Pandas入门
Pandas是Python数据分析的利器,也是各种数据建模的标准工具。
在Python语言应用生态中,数据科学领域近年来十分热门。作为数据科学中一个非常基础的库,Pandas受到了广泛关注。Pandas可以将现实中来源多样的数据进行灵活处理和分析。
安装pandas
pip install pandas
为什么学习pandas
- numpy已经可以帮助我们进行数据的处理了,那么学习pandas的目的是什么呢?
- numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数值型的数据还有好多其他类型的数据(字符串,时间序列),那么pandas就可以帮我们很好的处理除了数值型的其他数据!
- Pandas是基于强大的NumPy库开发的,它继承了NumPy中的一些数据结构,也继承了NumPy的高效计算特性。
Pandas提供Series和DataFrame作为数组数据的存储框架,数据进入这两种框架后,我们就可以利用它们提供的强大处理方法进行处理。
- Series
- DataFrame
Series
- Series是一种类似与一维数组的对象,由下面两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
- Series的创建
- 由列表或numpy数组创建
- 由字典创建
DataFrame
-
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
-
DataFrame的创建
- ndarray创建
- 字典创建
| 名称 | 维度 | 描述 |
|---|---|---|
| Series | 1 | 带标签的一维同构数组 |
| DataFrame | 2 | 带标签、大小可变的的二维异构表格 |
需要注意的是,Pandas之前支持的三维面板(Panel)结构现已不再支持,可以使用多层索引形式来实现。
Series
Series(系列、数列、序列)是一个带标签的一维数组。
#2019年GDP单位万亿
中国 14.34
美国 21.34
日本 5.08
dtype:float64
其中,国家是标签(也称索引),不是具体的数据,它起到解释、定位数据的作用。如果没有标签,只有一个数字,是不具有业务意义的。Series是Pandas最基础的数据结构。
DataFrame
DataFrame意为数据框,它就像一个存放数据的架子,有多行多列,每个数据在一个格子里,每个格子有自己的编号。
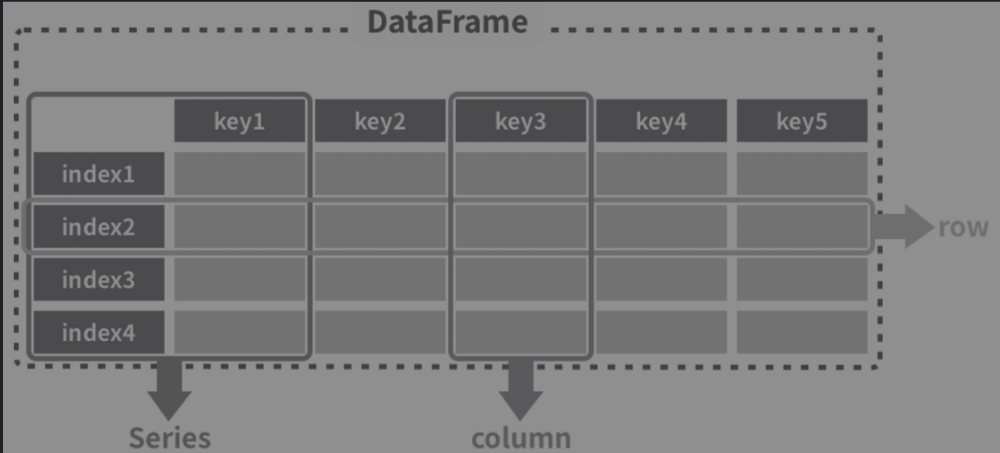
我们来分析一下它的结构:横向的称作行(row),我们所说的一条数据就是指其中的一行;纵向的称作列(column)或者字段,是一条数据的某个值;第一行是表头,或者叫字段名,类似于Python字典里的键,代表数据的属性;第一列是索引,就是这行数据所描述的主体,也是这条数据的关键;在一些场景下,表头和索引也称为列索引和行索引;行索引和列索引可能会出现多层索引的情况(后面会遇到)。
我们给上例国家GDP Series数据中增加一列“人口”,形成一个DataFrame:
GDP 人口
中国 14.34 13.97
美国 21.34 3.28
日本 5.08 1.26
这就是一个典型的DataFrame结构,其中:共有三行两列(不包含索引)数据;国家所在列是这个表的索引,每一行数据的主体为这个国家;每条数据(横向)有两个值,分别是GDP和人口。
索引
- 索引(index):行和列上的标签,标识二维数据坐标的行索引和列索引,默认情况下,指的是每一行的索引。如果是Series,那只能是它行上的索引。列索引又被称为字段名、表头。
- 自然索引、数字索引:行和列的0~n(n为数据长度–1)形式的索引,数据天然具有的索引形式。虽然可以指定为其他名称,但在有些方法中依然可以使用。
- 标签(label):行索引和列索引,如果是Series,那只能是它行上的索引。
- 轴(axis):仅用在DataFrame结构中,代表数据的方向,如行和列,用0代表列(默认),1代表行。以上概念比较依赖语境,需要灵活理解和掌握。
小结
我们在处理数据时需要将数据录入Excel表格,同样,Pandas也为我们提供了存放数据的容器。Series和DataFrame是Pandas的两个基本的数据结构,其中DataFrame由多个同索引的Series组成,我们今后处理数据都会用到它们。
Pandas生成数据
今后我们处理的数据基本上是Pandas的DataFrame和Series,其中DataFrame是Series的容器,所以需要掌握数据生成方法。现在我们学习如何制造一些简单数据放入DataFrame和Series,后面会单独讲解如何从文件(如Excel)中读取和生成数据。
导入pandas
import pandas as pd
import numpy as np
创建数据
df = pd.DataFrame({
'国家':['中国','美国','日本'],
'地区':['亚洲','北美','亚洲'],
'人口':[13.97, 3.28, 1.26],
'GDP':[14.34, 21.43, 5.08]
})
print(df)
执行结果如下:
(env38) zuojie@zuojie-PC:~/Code/python$ python test.py
国家 地区 人口 GDP
0 中国 亚洲 13.97 14.34
1 美国 北美 3.28 21.43
2 日本 亚洲 1.26 5.08
可以看到,我们成功生成了一个DataFrame:共有4列数据,国家、地区、人口和GDP;4列数据中国家和地区是文本类型,人口和GDP是数字;共3行数据,系统为我们自动加了索引0、1、2。
从DataFrame中选取一列就会返回一个Series,当然选择多列的话依然是DataFrame。
print(df['人口'])
----------------------------------------------
0 13.97
1 3.28
2 1.26
Name: 人口, dtype: float64
-----------------------------------------------
如下单独创建一个Series:
s = pd.Series([14.34,21.43,5.08],name='gdp')
print(s)
-----------------------------------
0 14.34
1 21.43
2 5.08
Name: gdp, dtype: float64
-----------------------------------
print(type(s))
print(type(df))
-----------------------------------
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
-----------------------------------
DataFrame可以容纳Series,所以在定义DataFrame时可以使用Series,也可以利用NumPy的方法:
df2 = pd.DataFrame(
{
'A': 1,
'B': pd.Timestamp('20210101'),
'C': pd.Series(1, index=range(4), dtype='float32'),
'D': np.array([np.random.randint(1, 100) for i in range(4)], dtype='int32'),
}
)
print(df2)
A B C D
0 1 2021-01-01 1.0 63
1 1 2021-01-01 1.0 24
2 1 2021-01-01 1.0 97
3 1 2021-01-01 1.0 54
生成Series
Series是一个带有标签的一维数组,这个数组可以由任何类型数据构成,包括整型、浮点、字符、Python对象等。它的轴标签被称为索引,它是Pandas最基础的数据结构。Series的创建方式如下:
s = pd.Series(data,index=index)
data可以是Python对象、NumPy的ndarray、一个标量(定值,如8)。index是轴上的一个列表,必须与data的长度相同,如果没有指定,则自动从0开始,表示为[0, …, len(data)–1]。
(1)使用列表和元组
列表和元组可以直接放入pd.Series():
print(pd.Series(['a','b','c','d']))
print(pd.Series(('a','b','c','d')))
(2)使用ndarray如下使用NumPy的ndarray结构:
# 制定索引
s1 = pd.Series(np.random.randn(4), index=['a', 'b', 'c', 'd'])
print(s1)
# 未指定索引
s2 = pd.Series(np.random.randn(4))
print(s2)
a 0.237744
b -0.146819
c 0.945005
d 0.265292
dtype: float64
0 -0.679935
1 1.256414
2 -0.557338
3 -0.809749
dtype: float64
(3)使用字典
如下使用Python的字典数据:
d = {'name': 'ZJ', 'age': 18, 'gender': 'M'}
s3 = pd.Series(d)
print(s3)
----------------------------------------------
name ZJ
age 18
gender M
dtype: object
------------------------------------------------
# 指定索引要与字典的Key一致,否则显示缺失值
s4 = pd.Series(d,index=['name','age','gender','address'])
print(s4)
-------------------------------------------------
name ZJ
age 18
gender M
address NaN
dtype: object
(4)使用标量对于一个具体的值,如果不指定索引,则其长度为1;如果指定索引,则其长度为索引的数量,每个索引的值都是它。
print(pd.Series(1024))
----------------------------------------------------
0 1024
dtype: int64
----------------------------------------------------
print(pd.Series(1024, index=['a', 'b', 'c', 'd']))
----------------------------------------------------
a 1024
b 1024
c 1024
d 1024
dtype: int64
生成DataFrame
DataFrame是二维数据结构,数据以行和列的形式排列,表达一定的数据意义。DataFrame的形式类似于CSV、Excel和SQL的结果表,有多个数据列,由多个Series组成。DataFrame最基本的定义格式如下:
df = pd.DataFrame(data,index,columns)
以下是其各参数的说明。
data:具体数据,结构化或同构的ndarray、可迭代对象、字典或DataFrame。
index:索引,类似数组的对象,支持解包,如果没有指定,会自动生成RangeIndex (0, 1, 2, …, n)。
columns:列索引、表头,如果没有指定,会自动生成RangeIndex (0, 1, 2, …, n)。
此外还可以用dtype指定数据类型,如果未指定,系统会自动推断。大多数情况下,我们是从数据文件(如CSV、Excel)中取得数据,不过,了解这部分知识可以让我们更好地理解DataFrame的数据机制。
(1) 字典
字典中的键为列名,值一般为一个列表或者元组,是具体数据。示例如下。
df = pd.DataFrame({
'国家':['中国','美国','日本'],
'地区':['亚洲','北美','亚洲'],
'人口':[13.97, 3.28, 1.26],
'GDP':[14.34, 21.43, 5.08]
})
print(df)
----------------------------------------------------
国家 地区 人口 GDP
0 中国 亚洲 13.97 14.34
1 美国 北美 3.28 21.43
2 日本 亚洲 1.26 5.08
----------------------------------------------------
如果生成时指定了索引名称,会使用指定的索引名,如a、b、c。示例如下。
df = pd.DataFrame({
'国家': ['中国', '美国', '日本'],
'地区': ['亚洲', '北美', '亚洲'],
'人口': [13.97, 3.28, 1.26],
'GDP': [14.34, 21.43, 5.08]
},index=['a','b','c'])
print(df)
----------------------------------------------------
国家 地区 人口 GDP
a 中国 亚洲 13.97 14.34
b 美国 北美 3.28 21.43
c 日本 亚洲 1.26 5.08
----------------------------------------------------
(2) Series组成的字典
这是一种非常典型的构造数据的方法,字典里的一个键值对为一列数据,键为列名,值是一个Series。示例如下。
s1 = pd.Series(np.random.randn(4))
s2 = pd.Series(np.random.randn(4))
df = pd.DataFrame(
{
'x': s1,
'y': s2
}
)
print(df)
----------------------------------------------------
x y
0 -0.346456 1.135325
1 0.767252 -0.857584
2 -0.426211 -1.629085
3 1.015189 0.778294
----------------------------------------------------
# 一个Series会生成只有一列的DataFrame,示例如下。
s1 = pd.Series(np.random.randn(4))
df = pd.DataFrame(data=s1)
print(df)
----------------------------------------------------
0
0 -0.213681
1 -0.053167
2 1.088160
3 0.505629
----------------------------------------------------
(3) 字典组成的列表
由字典组成一个列表,每个字典是一行数据,指定索引后会使用指定的索引。示例如下。
data = [{'x': 1, 'y': 2}, {'x': 3, 'y': 4, 'z': 5}]
print(pd.DataFrame(data))
----------------------------------------------------
x y z
0 1 2 NaN
1 3 4 5.0
----------------------------------------------------
Pandas的DataFrame和Series结构数据的生成,是后面编写数据分析代码的基础。在实际业务中一般不需要我们来生成数据,而是有已经采集好的数据集,直接加载到DataFrame即可。
Pandas的数据类型
Pandas数据类型是指某一列里所有数据的共性,如果全是数字,那么就是数字型;如果其中有一个不是数据,那么就不是数字型了。Pandas也有自己特有的数据类型。
数据类型查看
pip install openpyxl
import pandas as pd
df = pd.read_excel(r'D:\pythonCode\PandasDemo\team.xlsx')
print(df)
print(df.dtypes)
----------------------------------------------------
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
.. ... ... .. .. .. ..
95 Gabriel C 48 59 87 74
96 Austin7 C 21 31 30 43
97 Lincoln4 C 98 93 1 20
98 Eli E 11 74 58 91
99 Ben E 21 43 41 74
[100 rows x 6 columns]
name object
team object
Q1 int64
Q2 int64
Q3 int64
Q4 int64
dtype: object
可以看到,name和team列为object,其他列都是int64。如下查看具体字段的类型:
print(df.name.dtype)
print(df.team.dtype)
object
object
df.name和df.team是Series,所以要使用.dtype而不是.dtypes。
常见数据类型
Pandas提供了以下常见的数据类型,默认的数据类型是int64和float64,文字类型是object。
float
int
bool
datetime64[ns]
datetime64[ns,tz]
timedelta64[ns]
timedelta[ns]
category
object
string
这些数据类型大多继承自NumPy的相应数据类型,Pandas提供了可以进行有限的数据类型转换的方法
数据检测
可以使用类型判断方法检测数据的类型是否与该方法中指定的类型一致,如果一致,则返回True,注意传入的是一个Series:
pd.api.types.is_bool_dtype(s)
pd.api.types.is_categorical_dtype(s)
pd.api.types.is_datetime64_any_dtype(s)
pd.api.types.is_datetime64_ns_dtype(s)
pd.api.types.is_datetime64_dtype(s)
pd.api.types.is_float_dtype(s)
pd.api.types.is_int64_dtype(s)
pd.api.types.is_numeric_dtype(s)
pd.api.types.is_object_dtype(s)
pd.api.types.is_string_dtype(s)
pd.api.types.is_timedelta64_dtype(s)
接下来,我们将正式进入Pandas数据分析之旅。
from pandas import Series
s = Series(data=[1,2,3,'four'])
s
0 1
1 2
2 3
3 four
dtype: object
import numpy as np
s = Series(data=np.random.randint(0,100,size=(3,)))
s
0 3
1 43
2 82
dtype: int64
#index用来指定显示索引
s = Series(data=[1,2,3,'four'],index=['a','b','c','d'])
s
a 1
b 2
c 3
d four
dtype: object
#为什么需要有显示索引
# 显示索引可以增强Series的可读性
dic = {
'语文':100,
'数学':99,
'理综':250
}
s = Series(data=dic)
s
语文 100
数学 99
理综 250
dtype: int64
- Series的索引和切片
s[0]
s.语文
s[0:2]
语文 100
数学 99
dtype: int64
- Series的常用属性
- shape
- size
- index
- values
s.shape
s.size
s.index #返回索引
s.values #返回值
s.dtype #元素的类型
dtype('int64')
s = Series(data=[1,2,3,'four'],index=['a','b','c','d'])
s.dtype #数据类型O表示的是Object(字符串类型)
dtype('O')
- Series的常用方法
- head(),tail()
- unique()
- isnull(),notnull()
- add() sub() mul() div()
s = Series(data=np.random.randint(60,100,size=(10,)))
s.head(3) #显示前n个数据
0 99
1 99
2 88
dtype: int64
s.tail(3) #显示后n个元素
7 85
8 70
9 76
dtype: int64
s.unique() #去重
array([99, 88, 74, 72, 80, 63, 85, 70, 76])
s.isnull() #用于判断每一个元素是否为空,为空返回True,否则返回False
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
dtype: bool
s.notnull()
0 True
1 True
2 True
3 True
4 True
5 True
6 True
7 True
8 True
9 True
dtype: bool
- Series的算术运算
- 法则:索引一致的元素进行算数运算否则补空
s1 = Series(data=[1,2,3],index=['a','b','c'])
s2 = Series(data=[1,2,3],index=['a','d','c'])
s = s1 + s2
s
a 2.0
b NaN
c 6.0
d NaN
dtype: float64
s.isnull()
a False
b True
c False
d True
dtype: bool
DataFrame
from pandas import DataFrame
df = DataFrame(data=[[1,2,3],[4,5,6]])
df
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
df = DataFrame(data=np.random.randint(0,100,size=(6,4)))
df
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 93 | 61 | 7 | 1 |
| 1 | 89 | 41 | 29 | 16 |
| 2 | 21 | 66 | 97 | 24 |
| 3 | 56 | 96 | 13 | 87 |
| 4 | 86 | 21 | 20 | 54 |
| 5 | 19 | 18 | 96 | 7 |
dic = {
'name':['zhangsan','lisi','wanglaowu'],
'salary':[1000,2000,3000]
}
df = DataFrame(data=dic,index=['a','b','c'])
df
| name | salary | |
|---|---|---|
| a | zhangsan | 1000 |
| b | lisi | 2000 |
| c | wanglaowu | 3000 |
- DataFrame的属性
- values、columns、index、shape
df.values
df.columns
df.index
df.shape
(3, 2)
============================================
练习4:
根据以下考试成绩表,创建一个DataFrame,命名为df:
张三 李四
语文 150 0
数学 150 0
英语 150 0
理综 300 0
============================================
dic = {
'张三':[150,150,150,150],
'李四':[0,0,0,0]
}
df = DataFrame(data=dic,index=['语文','数学','英语','理综'])
df
| 张三 | 李四 | |
|---|---|---|
| 语文 | 150 | 0 |
| 数学 | 150 | 0 |
| 英语 | 150 | 0 |
| 理综 | 150 | 0 |
- DataFrame索引操作
- 对行进行索引
- 队列进行索引
- 对元素进行索引
df = DataFrame(data=np.random.randint(60,100,size=(8,4)),columns=['a','b','c','d'])
df
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 95 | 87 | 83 | 68 |
| 1 | 76 | 82 | 78 | 95 |
| 2 | 69 | 94 | 89 | 72 |
| 3 | 74 | 77 | 93 | 82 |
| 4 | 75 | 88 | 93 | 64 |
| 5 | 67 | 98 | 66 | 85 |
| 6 | 95 | 83 | 71 | 61 |
| 7 | 72 | 74 | 79 | 82 |
df['a'] #取单列,如果df有显示的索引,通过索引机制去行或者列的时候只可以使用显示索引
0 95
1 76
2 69
3 74
4 75
5 67
6 95
7 72
Name: a, dtype: int64
df[['a','c']] #取多列
| a | c | |
|---|---|---|
| 0 | 95 | 83 |
| 1 | 76 | 78 |
| 2 | 69 | 89 |
| 3 | 74 | 93 |
| 4 | 75 | 93 |
| 5 | 67 | 66 |
| 6 | 95 | 71 |
| 7 | 72 | 79 |
- iloc:
- 通过隐式索引取行
- loc:
- 通过显示索引取行
#取单行
df.loc[0]
a 95
b 87
c 83
d 68
Name: 0, dtype: int64
#取多行
df.iloc[[0,3,5]]
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 95 | 87 | 83 | 68 |
| 3 | 74 | 77 | 93 | 82 |
| 5 | 67 | 98 | 66 | 85 |
#取单个元素
df.iloc[0,2]
df.loc[0,'a']
95
#取多个元素
df.iloc[[1,3,5],2]
1 78
3 93
5 66
Name: c, dtype: int64
- DataFrame的切片操作
- 对行进行切片
- 对列进行切片
#切行
df[0:2]
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 95 | 87 | 83 | 68 |
| 1 | 76 | 82 | 78 | 95 |
#切列
df.iloc[:,0:2]
| a | b | |
|---|---|---|
| 0 | 95 | 87 |
| 1 | 76 | 82 |
| 2 | 69 | 94 |
| 3 | 74 | 77 |
| 4 | 75 | 88 |
| 5 | 67 | 98 |
| 6 | 95 | 83 |
| 7 | 72 | 74 |
-
df索引和切片操作
- 索引:
- df[col]:取列
- df.loc[index]:取行
- df.iloc[index,col]:取元素
- 切片:
- df[index1:index3]:切行
- df.iloc[:,col1:col3]:切列
- 索引:
-
DataFrame的运算
- 同Series
练习:
-
假设ddd是期中考试成绩,ddd2是期末考试成绩,请自由创建ddd2,并将其与ddd相加,求期中期末平均值。
-
假设张三期中考试数学被发现作弊,要记为0分,如何实现?
-
李四因为举报张三作弊立功,期中考试所有科目加100分,如何实现?
-
后来老师发现有一道题出错了,为了安抚学生情绪,给每位学生每个科目都加10分,如何实现?
dic = {
'张三':[150,150,150,150],
'李四':[0,0,0,0]
}
df = DataFrame(data=dic,index=['语文','数学','英语','理综'])
qizhong = df
qimo = df
(qizhong + qizhong) / 2 #期中期末的平均值
| 张三 | 李四 | |
|---|---|---|
| 语文 | 150 | 0 |
| 数学 | 150 | 0 |
| 英语 | 150 | 0 |
| 理综 | 150 | 0 |
qizhong.loc['数学','张三'] = 0
qizhong #将张三的数学成绩修改为0
| 张三 | 李四 | |
|---|---|---|
| 语文 | 150 | 0 |
| 数学 | 0 | 0 |
| 英语 | 150 | 0 |
| 理综 | 150 | 0 |
#将李四的所有成绩+100
qizhong['李四']+=100
qizhong
| 张三 | 李四 | |
|---|---|---|
| 语文 | 150 | 100 |
| 数学 | 0 | 100 |
| 英语 | 150 | 100 |
| 理综 | 150 | 100 |
qizhong += 10
qizhong #将所有学生的成绩+10
| 张三 | 李四 | |
|---|---|---|
| 语文 | 160 | 110 |
| 数学 | 10 | 110 |
| 英语 | 160 | 110 |
| 理综 | 160 | 110 |
- 时间数据类型的转换
- pd.to_datetime(col)
- 将某一列设置为行索引
- df.set_index()
dic = {
'time':['2010-10-10','2011-11-20','2020-01-10'],
'temp':[33,31,30]
}
df = DataFrame(data=dic)
df
| time | temp | |
|---|---|---|
| 0 | 2010-10-10 | 33 |
| 1 | 2011-11-20 | 31 |
| 2 | 2020-01-10 | 30 |
#查看time列的类型
df['time'].dtype
dtype('O')
import pandas as pd
#将time列的数据类型转换成时间序列类型
df['time'] = pd.to_datetime(df['time'])
df
| time | temp | |
|---|---|---|
| 0 | 2010-10-10 | 33 |
| 1 | 2011-11-20 | 31 |
| 2 | 2020-01-10 | 30 |
df['time']
0 2010-10-10
1 2011-11-20
2 2020-01-10
Name: time, dtype: datetime64[ns]
#将time列作为源数据的行索引
df.set_index('time',inplace=True)
df
| temp | |
|---|---|
| time | |
| 2010-10-10 | 33 |
| 2011-11-20 | 31 |
| 2020-01-10 | 30 |