% | 系统盘、重要文件存储 | 安全优先,性能中等 |
| RAID5 | 3 | 读好,写中等 | 允许 1 块故障(单校验) | (n-1)/n | 文件服务器、中小型数据库 | 平衡性能与冗余,成本适中 |
| RAID6 | 4 | 读好,写较差 | 允许 2 块故障(双校验) | (n-2)/n | 大容量存储、关键数据 | 高安全性,性能略低 |
| RAID10 | 4 | 极佳(并行 + 镜像) | 允许每组 1 块故障 | 50% | 高 IO 数据库、交易系统 | 高性能 + 高安全,成本高 |
总结与选择建议
- 追求极致性能,不关心数据安全 → RAID0;
- 数据安全第一,性能要求不高 → RAID1;
- 平衡性能、冗余与成本 → RAID5;
- 数据绝对不能丢(允许双盘故障) → RAID6;
- 高性能 + 高安全(预算充足) → RAID10。
部署磁盘阵列
当前,生产环境中用到的服务器一般都配备RAID阵列卡,尽管服务器的价格越来越便宜,但是我们没有必要为了做一个实验而去单独购买一台服务器,而是可以学会使用mdadm命令在Linux系统中创建和管理软件RAID磁盘阵列,而且它涉及的理论知识和操作过程与生产环境中的完全一致。
mdadm用于创建、调整、监控和管理RAID设备,英文全称为“multiple devices admin”,语法格式为“mdadm参数 硬盘名称”。
yum install mdadm
1.添加四块硬盘设备
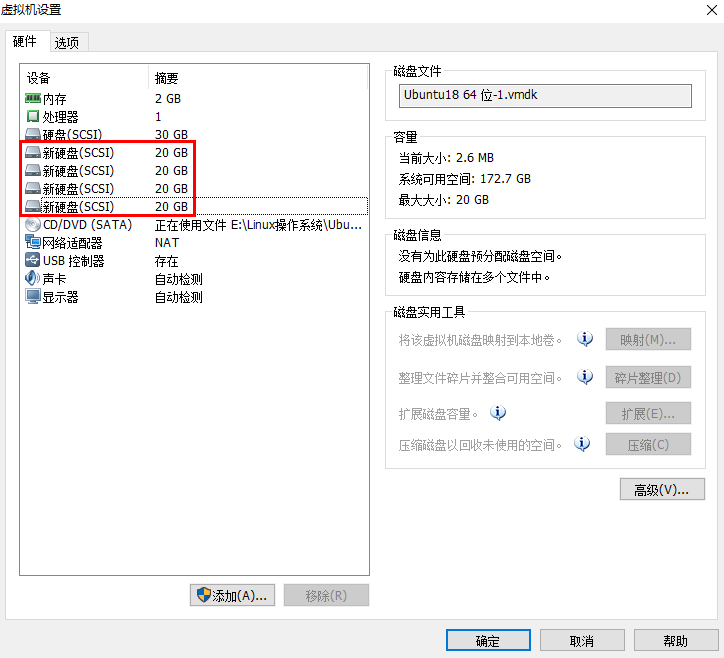
mdadm命令的常用参数和作用
| 参数 | 作用 |
|---|---|
| -a | 检测设备名称 |
| -n | 指定设备数量 |
| -l | 指定RAID级别 |
| -C | 创建 |
| -v | 显示过程 |
| -f | 模拟设备损坏 |
| -r | 移除设备 |
| -Q | 查看摘要信息 |
| -D | 查看详细信息 |
| -S | 停止RAID磁盘阵列 |
-C参数代表创建一个RAID阵列卡;-v参数显示创建的过程,同时在后面追加一个设备名称/dev/md0,这样/dev/md0就是创建后的RAID磁盘阵列的名称;-n 4参数代表使用4块硬盘来部署这个RAID磁盘阵列;而-l 10参数则代表RAID 10方案;最后再加上4块硬盘设备的名称就搞定了。
[root@zuolaoshi ~]# mdadm -Cv /dev/md0 -n 4 -l 10 /dev/sdb /dev/sdc /dev/sdd /dev/sde
mdadm: layout defaults to n2
mdadm: layout defaults to n2
mdadm: chunk size defaults to 512K
mdadm: size set to 20954112K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
初始化过程大约需要1分钟左右,期间可以用-D参数进行查看。也可以用-Q参数查看简要信息:
[root@zuolaoshi ~]# mdadm -Q /dev/md0
/dev/md0: 39.97GiB raid10 4 devices, 0 spares. Use mdadm --detail for more detail.
