什么是API
API作为一个互联网行业的术语,很少被直接翻译过来,因为在中文中并没有一个对应的词汇可以完全表达其含义,如果强行翻译,可以被翻译为数据接口,但显然这个翻译并不准确。
举个现实中的例子,比如购房网上面有全国房屋买卖的交易数据,万达公司在需要一些房屋交易数据来作为参考投产项目时,如果自己去做社会调研,费时、费力,非常不合算,所以万达公司每年都要向购房网支付数百万元来购买这些交易数据。大家是否考虑过,这一笔交易是以怎样的方式进行的呢?所谓的一手交钱一手交货,交钱的流程比较简单,只要万达公司将资金汇给购房网就可以了,但是购房网是怎样将全国房屋买卖的交易数据交给万达公司呢?难道是直接将数据库复制给万达公司一份吗?这显然不可能。购房网是将一些API和权限交给万达公司的技术人员,万达公司的技术人员就可以通过调用这些API获取到他们所需要的交易数据。当然,API是一个广义的概念,除了可以通过调用API获取到数据资源外,还可以通过API提供和获取技术服务,在无数的SDK(软件开发包)中都有所体现。在本章中,我们主要是通过API获取数据。
在业内编写这类API,不论是使用什么编程语言,都需要遵循RESTful规范,当然这是众所周知的事情。
RESTful规范——如何写API
API接口应该如何写?API跟URL有什么不同?这绝对是不可以被忽略的问题,如果API写得乱七八糟,很有可能会失去负责前端开发的同事的信任。将API写得“高大上”,也是一名开发者工匠精神的一种体现。下面来介绍如何写API。
(1)如果是对同一个表进行数据操作(增、删、改、查),应该使用一条API,然后根据method的不同,进行不同的操作。

(2)面向资源编程,通过API提交的参数最好是名词,比如name,尽量少用动词。

(3)体现版本,在API中加入像v1、v2这样的版本代号:

(4)体现API,让使用者一眼能看出这是API而不是URL,应该在API中加入提示:

(5)使用HTTPS,这一项原本是为了安全考虑,但是随着国内外互联网环境对安全性越来越重视,谷歌浏览器对所有不是HTTPS请求的链接全都会提示用户此链接为不安全链接,腾讯等平台也对小程序等产品强制要求使用HTTPS协议。不过,好在国内许多提供云服务的公司,像腾讯云、阿里云等,都提供免费的SSL证书,供开发者去申请。

(6)响应式设置状态码,例如,200和201代表操作成功,403代表权限不够,404代表没有指定资源,500代表运行时发现代码逻辑错误等。
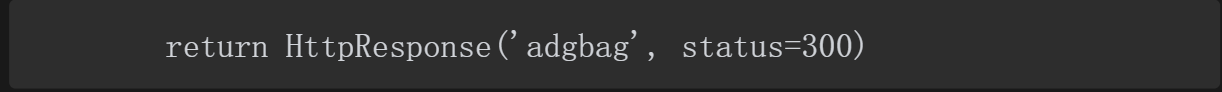
(7)API的参数中加入筛选条件参数,也可以理解为获取资源优先选择GET的方式。

(8)返回值的规范,不同的method操作成功后,后端应该响应的返回值如下:
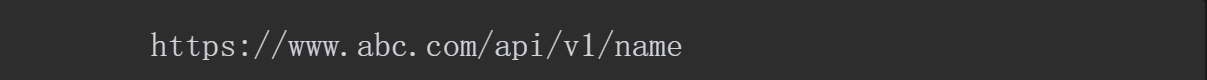
不同的提交方式代表对数据进行不同的操作:
- GET:所有列表。
- POST:新增的数据。

- GET:单条数据。
- PUT:更新,返回更新的数据。
- PATCH:局部更新,返回更新的数据。
- DELETE:删除,返回空文档。
(9)返回错误信息,应该加入错误代号code,让用户能直接看出是哪种类型的错误。

(10)返回的详细信息,应该以字典的形式放在data中。

RESTful规范是业内约定俗成的规范,并不是技术上定义的公式,在实际生产使用中,大家还是要根据业务灵活运用。
Django REST framework简介
在Python的Web业内广为流传一句话“使用Python进行Web全栈开发者必会Django,使用Django开发前后端分离项目者必会Django REST framework”。
使用Python进行Web全栈开发的框架,主流的就有4个,但是大家除了使用Django以外,其他的都很少使用。Django本身也拥有一些模块,可以用于完成前后端分离项目的需求,但是大家除了使用Django REST framework以外,也很少使用其他模块。
如果可以将Django REST framework的10个常用组件融会贯通,那么使用Django开发前后端分离的项目中有可能遇到的绝大部分需求,都能得到高效的解决。
Django REST framework的10个常用组件如下:
-
权限组件;
-
认证组件;
-
访问频率限制组件;
-
序列化组件;
-
路由组件;
-
视图组件;
-
分页组件;
-
解析器组件;
-
渲染器组件;
-
版本组件。
Django REST framework官方文档的地址是https://www.django-rest-framework.org/。
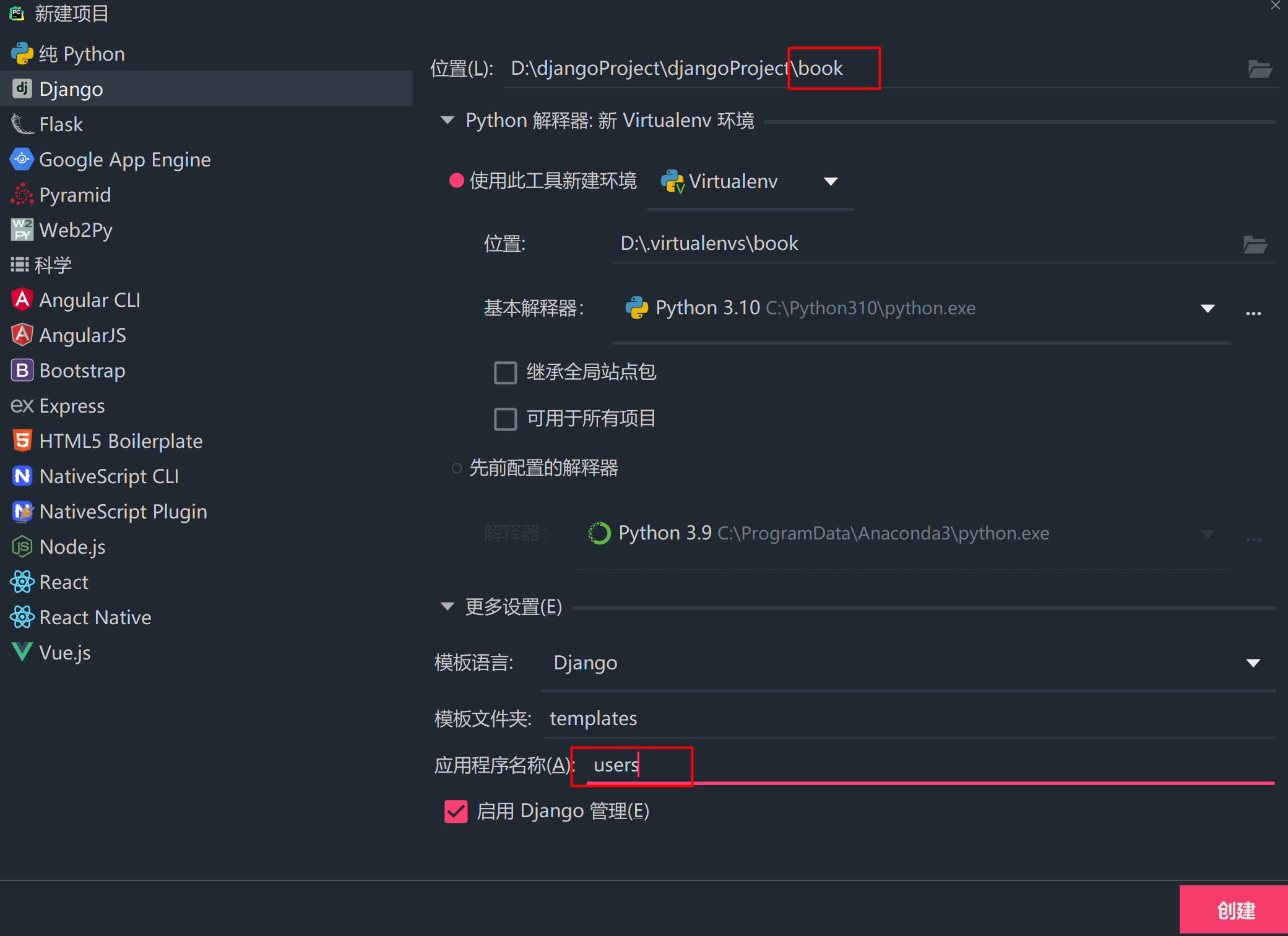
新建一个Django项目,命名为book,作为演示项目。选择PyCharm作为开发工具,在新建目录时,新建App命名为users。
用Django REST framework实现豆瓣API应用
豆瓣图书的API功能原理是用户通过输入图书的ISBN号(书号)、书名、作者、出版社等部分信息,就可获取到该图书在豆瓣上的所有信息。当然,API中除了要包含检索信息之外,还要包含开发者的apikey,用来记录开发者访问API的次数,以此向开发者收费。目前豆瓣图书的API是0.3元/100次。
Django REST framework序列化
序列化(Serialization)是指将对象的状态信息转换为可以存储或传输形式的过程。
在客户端与服务端传输的数据形式主要分为两种:XML和JSON。
在Django中的序列化就是指将对象状态的信息转换为JSON数据,以达到将数据信息传送给前端的目的。序列化是开发API不可缺少的一个环节,Django本身也有一套做序列化的方案,这个方案可以说已经做得很好了,但是若跟Django REST framework相比,还是不够极致,速度不够快。
用serializers.Serializer方式序列化
还记得我们在第1章中新建的Django项目book吗?下面我们来一起在这个项目中一步一步地通过Serializer序列化组件,完成豆瓣API核心功能的开发。(1)打开项目book。
(2)安装Django REST framework及其依赖包markdown和django-filter。命令如下:
pip install djangorestframework
# Markdown support for the browsable API.
pip install markdown
# Filtering support
pip install django-filter
( 3)在settings中注册,代码如下:
ALLOWED_HOSTS = ["*"]
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'users.apps.UsersConfig',
'rest_framework'
]
(4)设计users的models.py,重构用户表UserProfile,增加字段APIkey和money。当然,为了演示核心功能,可以建立一张最简单的表,大家可以根据个人喜好增加一些业务字段来丰富项目功能。
from django.db import models
from django.contrib.auth.models import AbstractUser
# Create your models here.
class UserProfile(AbstractUser):
"""
用户
"""
APIkey = models.CharField(max_length=30, verbose_name="APIkey", default="abcdefghijklmn")
money = models.DecimalField(default="10.0", max_digits=10, decimal_places=1, verbose_name="余额")
class Meta:
verbose_name = '用户'
verbose_name_plural = verbose_name
def __str__(self):
return self.username
(5)在settings中配置用户表的继承代码:
AUTH_USER_MODEL = 'users.UserProfile'
(6)在users的models.py文件中新建书籍信息表book,为了演示方便,我们姑且将作者字段并入书籍信息表,读者在实际项目中可根据业务模式灵活设计数据表model:
class Book(models.Model):
"""
书籍信息
"""
title = models.CharField(max_length=64, verbose_name="书名", default='')
isbn = models.CharField(max_length=32, verbose_name="isbn", default='')
author = models.CharField(max_length=32, verbose_name="作者", default='')
publish = models.CharField(max_length=32, verbose_name="出版社", default='')
rate = models.FloatField(default=0, verbose_name="豆瓣评分")
add_time = models.DateTimeField(default=datetime.now, verbose_name="添加时间")
class Meta:
verbose_name = "书籍信息"
verbose_name_plural = verbose_name
def __str__(self):
return self.title
(7)执行数据更新命令:
python manage.py makemigrations
python manage.py migrate
(8)建立一个超级用户,用户名为admin,邮箱为1@1.com,密码为admin1234。
python manage.py createsuperuser
Username: admin
Email address: 1@1.com
Password:
Password (again):
The password is too similar to the username.
This password is too common.
Bypass password validation and create user anyway? [y/N]: y
Superuser created successfully.
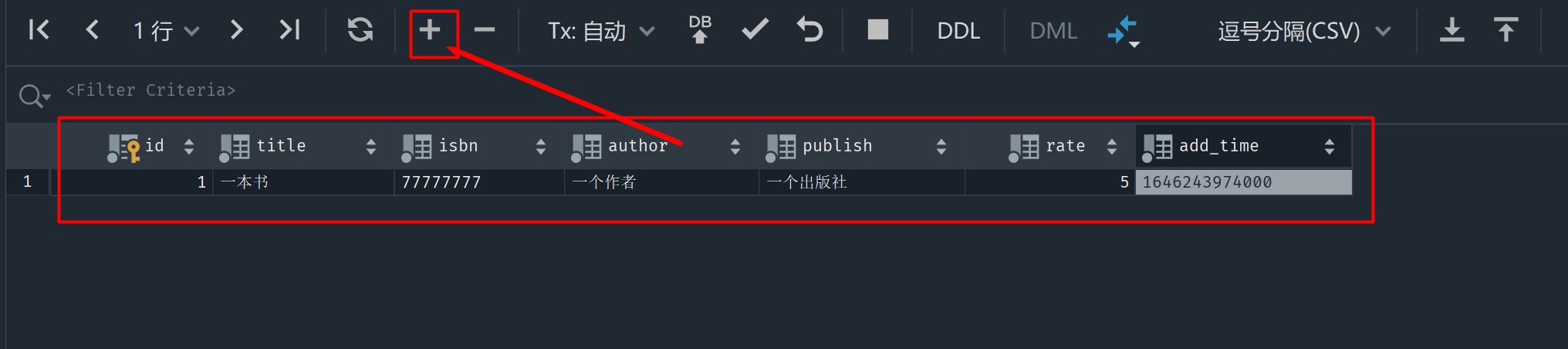
(9)通过PyCharm的Databases操作面板,直接在book表内增加一条记录,title为一个书名,isbn为77777777, author为一个作者,publish为一个出版社,rate为5, add_time为当前时间。
(10)准备工作已经完成,接下来是我们的“正片”开始啦。在users目录下新建py文件serializers.py,将序列化的类代码写入其中:
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
title = serializers.CharField(required=True, max_length=64)
isbn = serializers.CharField(required=True, max_length=32)
author = serializers.CharField(required=True, max_length=32)
publish = serializers.CharField(required=True, max_length=32)
rate = serializers.FloatField(default=0)
(11)在users/views中编写视图代码:
from django.shortcuts import render
from rest_framework.views import APIView
from rest_framework.response import Response
from users.models import UserProfile, Book
from users.serializers import BookSerializer
class BookAPIView1(APIView):
"""
使用Serializer
"""
def get(self, request, format=None):
APIkey = self.request.query_params.get('apikey', 0)
print(APIkey)
developer = UserProfile.objects.filter(APIkey=APIkey).first()
if developer:
balance = float(developer.money)
if balance > 0:
isbn = self.request.query_params.get('isbn', 0)
books = Book.objects.filter(isbn=int(isbn))
books_serializer = BookSerializer(books, many=True)
developer.money -= 1
developer.save()
return Response(books_serializer.data)
else:
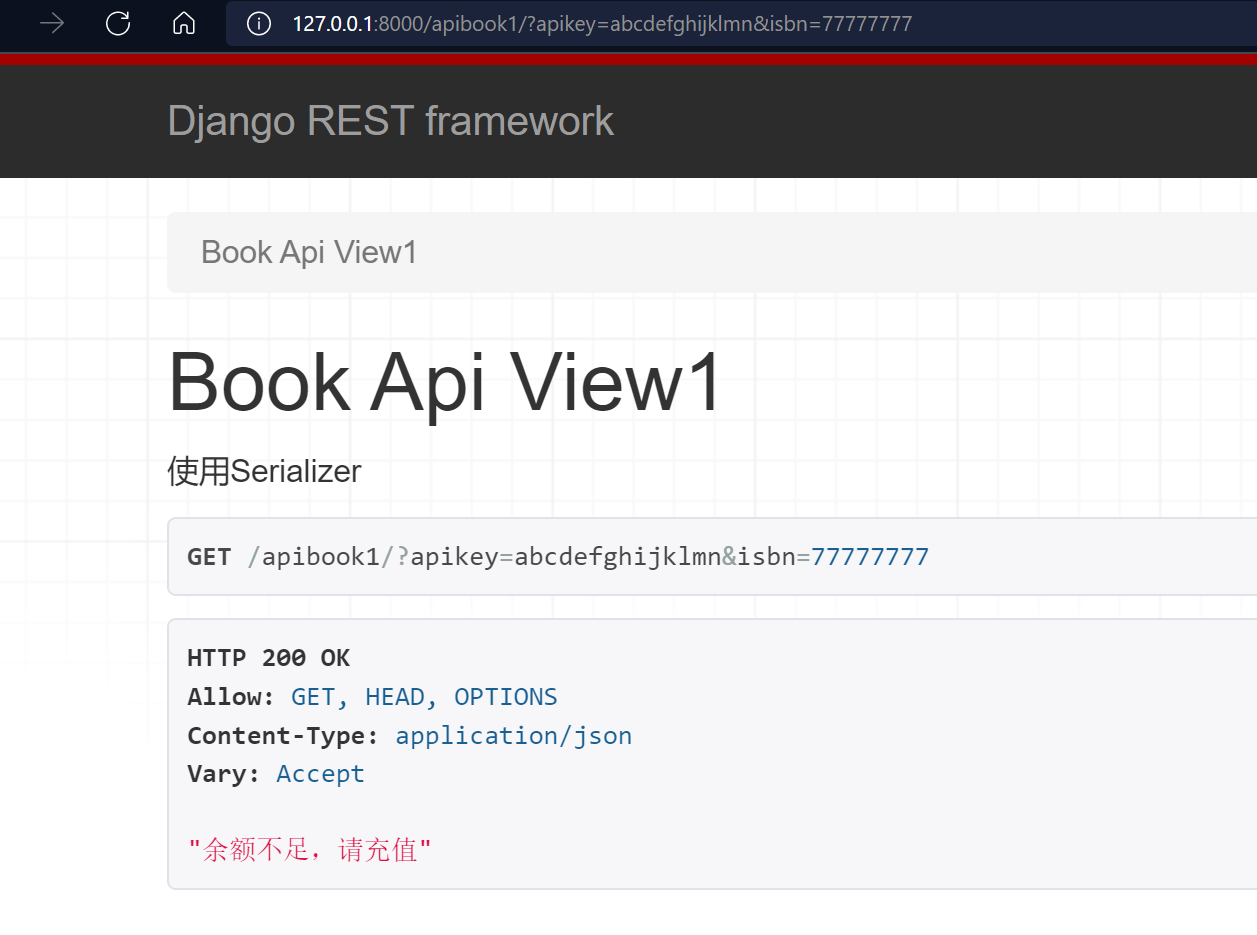
return Response("余额不足,请充值")
else:
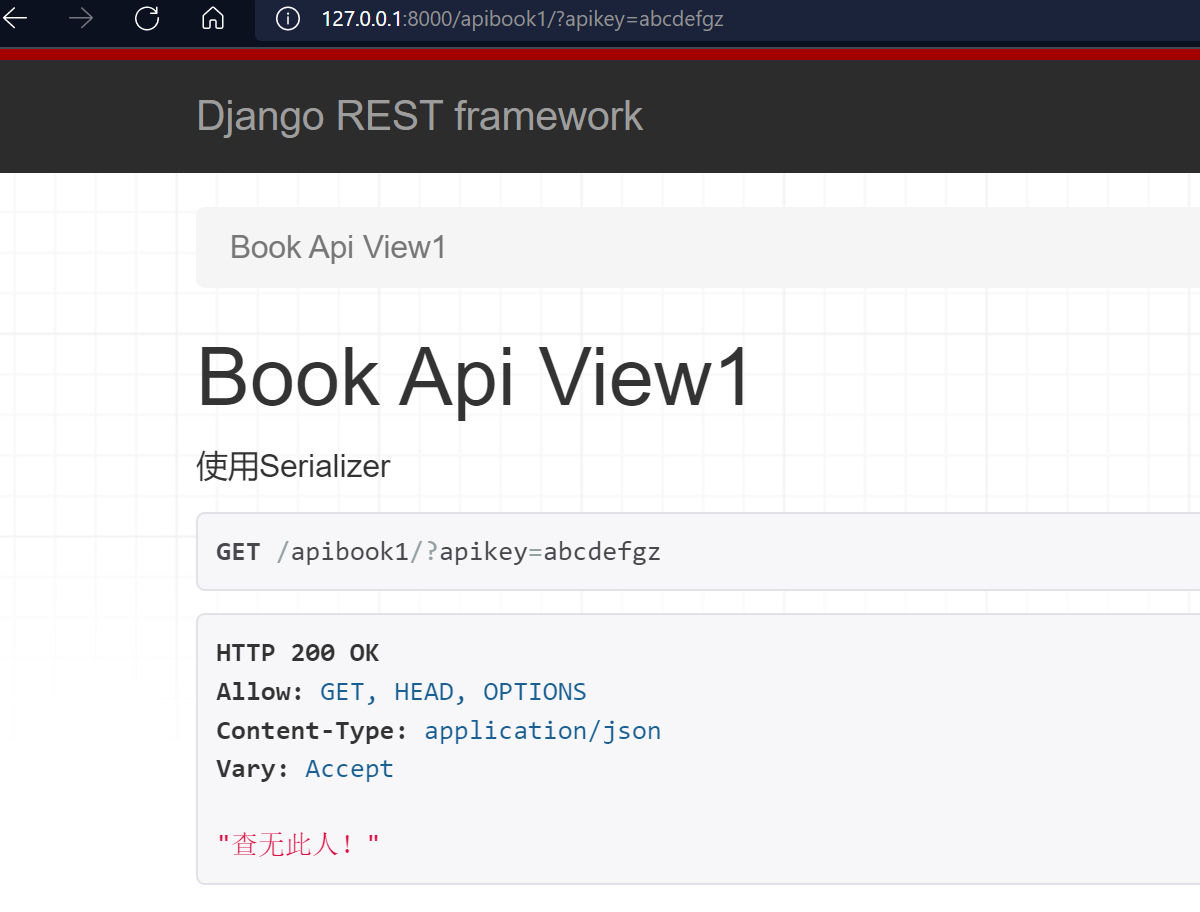
return Response("查无此人!")
(12)在urls中配置路由如下:
from django.contrib import admin
from django.urls import path
from users.views import BookAPIView1
urlpatterns = [
path('admin/', admin.site.urls),
path('apibook1/', BookAPIView1.as_view(), name='book1')
]
至此,我们可以运行book项目,并在浏览器访问:
http://127.0.0.1:8000/apibook1/?apikey=abcdefghijklmn&isbn=77777777
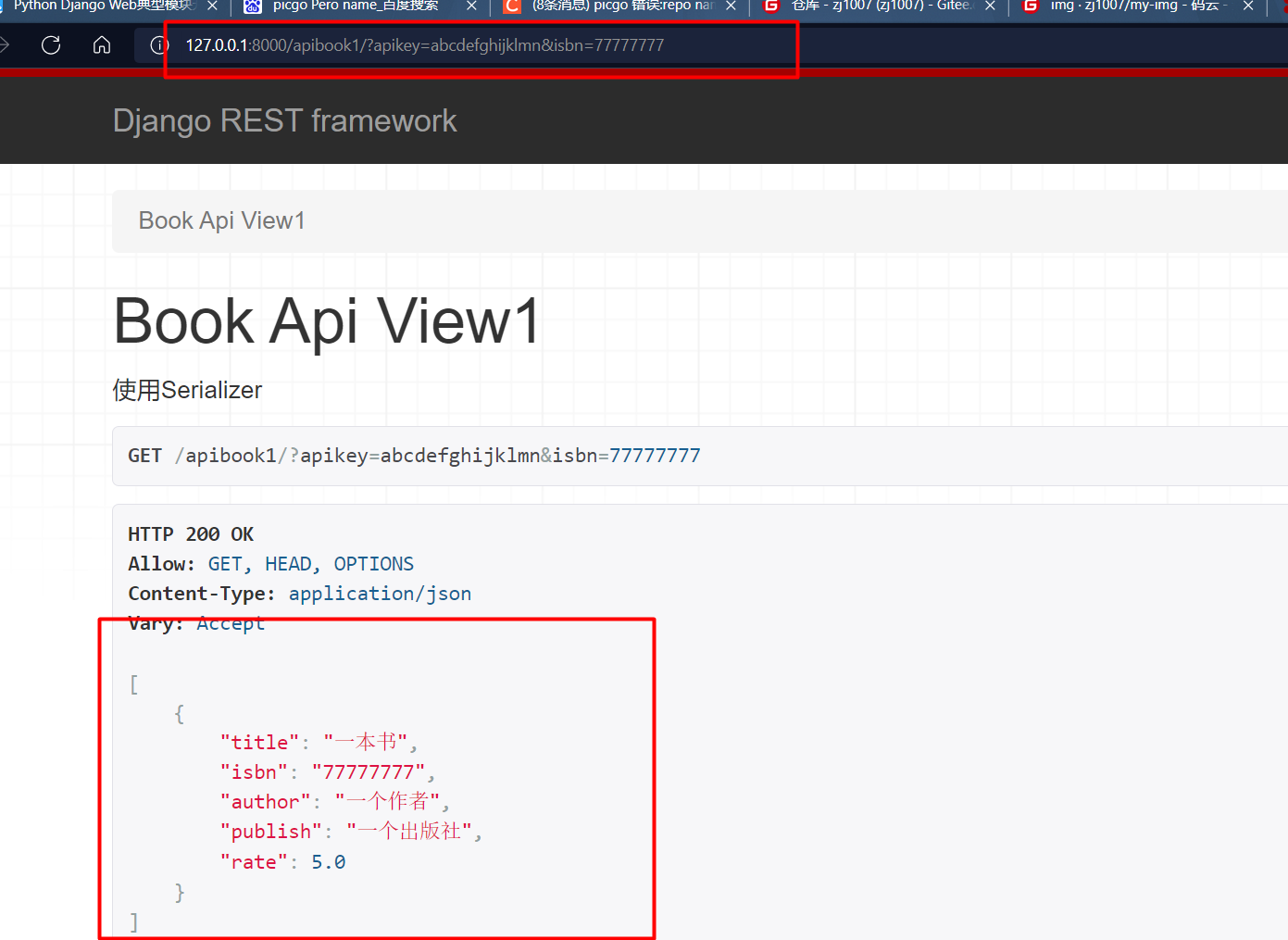
然后到数据库中查看一下,发现用户admin的money被减去了1,变成了9。

当我们用故意填错apikey时,访问:
当我们连续访问10次后:
http://127.0.0.1:8000/apibook1/?apikey=abcdefghijklmn
至此,一个简单的模仿豆瓣图书API的功能就实现了。在实际的项目中,这样的实现方式虽然原理很清晰,但是存在着很明显的短板,比如被查询的表的字段不可能只有几个,我们在真正调用豆瓣图书API的时候就会发现,即使只查询一本书的信息,由于有很多的字段和外键字段,返回的数据量也会非常大。如果使用Serializer进行序列化,那么工作量实在太大,严重影响了开发效率。
所以,这里使用Serializer进行序列化,目的是让大家通过这种序列化方式更加轻松地理解Django REST framework的序列化原理。在实际生产环境中,更加被广泛应用的序列化方式是采用了Django REST framework的ModelSerializer。
用serializers.ModelSerializer方式序列化
我们现在要做的,首先是到数据库中的UserProfile表中,将用户admin的money从0修改回10,不然API只能返回提醒充值的数据。
在users/Serializer.py中,写book的ModelSerializer序列化类:
from rest_framework import serializers
from users.models import Book
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = '__all__'
在users/views.py中,编写基于 BookModelSerializer的图书API视图类:
from users.serializers import BookModelSerializer
class BookAPIView2(APIView):
"""
使用Serializer
"""
def get(self, request, format=None):
APIkey = self.request.query_params.get('apikey', 0)
developer = UserProfile.objects.filter(APIkey=APIkey).first()
if developer:
balance = float(developer.money)
if balance > 0:
isbn = self.request.query_params.get('isbn', 0)
books = Book.objects.filter(isbn=int(isbn))
books_serializer = BookModelSerializer(books, many=True)
developer.money -= 1
developer.save()
return Response(books_serializer.data)
else:
return Response("余额不足,请充值")
else:
return Response("查无此人!")
注意:使用ModelSerializer序列化对应的视图类与使用Serializer进行序列化对应的视图类,除了序列化的方式不同,其他的代码都是相同的。
在urls中配置路由代码:
from django.contrib import admin
from django.urls import path
from users.views import BookAPIView1, BookAPIView2
urlpatterns = [
path('admin/', admin.site.urls),
path('apibook1/', BookAPIView1.as_view(), name='book1'),
path('apibook2/', BookAPIView2.as_view(), name='book2')
]
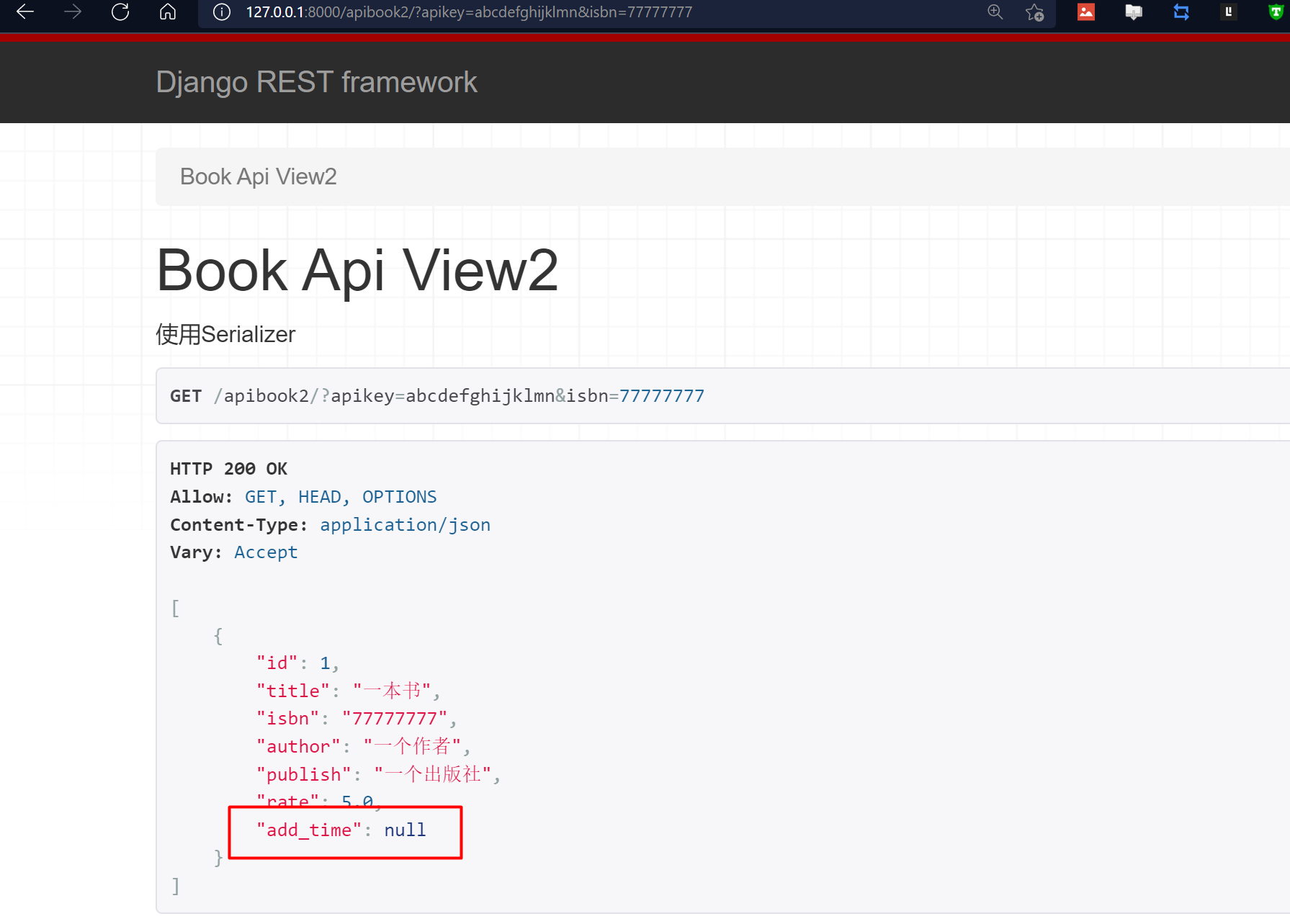
注意:这里的add_time字段为null,是因为这个项目使用了Django默认的db.sqlite3数据库。由于db.sqlite3在存储时间字段的时候,是以时间戳的格式保存的,所以直接使用Django REST framework的Serializer进行序列化失败。在实际项目中,我们会选择MySQL等主流数据库,就不会出现这种情况了。
可以看出,对于一条有很多字段的数据记录来说,使用ModelSerializer的序列化方式,可以一句话将所有字段序列化,非常方便。当然,ModelSerializer也可以像Serializer一样对某几个特定字段进行序列化,写法也很简单,只需要对原本的BookModelSerializer修改一行代码:
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = Book
# fields = '__all__'
fields = ('title', 'isbn', 'author')
返回的数据就成了:
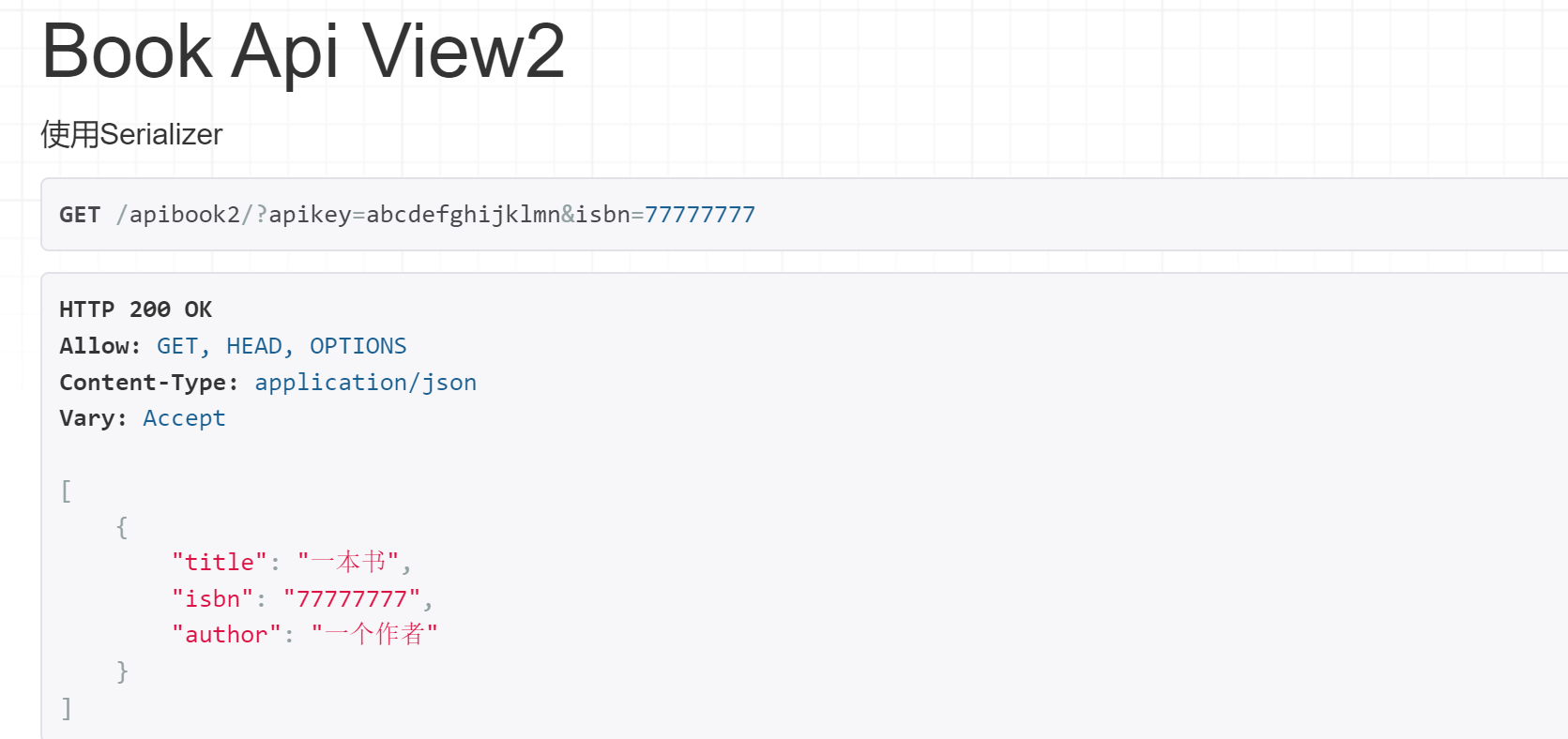
至此,我们对Django REST framework的两种序列化方式做一个总结:Serializer和ModelSerializer两种序列化方式中,前者比较容易理解,适用于新手;后者则在商业项目中被使用的更多,在实际开发中建议大家多使用后者。ModelSerializer有Serializer所有的优点,同时并没有比Serializer明显的不足之外,所以ModelSerializer比Serializer更优。