等两三分钟后,把制作好的RAID磁盘阵列格式化为Ext4格式:
[root@zuolaoshi ~]# mkfs.ext4 /dev/md0
mke2fs 1.44.3 (10-July-2018)
Creating filesystem with 10477056 4k blocks and 2621440 inodes
Filesystem UUID: d1c68318-a919-4211-b4dc-c4437bcfe9da
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624
Allocating group tables: done
Writing inode tables: done
Creating journal (65536 blocks): done
Writing superblocks and filesystem accounting information: done
随后,创建挂载点,将硬盘设备进行挂载操作:
[root@zuolaoshi ~]# mkdir /RAID
[root@zuolaoshi ~]# mount /dev/md0 /RAID
[root@zuolaoshi ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 969M 0 969M 0% /dev
tmpfs 984M 0 984M 0% /dev/shm
tmpfs 984M 9.6M 975M 1% /run
tmpfs 984M 0 984M 0% /sys/fs/cgroup
/dev/mapper/rhel-root 17G 3.9G 14G 23% /
/dev/sr0 6.7G 6.7G 0 100% /media/cdrom
/dev/sda1 1014M 152M 863M 15% /boot
tmpfs 197M 16K 197M 1% /run/user/42
tmpfs 197M 3.5M 194M 2% /run/user/0
/dev/md0 40G 49M 38G 1% /RAID
再来查看/dev/md0磁盘阵列设备的详细信息,确认RAID级别(Raid Level)、阵列大小(Array Size)和总硬盘数(Total Devices)都是否正确:
[root@zuolaoshi ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Jan 13 08:24:58 2021
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Jan 14 04:49:57 2021
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host linuxprobe.com)
UUID : 289f501b:3f5f70f9:79189d77:f51ca11a
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync set-A /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
如果想让创建好的RAID磁盘阵列能够一直提供服务,不会因每次的重启操作而取消,那么一定要记得将信息添加到/etc/fstab文件中,这样可以确保在每次重启后RAID磁盘阵列都是有效的。
[root@zuolaoshi ~]# echo "/dev/md0 /RAID ext4 defaults 0 0" >> /etc/fstab
[root@zuolaoshi ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Tue Jul 21 05:03:40 2020
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
/dev/mapper/rhel-root / xfs defaults 0 0
UUID=2db66eb4-d9c1-4522-8fab-ac074cd3ea0b /boot xfs defaults 0 0
/dev/mapper/rhel-swap swap swap defaults 0 0
/dev/cdrom /media/cdrom iso9660 defaults 0 0
/dev/md0 /RAID ext4 defaults 0 0
损坏磁盘阵列及修复
之所以在生产环境中部署RAID 10磁盘阵列,就是为了提高存储设备的IO读写速度及数据的安全性,但因为我们的硬盘设备是在虚拟机中模拟出来的,所以对于读写速度的改善可能并不直观。下面决定给同学们讲解一下RAID磁盘阵列损坏后的处理方法,以确保大家以后在步入运维岗位后不会因为突发事件而手忙脚乱。
在确认有一块物理硬盘设备出现损坏而不能再继续正常使用后,应该使用mdadm命令将其移除,然后查看RAID磁盘阵列的状态,可以发现状态已经改变:
[root@zuolaoshi ~]# mdadm /dev/md0 -f /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
[root@zuolaoshi ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Jan 14 05:12:20 2021
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Jan 14 05:33:06 2021
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 1
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 81ee0668:7627c733:0b170c41:cd12f376
Events : 19
Number Major Minor RaidDevice State
- 0 0 0 removed
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
0 8 16 - faulty /dev/sdb
刚刚使用的-f参数是让硬盘模拟损坏的效果。为了能够彻底地将故障盘移除,还要再执行一步操作:
[root@zuolaoshi ~]# mdadm /dev/md0 -r /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md0
在RAID 10级别的磁盘阵列中,当RAID 1磁盘阵列中存在一个故障盘时并不影响RAID 10磁盘阵列的使用。当购买了新的硬盘设备后再使用mdadm命令予以替换即可,在此期间可以在/RAID目录中正常地创建或删除文件。由于我们是在虚拟机中模拟硬盘,所以先重启系统,然后再把新的硬盘添加到RAID磁盘阵列中。
更换硬盘后再次使用-a参数进行添加操作,系统默认会自动开始数据的同步工作。使用-D参数即可看到整个过程和进度(用百分比表示):
[root@zuolaoshi ~]# mdadm /dev/md0 -a /dev/sdb
mdadm: added /dev/sdb
[root@zuolaoshi ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Jan 14 05:12:20 2021
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Jan 14 05:37:32 2021
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 77% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 81ee0668:7627c733:0b170c41:cd12f376
Events : 34
Number Major Minor RaidDevice State
4 8 16 0 spare rebuilding /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde